- @jike007gt
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
AI驱动的代理式DBA的崛起,代表着企业技术领域的又一决定性时刻。它不仅能在更短时间内完成相同任务,更将重新定义一切可能。我亲身经历了这段旅程,从传统DBA工作到在实际环境中部署智能体。我可以自信地说,数据基础设施的未来将告别手动、被动和脆弱性,全面迎接自我优化、自我修复与设计层面可靠性的新时代。这是一个人类创造力与机器精度相结合的新阶段。请各位DBA不必担心,这绝非职业发展的终点,而是又一激动人
Kimi-K2采用了MuonClip优化器,这是在Muon优化器基础上改进而来的,通过qk-clip技术解决了训练中注意力logits爆炸的问题,确保了大规模LLM训练的稳定性,在15.5Ttoken上完成了预训练,且过程中没有出现训练峰值。根据月之暗面公布的测试数据显示,Kimi-K2在SWE-bench的单次测试中达到了65.8分,碾压了DeepSeek最新开源的V3-0324模型38.8分,
数据分析的未来,不是让每个人都学会写SQL,而是让每个人都能用自然语言表达自己的数据需求。这个趋势已经不可逆转。那些还在坚持"数据分析是专业技能"的企业,就像当年坚持"只有专业打字员才能用电脑"的企业一样,注定会被时代抛弃。而那些率先拥抱这个变化的企业,将在数据驱动的商业竞争中占据先机。AI Agents+大模型+RAG的架构,不只是技术的进步,也是思维方式的革命**。它让数据真正成为每个人的武器
昨天,OpenAI在凌晨正式推出了全新的“ChatGPT Agent”,这一产品整合了此前的Operator和DeepResearch两大系统。昨天,OpenAI在凌晨正式推出了全新的“ChatGPT Agent”,这一产品整合了此前的Operator和DeepResearch两大系统。图片Operator善于网页互动,能像人一样浏览网站、点击按钮、填写表单,但它读文章太慢,需要慢慢滚动。Deep
虽然今年Gemini完全依赖自然语言完成任务,但DeepMind明确表示,这两条路线仍会并行推进。他们的目标,是构建一个既能理解人类语言,又能进行严格形式证明的“超级数学助手”。Gemini Deep Think正式跨入国际数学奥林匹克(IMO)金牌行列。谷歌DeepMind宣布,其搭载Deep Think模式的先进版本Gemini,在2025年IMO中斩获35分,成功达到了金牌标准。这一成绩来自
又是一个不眠夜!7 月对于 OpenAI 而言意义非凡,从去年盛传 GPT-5 将会发布,再到近日的被挖角风波,再到 OpenAI 即将推出 AI 浏览器,各种传言全都酝酿在今天凌晨的直播里。发布前,小编的预期是,肯定是 Agentic 办公类的产品。因为在前两个月的博客中,Sam Altman 不止一次提及,现在是 Vibe Coding,下一个则看好类似 Google Docs 的办公 Age
从表面上看,MCP与A2A似乎高度重合,采用类似的客户端-服务器架构,使用大量相同的底层消息传递与传输协议,而且同样在相对不太成熟的情况下获得了业界的大力支持。在了解了彼此之后,智能体间即可互发任务,其中一个智能体充当客户端、另一智能体充当服务器。但实际上,MCP与A2A打算解决的问题截然不同,由它们引发的误解大多源自AI智能体在定义上的模糊不清。就协议而言,A2A并不关心智能体是否使用MCP来实
一.工程解读生成Readme.mdJAVACSharpVue.js在craft模式下@workspace 详细分析代码工程结构<think>我们有一个代码工程,需要详细分析其结构。根据提供的文件结构、代码片段和配置文件,我们可以逐步分析。
是一项开放标准,简化了AI模型(特别是大语言模型LLMs)与外部数据源、工具和服务之间的交互方式。MCP服务器充当这些AI模型与外部工具之间的桥梁。允许大语言模型直接访问本地文件系统,进行读取、写入和创建目录等操作。将Claude连接到GitHub仓库,支持文件更新和代码搜索功能。用于Slack API的MCP服务器,使Claude能够与Slack工作区进行交互。用于Google Maps API
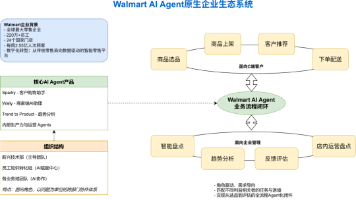
当前,AI Agent的典型应用领域包括:智能零售、自动驾驶、智慧医疗、AI教育、情感陪伴以及网络安全等。这些领域具备高人机交互密度、实时决策需求与复杂任务拆解特性,天然适合引入Agent机制实现自动化与智能化升级。根据当前企业AI Agent创新应用的调研,不同行业在大模型与AI Agent技术的落地节奏上呈现出显著差异。整体来看,AI Agent的快速部署主要集中在以AI为驱动的新兴企业与新兴