- @lovely_yoshino
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
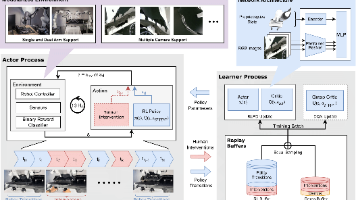
HIL-SERL是一种融合人类干预的机器人强化学习框架,通过人类演示、奖励分类器和在线干预提升训练效率与安全性。其核心流程包括:1)采集人类演示数据并训练奖励分类器;2)采用分布式SAC架构进行在线训练;3)支持人工实时干预保障硬件安全。工程实现上,通过环境配置、工作空间边界设定、数据预处理等步骤确保系统可靠性,并利用Gym Wrapper机制实现观测、动作、奖励的灵活扩展。该框架在复杂操作任务中
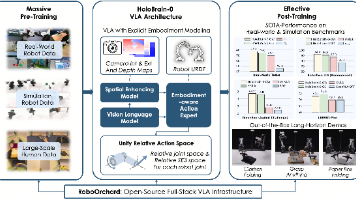
摘要: 2025-2026年,具身智能领域正从模块化架构转向端到端的视觉-语言-动作(VLA)模型。地平线机器人实验室开源的HoloBrain-0框架解决了当前VLA模型的三大痛点:1)通过RoboOrchard基础设施降低数据采集成本;2)引入摄像头参数和运动学先验实现跨本体泛化;3)采用异步推理减少动作延迟。该框架包含0.2B参数的轻量级版本和1.1B参数的高性能版本,通过分层设计(VLM骨干
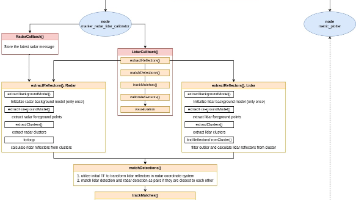
本文介绍了Autoware中的传感器校准工具安装与使用指南。新版CalibrationTools不再依赖Autoware的tf信息,仅需bag数据即可完成标定。系统要求为Ubuntu 22.04和ROS2 Humble。工具分为外部校准(如激光雷达-激光雷达、相机-激光雷达等)和内部校准(相机内参)两大类,各具不同特征类型和校准方式。架构设计上采用校准器节点与传感器校准管理器分离的模式,前者负责具
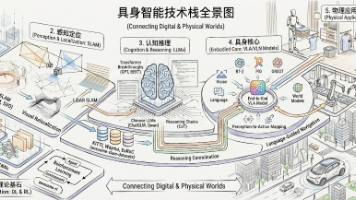
摘要 具身智能(Embodied AI)作为连接数字与物理世界的关键技术,正引领AI从理解世界向改变世界转变。本文基于GitHub优质资源,系统梳理了具身智能技术栈:1)深度学习与强化学习基础(awesome-deep-learning、awesome-rl);2)SLAM与视觉定位(awesome-visual-slam、awesome-slam-datasets等),包括ORB-SLAM、LS
视觉里程计最近几年越来越受到学术界以及工业界的认可,以ORB和VINS为代表的视觉SLAM已经可以满足绝大多数场景,而OV2SLAM在其他VSLAM中脱颖而出,其实时性以及具体的回环性能在测试中都得到了认可。下面我们就来看一下《》这篇文章,当然这么经典的论文也已经开源了,代码在上可以找到。【ICRA2021】3475-OV2SLAM:用于实时应用的完全在线和通用的视觉SLAM。
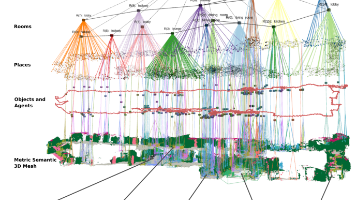
Hydra是一个实时构建分层3D场景图的机器人空间感知系统,旨在解决传统SLAM技术在语义理解和层次化推理方面的不足。该系统通过五层场景图结构(几何网格、物体、场所、房间和建筑)实现环境的高效表示,支持语义查询和路径规划。Hydra采用前端-后端架构,前端增量式构建场景图各层,后端优化全局一致性。其创新之处在于基于广义维诺图的场所层提取方法,以及证明场景图具有小树宽特性,确保高效推理。该系统已在真
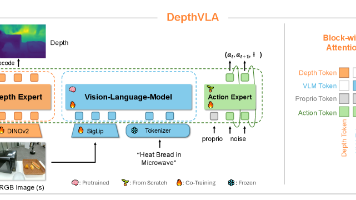
摘要: 清华大学与Galaxea AI团队提出DepthVLA模型,解决视觉-语言-动作(VLA)模型在机器人精确空间推理任务中的性能瓶颈。传统VLA模型依赖语义理解但缺乏几何感知能力,导致精细操作失败。DepthVLA创新性地采用混合Transformer架构,集成视觉-语言、深度预测和动作三个专家模块,通过块级掩码机制平衡模块独立性与信息融合。深度专家基于预训练的Depth Anything
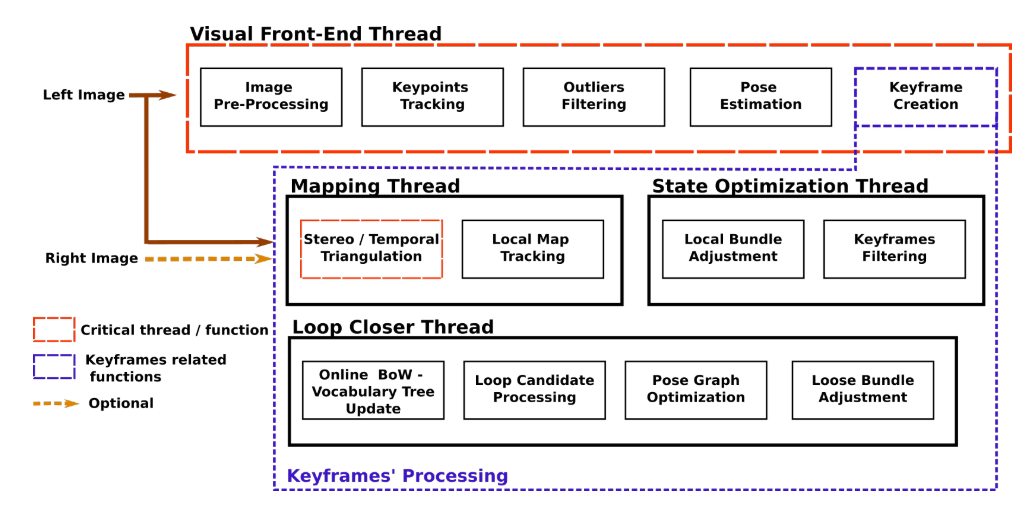
介绍Slam:同步定位与建图,就是在定位的同时,建立环境地图。主要思路是根据运动学模型计算位姿,并通过传感得到的环境信息,对估计位姿调整优化,从而得到准确位姿,根据定位及感知数据绘制地图。下图为slam主流框架:传感器感知在视觉SLAM中主要为传感信息的读取和预处理。前端里程计(Radar/Visual Odometry)。特征点匹配及运动估计。后端优化(Optimization)。后端接受不同时
是一个功能强大的工具集合,可用于开始使用 C++ 来玩和试验 SLAM。这是一项正在进行的工作。它在单个 cmake 框架中安装并提供一些最重要的功能后端框架(g2o、gtsam、ceres、se-sync 等)、前端工具(opencv、pcl等)、代数和几何库(eigen、sophus、cholmod 等),即工具(pangolin、imgui 等)、闭环框架(DBOW3、iBOW 等)、以及一

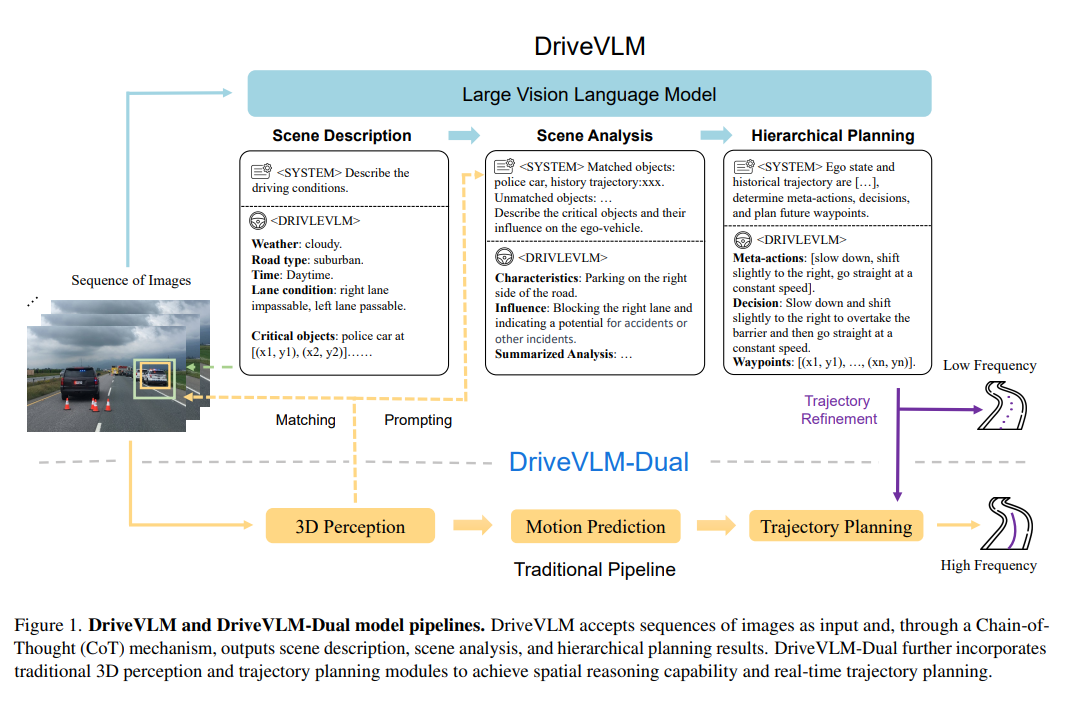
本文介绍了DriveVLM:自动驾驶与大型视觉语言模型的融合。城市环境中自动驾驶的一个主要障碍是理解复杂且长尾的场景,例如具有挑战性的路况和微妙的人类行为。为此,本文引入了DriveVLM,这是一种利用视觉语言模型(VLMs)增强场景理解和规划能力的自动驾驶系统。DriveVLM集成了用于场景描述、场景分析和分层规划的思维链(CoT)模块的独特组合。