




- @m0_37900506
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
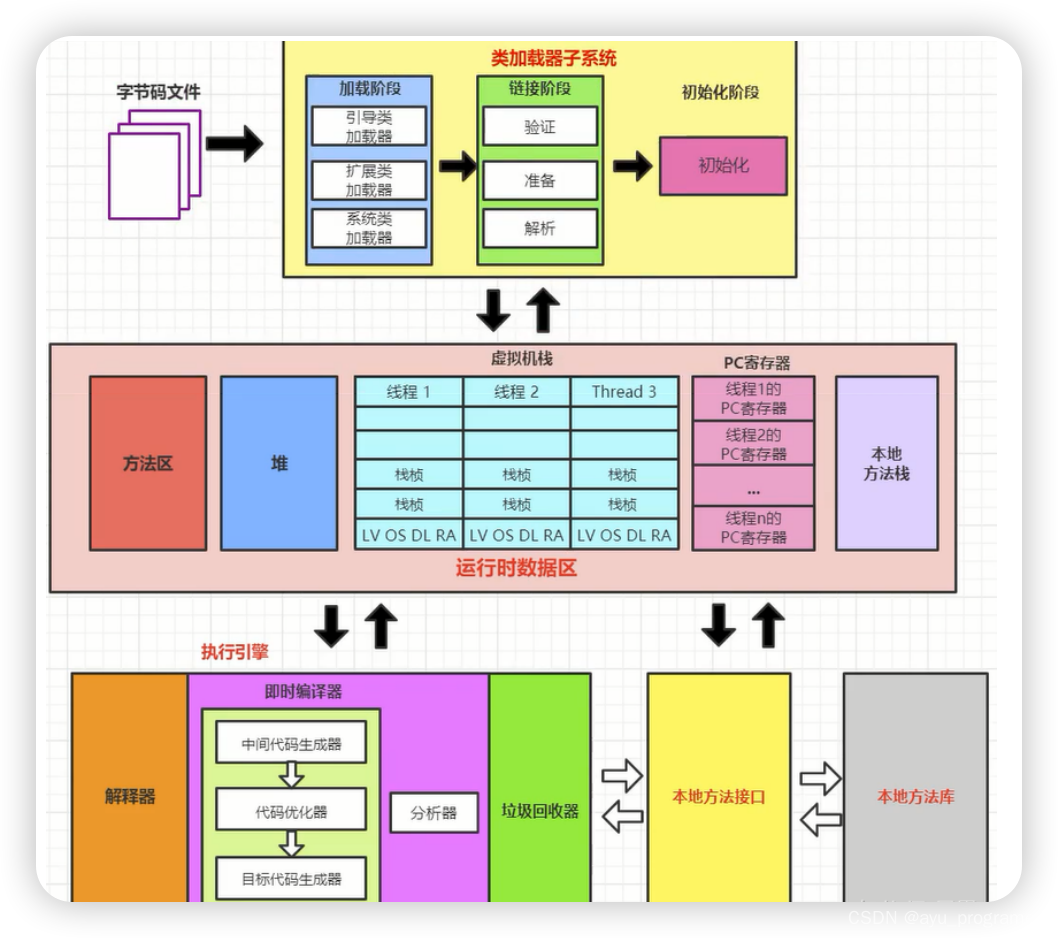
首先在java运行过程中,其实程序员并不需要去显示的调用程序来释放对象的内存,而是由虚拟机来完成的,具体来看是在jvm中有个垃圾回收线程,这个线程是个守护线程,这个线程会在虚拟机空闲或者在当前堆内存不足时,才会触发执行,扫面那些没有被任何引用的对象,并将它们添加到要回收的集合中,进行回收。回收后,已用和未用的内存都各自一边。其实jvm的垃圾回收,在我们一开始创建对象的时候,GC就会去监控这个对象的
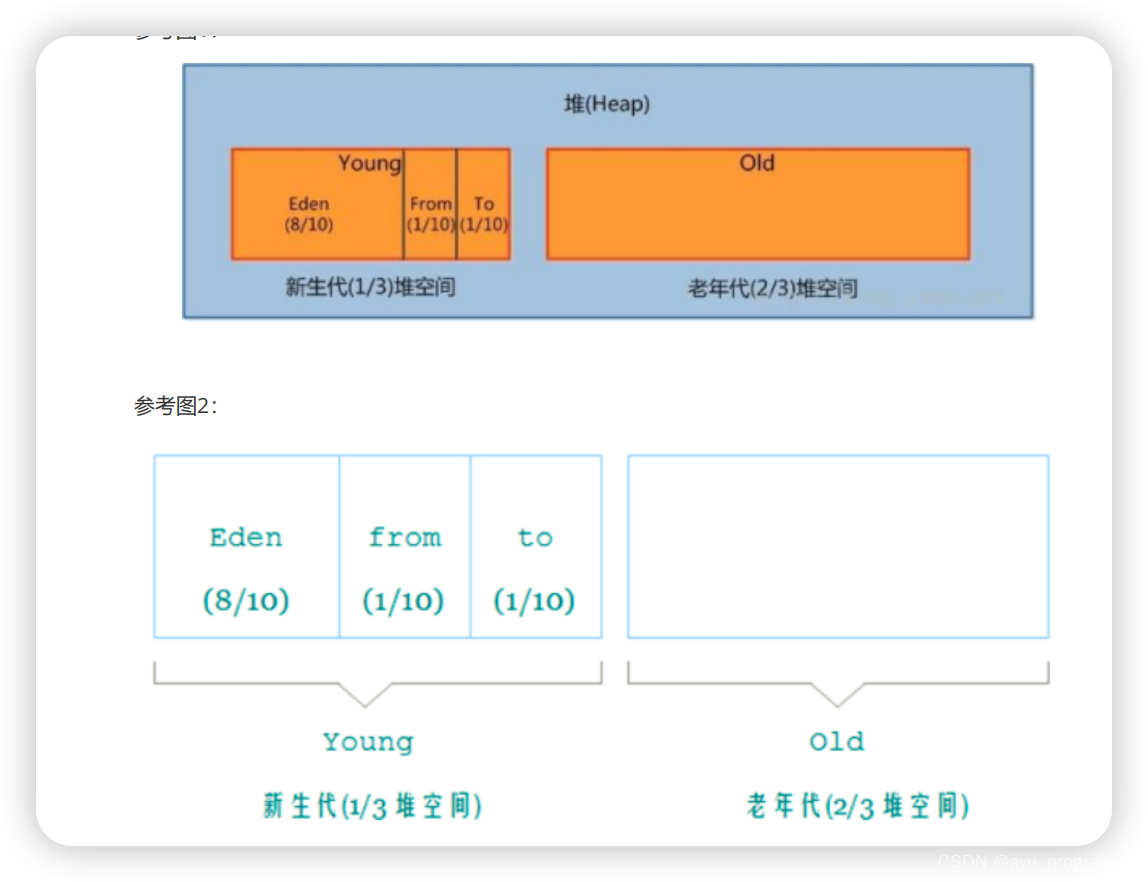
以Hotspot为例,堆内存主要由GC模块进行管理和分配,可以分为新生代和老年代,而新生代又可以分为eden区,s1区和s2区,并且他们的比例默认为8:1:1, 同时新生代和老年代的占比如下图所示在使用堆内内存(on-heap memory)的时候,完全遵守JVM虚拟机的内存管理机制,采用垃圾回收器(GC)统一进行内存管理,
一、压测流程1.申请压力机申请压力机器,每个场景一台windows机器作为控制机,负载机器为linux2.将脚本上传到控制机上脚本示例Action(){lr_start_transaction("demo");web_url("web_url","URL=http://test.stress.api:30900/test/kafka/produce?clusterId=1&sendType
1 安装jdk1.8版本(这里具体安装的版本为 jdk1.8.0_261)2 搭建zookeeper集群(具体选择使用了 10.8.40.160,10.8.40.161,10.8.40.162 3台机器)2.1 下载安装从 https://zookeeper.apache.org/ 下载zookeeper-3.6.3 并分别安装到usr/local目录下2.2 指定jdk版本在 /usr/loca
一 介绍Apache Kafka 官方提供了两个客户端性能测试脚本,它们的存放位置如下:$KAFKA_HOME/bin/kafka-producer-perf-test.sh 支持测试的性能指标包括:吞吐量(throughput)、最大时延(max-latency)、平均时延(avg-latency);kafka-consumer-perf-test.sh 同样支持吞吐量指标,还提供了一些消费端特
01.为什么要用RocketMq?总得来说,RocketMq具有以下几个优势:吞吐量高:单机吞吐量可达十万级可用性高:分布式架构消息可靠性高:经过参数优化配置,消息可以做到0丢失功能支持完善:MQ功能较为完善,还是分布式的,扩展性好支持10亿级别的消息堆积:不会因为堆积导致性能下降源码是java:方便我们查看源码了解它的每个环节的实现逻辑,并针对不同的业务场景进行扩展可靠性高:天生为金融互联网领域
对于SpringBoot项目,我们知道扫描的路径从启动类所在包开始,扫描当前包及其子级包下的所有文件。而如果有多个服务模块,比如有缓存服务模块com.roncoo.eshop.cache.,和产品服务模块 com.roncoo.eshop.product.,如果想要在缓存服务模块中用到产品服务模块的东西,很显然业务服务模块初始化时是扫不到产品服务模块的东西的,这种情况可以通过**@Componen