




- @lihuayong
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
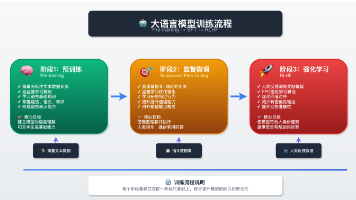
这篇文章介绍下如何从零到一进行预训练工作。
实现一个基于 LangGraph 框架的智能研究助手示例程序,主要功能是构建一个能够回答用户问题的工作流系统。
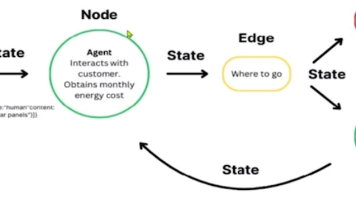
React智能体系统是一个基于**推理+行动(Reasoning + Acting)**模式构建的AI智能体,能够自主分析复杂问题、制定执行计划、智能选择工具并迭代优化解决方案,直至生成高质量的最终答案。

手势识别作为计算机视觉领域的一个重要应用,通过分析图像或视频序列来识别特定的手势动作。下面以0-9手势数字识别为案例,从数据加载、预处理到模型训练的手势识别全流程,基于PyTorch框架构建经典卷积神经网络。

卷积神经网络( CNN)是一种专门设计用于处理图像数据的深度学习模型,是计算机视觉领域的核心技术,从人脸识别到自动驾驶,它的应用无处不在。它在图像识别、分类、目标检测等领域表现出色,通过一系列组件如卷积层、池化层和全连接层等,能够自动从图像中学习有用的特征,而无需手动设计。它是如何从图像中“看见”并理解世界的?本文将解析CNN的核心组件、特征抽取原理,并通过代码展示其强大能力。

**Youtu-GraphRAG** 是一个基于图Schema实现垂直统一的图增强推理范式,将GraphRAG框架精巧地集成为一个以智能体为核心的有机整体。实现了通过在图Schema上的最小化人为干预下进行跨领域的无缝迁移,为业界应用提供了泛化、鲁棒、可用的下一代GraphRAG范式。
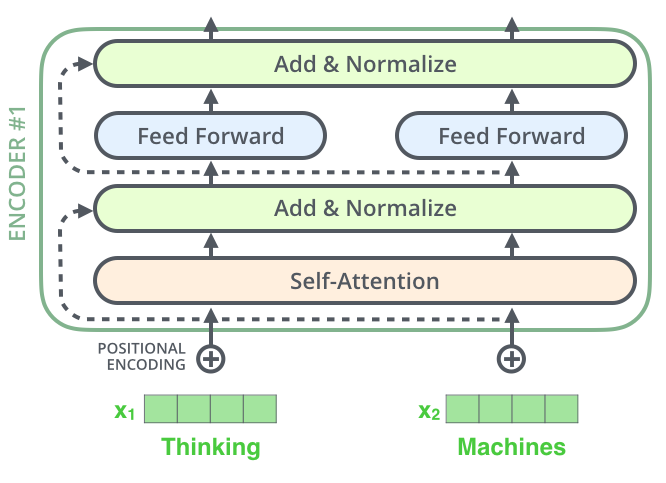
在Transformer模型中,残差连接(Residual Connection)和层归一化(Layer Normalization)是两个关键设计,用于提升模型的训练稳定性和性能。
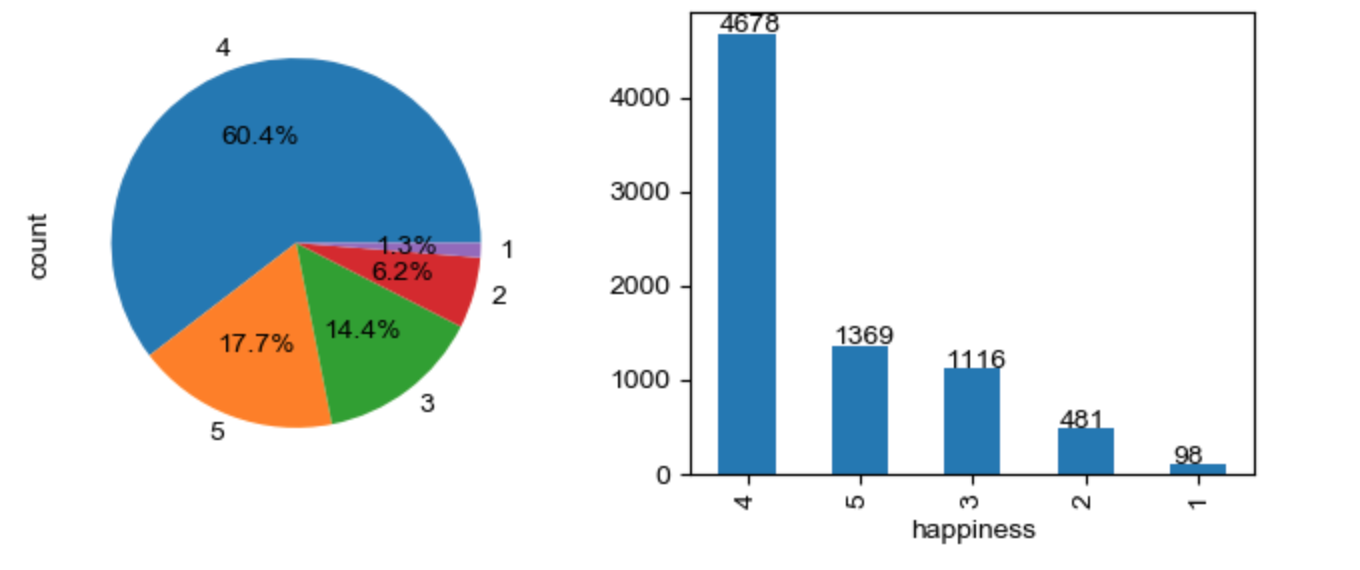
本项目通过幸福感预测这一经典社会科学课题,使用问卷调查所得的公开数据,包括个体变量(性别、年龄、地域、职业、健康、婚姻与政治面貌等等)、家庭变量(父母、配偶、子女、家庭资本等等)、社会态度(公平、信用、公共服务等等)等134 个维度的信息来预测其对幸福感的影响。幸福感happiness 分为1 = 非常不幸福; 2 = 比较不幸福; 3 = 说不上幸福不幸福; 4 = 比较幸福; 5 = 非常幸福
卷积神经网络(Convolutional Neural Network, CNN)是一种专门设计用于处理图像数据的深度学习模型,是计算机视觉领域的核心技术,从人脸识别到自动驾驶,它的应用无处不在。它在图像识别、分类、目标检测等领域表现出色,通过一系列组件如卷积层、池化层和全连接层等,能够自动从图像中学习有用的特征,而无需手动设计。它是如何从图像中“看见”并理解世界的?本文将解析CNN的核心组件、特

OpenClaw Gateway流量抓包指南 本文介绍如何使用mitmproxy抓取OpenClaw Gateway的LLM API请求流量。主要步骤包括: 启动mitmproxy(透明模式或Web界面模式) 配置系统代理(临时或永久) 处理HTTPS证书信任问题(关键步骤) 重启OpenClaw服务 测试抓包效果 重点注意事项: 必须配置Node.js信任mitmproxy的CA证书 可过滤特定
