




- @litt1e
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
OHEM是CVPR2016的文章,它提出一种通过online hard example mining 算法训练Region-based Object Detectors,其优点:1.对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强。2.当数据集增大,算法可以在原来基础上提升更大。当我们遇到数据集少,且目标检测positive proposal少时,一...
python的opencv安装很简单,通过pip就可以完成,但是c++在安装opencv4的时候需要注意一些。下面给出linux下安装opencv4的步骤。1.安装依赖sudo apt-get install cmakesudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.
安装docker,首先要确保是centos7版本docker安装第一步:Uninstall old versions如果老版本的docker或者docker-engine被安装,我们需要卸载他们,连同与其关联的其他依赖。$ sudo yum remove docker \docker-client \docker-client-latest \docker-common \dock...
首先,利用docker拉去ubuntu16.04的镜像sudo docker pull ubuntu:16.04开启交互式容器sudo docker run -i -t 9499db781771 /bin/bash进入容器并更新安装vimapt-get install vim利用vim换源mv /etc/apt/sources.list /etc/apt/sources.list.backvim
目标检测与图像分类不同,目标检测不仅要对检测出来的目标框正确分类,同时,还需要考虑目标框与target是否贴合。首先我们需要知道几个常见指标:TP (True Positive):iou>0.5的检测框数量。在上图中,绿色的框表示GT,其中cat 0.9的红色框就是TP。FP (False Positive):iou<=0.5的检测框。cat 0.3的红色框与GT的IOU小于0.5所以
安装docker,首先要确保是centos7版本docker安装第一步:Uninstall old versions如果老版本的docker或者docker-engine被安装,我们需要卸载他们,连同与其关联的其他依赖。$ sudo yum remove docker \docker-client \docker-client-latest \docker-common \dock...
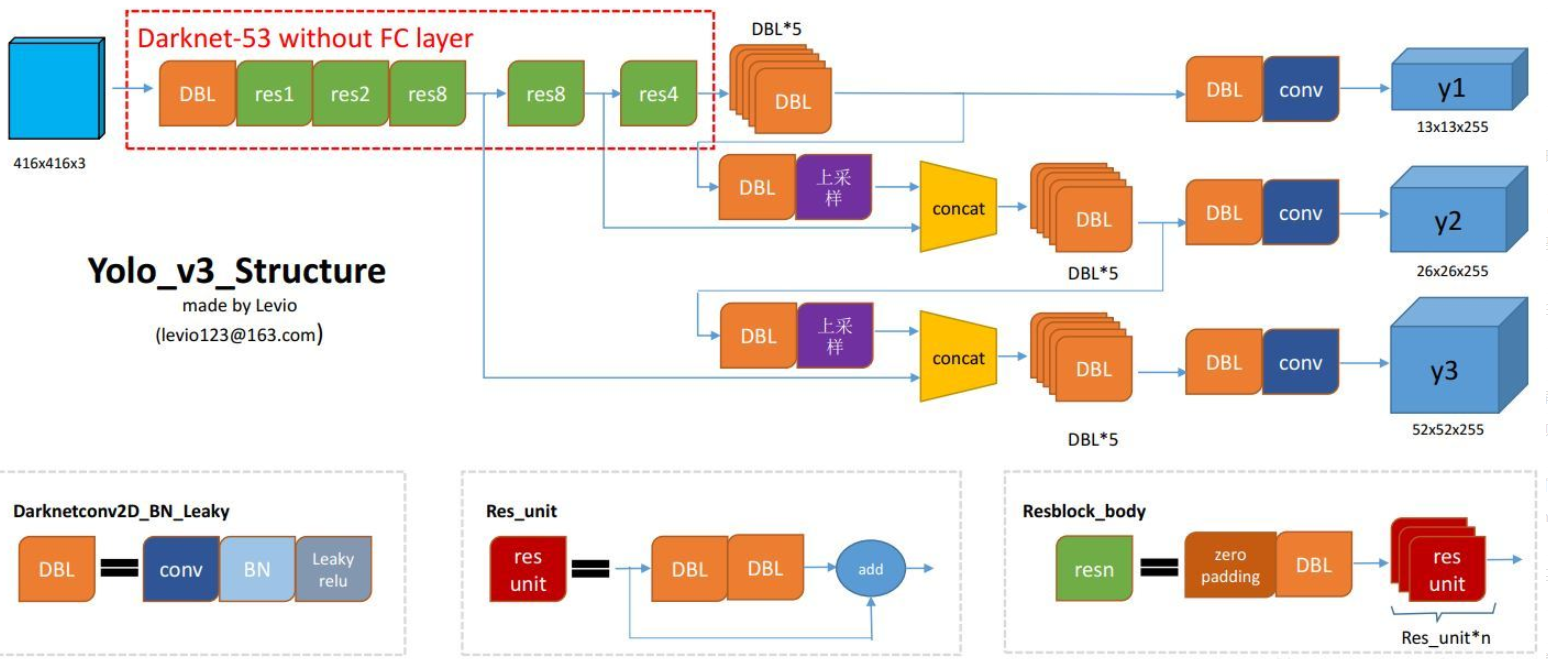
论文地址:https://pjreddie.com/media/files/papers/YOLOv3.pdf论文:YOLOv3: An Incremental ImprovementYOLO系列的目标检测算法可以说是目标检测史上的宏篇巨作,接下来我们来详细介绍一下YOLO v3算法内容,v3的算法是在v1和v2的基础上形成的,所以有必要先回忆: 一文看懂YOLO v2,一文看懂YOLO v2..
目标检测与图像分类不同,目标检测不仅要对检测出来的目标框正确分类,同时,还需要考虑目标框与target是否贴合。首先我们需要知道几个常见指标:TP (True Positive):iou>0.5的检测框数量。在上图中,绿色的框表示GT,其中cat 0.9的红色框就是TP。FP (False Positive):iou<=0.5的检测框。cat 0.3的红色框与GT的IOU小于0.5所以
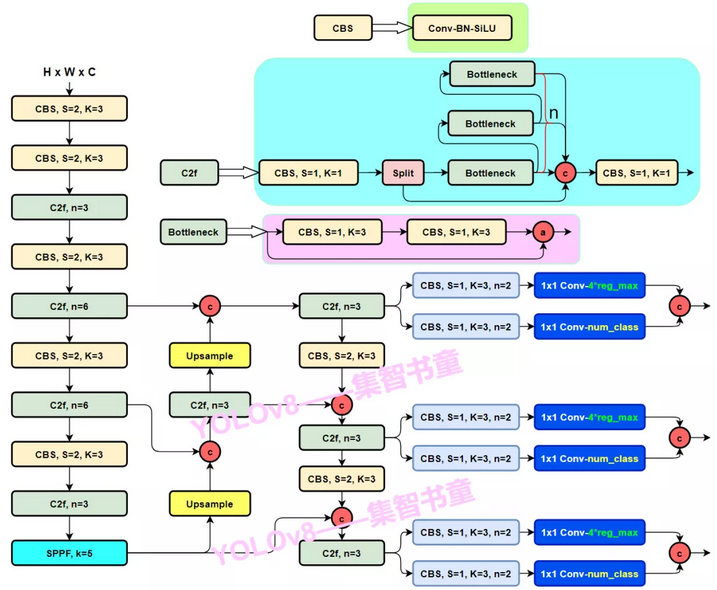
2023年,YOLO系列已经迭代到v8,v8与v5均出自U神,为了方便理解,我们将通过与v5对比来讲解v8。想了解v5的可以参考文章。
我们在分类任务中经常用ROC曲线与AUC来衡量分类器的好坏。在理解之前,我首先介绍一下混淆矩阵。混淆矩阵在二分类问题上,真实类别分为:F:反例;T:正例;预测类别:P:正例;N:反例。真正例TP(true postive):样本真实类别为1,学习模型预测的类别也为1假正例FP(false postive):样本真实类别为0,学习模型预测的类别为1真反例TN(true negative):样本真实类