




- @m0_43432638
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
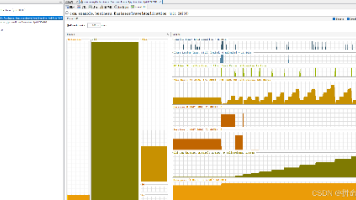
启动该springboot程序并调用该接口,期间可以使用工具对堆内存状态进行监控,发现ed区不断gc,且old区内存不断增高,最终程序oom发生内存溢出。生成后会自动在文件夹生成heapdump.hprof文件结尾的文件,我们通过工具jvisualvm打开左上角打开文件。主要使用jdk自带工具jvisualvm对程序出现oom进行简单的代码问题得到定位和分析。基于现象我们通过设置java的启动并添
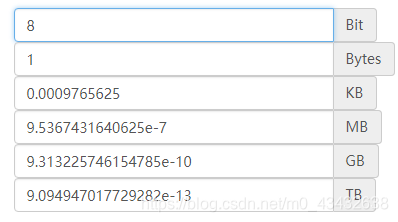
首先我们需要知道何为bits和bytes?bits:名为位数bytes:为字节简单的数就是MB和G的关系!那么8bits=1bytes,下面是各个单位的相互转化!那么float32和float64有什么区别呢?数位的区别一个在内存中占分别32和64个bits,也就是4bytes或8bytes数位越高浮点数的精度越高它会影响深度学习计算效率?float64占用的......
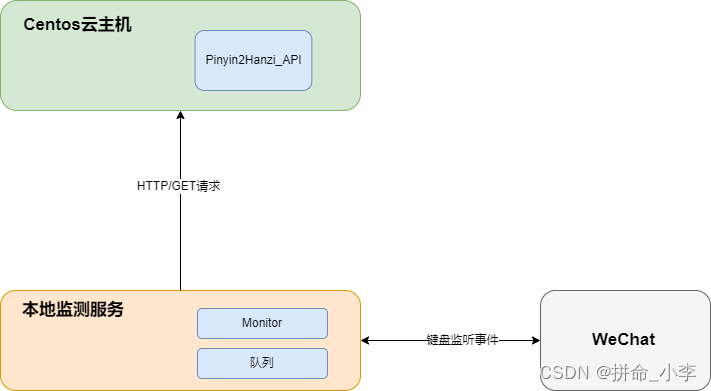
效果1、概要利用深度学习模型Seq2Seq模型搭建拼音转中文模型,利用python键盘监控事件模块PyHook3监控女朋友的发送的拼音数据并发送给模型进行中文预测存储到本地日志中。2、结构使用咱们csdn的Centos云主机搭建,Seq2Seq模型训练一个拼音转中文的model,其实就类似于搜狗输入法的软件,通过键盘监听事件,监听特定的微信的服务窗口,获取你女朋友的聊天输入拼音数据存储到队列中,M
内容简介:1.在我们上节课所讲的一元线性回归的算法所用到的是利用最小二乘法去解决,但是最小二乘法并不适合去处理对多元线性回归进行拟合,我们将会利用矩阵的方式去解决。基础知识:多元线性回归公式线性代数基础:基本概念:在传统的一次方程进行线性拟合时候是左面的图,而当为多项式拟合是则是一条曲线右图所示,针对一元线性回归如果利用矩阵的方式如下:我们设由一元线性公式可得也就是说矩阵A...
使用python实现微博疫情评论数据进行情感分析预测并绘制词云图

效果1、概要利用深度学习模型Seq2Seq模型搭建拼音转中文模型,利用python键盘监控事件模块PyHook3监控女朋友的发送的拼音数据并发送给模型进行中文预测存储到本地日志中。2、结构使用咱们csdn的Centos云主机搭建,Seq2Seq模型训练一个拼音转中文的model,其实就类似于搜狗输入法的软件,通过键盘监听事件,监听特定的微信的服务窗口,获取你女朋友的聊天输入拼音数据存储到队列中,M
首先我们需要知道何为bits和bytes?bits:名为位数bytes:为字节简单的数就是MB和G的关系!那么8bits=1bytes,下面是各个单位的相互转化!那么float32和float64有什么区别呢?数位的区别一个在内存中占分别32和64个bits,也就是4bytes或8bytes数位越高浮点数的精度越高它会影响深度学习计算效率?float64占用的......
出除了基本结构还有常用得类型也需要大家了解一下:Extensions、ASN1OctetString、ASN1Integer、ASN1GeneralizedTime、ASN1BitString规律就是一般都是根据下面得结构属性名称加一个ASN1就是这个类型(但是实际中也是需要自己去试)。下面主要是通过BC库,通过一些GM/T国密标准文档去实现ASN1结构封装得案例,来帮助大家封装ASN1结构代码。

效果1、概要利用深度学习模型Seq2Seq模型搭建拼音转中文模型,利用python键盘监控事件模块PyHook3监控女朋友的发送的拼音数据并发送给模型进行中文预测存储到本地日志中。2、结构使用咱们csdn的Centos云主机搭建,Seq2Seq模型训练一个拼音转中文的model,其实就类似于搜狗输入法的软件,通过键盘监听事件,监听特定的微信的服务窗口,获取你女朋友的聊天输入拼音数据存储到队列中,M
问题来源:本人在进行jpython的jieba分词时,发现在对不高兴,不开心等词汇进行分词时,将其分开下图Prefix dict has been built succesfully.[精确模式]:我 不 喜欢 也 不 高兴[Finished in 1.7s]期望形式:但是我们希望jieba应该分成这种形式,不和高兴是连在一起的来表示消极的程度副词Pref...