




- @lansebingxuan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
NLP算法会使用不同的分词方法表示所有单词,确定分词方法之后,首先建立一个词表,词表的维度是词总数vocab_size ×表示每个词向量维度d_model(论文中dmodel默认值512),这是一个非常稀疏的矩阵。由两个线性层组成,W1维度是(dmodel,4×dmodel),b1维度是4×dmodel,W2维度是(4×dmodel,dmodel),b2维度是dmodel,参数量为 dmodel×

使用gtest和lcov测试代码覆盖率
假设Transformer的输入每个词向量维度d_model(d) ,词表大小为vocab_size(v),输入句子最大长度为src_max_len(s),batchsize为 batch(b),head头数为head(h)。矩阵乘法的输入形状[b, h, s, d] × [b, h, s, d],输出形状为 [b, h, s, s],h维度是concat,没有计算量,因此该步骤的计算量为。矩阵乘

本文介绍config文件中的参数配置,如何设置能够提升GPU的利用率,提高模型吞吐
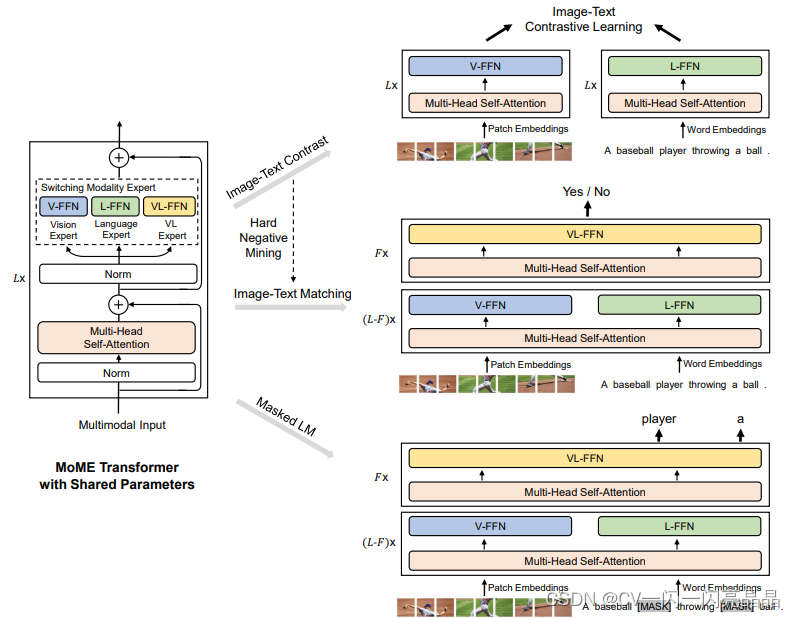
4. 多模态的训练数据集不够多,但是在单模态里,就是视觉或者NLP里,可用的数据很多,基于这个研究动机,VLMo的作者提出了stagewise pre-training strategy,就是分阶段去训练,先把vision expert在视觉数据集这边训好,再把language expert在language的数据集上训好,这个时候模型本身的参数非常好的被初始化了,再到多模态的数据上做pre-tr
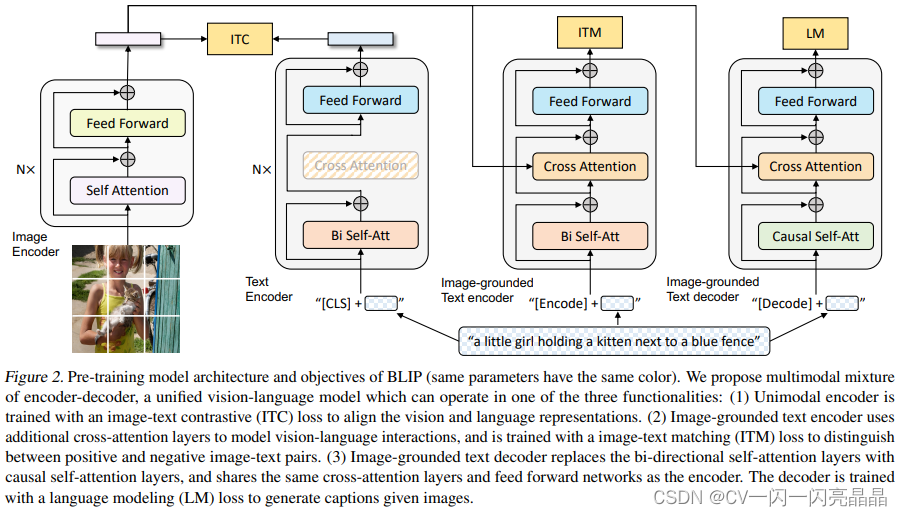
所以作者用生成的文本充当新的训练数据集,具体的,作者在coco数据集上把已经训练好的image grounded text decoder又微调了一下,得到了captioner,然后给定任意一张从网上爬下的图片,用这个captioner给这个图片生成新的字幕,也就是红色这里的ts,经过filter筛选后,添加到数据集中,它是synthetic data。(Ih,Th)是手工标注的Coco数据集。这
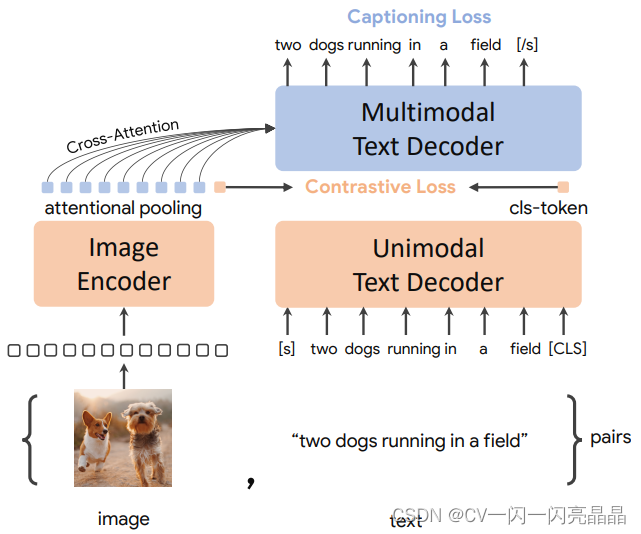
CoCa代表Contrastive Captioners的缩写,代表模型用两个目标函数训练出来的,一个是Contrastive Loss,一个是Captioning Loss。本文因为数据集更大,模型也更大,所以它的效果很好,在多模态所有的任务均SOTA,而且在单模态里,在ImageNet上也得到了90以上的Top1准确度,在视频动作识别领域,在Paper with Code上CoCa在K400、
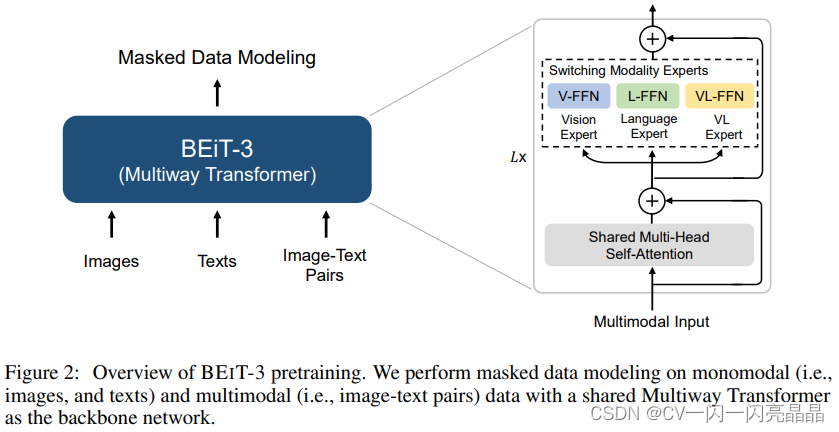
BEITv3其实从方法上来说就是之前BEIT、BEITv2、VLBEIT、VLMO等一系列的工作的一个集合体,本身没有提出新的内容,主要就是把它做大做强,展示了一个Unified Framework能达到的性能。BEiTv3的目标非常明确,就是想做一个更大一统的框架,不论是从模型上统一,而且从训练的目标函数上要统一,还有模型大小,数据集大小,如何scale也要统一,作者称之为Big Converg
最近图像文本的大规模的特征学习非常火爆,大部分已有的方法都是用一个Transformer模型作为多模态的一个编码器,同时编码视觉的Token和文本的Token,视觉Token就是视觉特征,一般是region-based的图像特征。

scp(secure copy)是一个基于 SSH 协议在网络之间进行安全传输的命令,本文介绍传输的常用配置和实际例子