




- @jclian91
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
MySQL数据库的可视化工具有很多,比如MySQL Workbench,Navicat,DBeaver等,那么如何利用PyCharm进行MySQL数据库可视化操作? 首先我们需要在PyCharm安装MySQL数据库的可视化插件,...
Python爬虫——解决urlretrieve下载不完整问题且避免用时过长
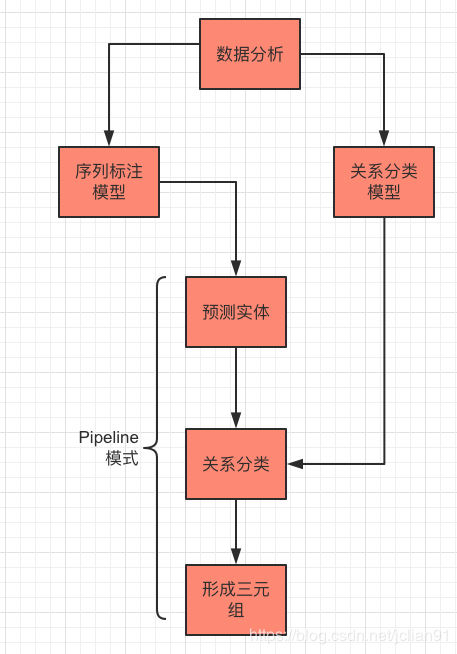
本文将会介绍在大模型(LLM)时代下,如何在开放领域进行三元组抽取。本文内容已开源至Github,网址为:https://github.com/percent4/llm_open_triplet_extraction .
在我们平时使用PyCharm的过程中,一般都是连接本地的Python环境进行开发,但是如果是离线的环境呢?这样就不好搭建Python开发环境,因为第三方模块的依赖复杂,不好通过离线安装包的方式安装。本文将介绍如何利用PyCharm来连接Docker镜像,从而搭建Python开发环境。 首先,我们需要准备一下工具:PyCharm专业版Docker我们用一个示例项目来演示在PyCha...
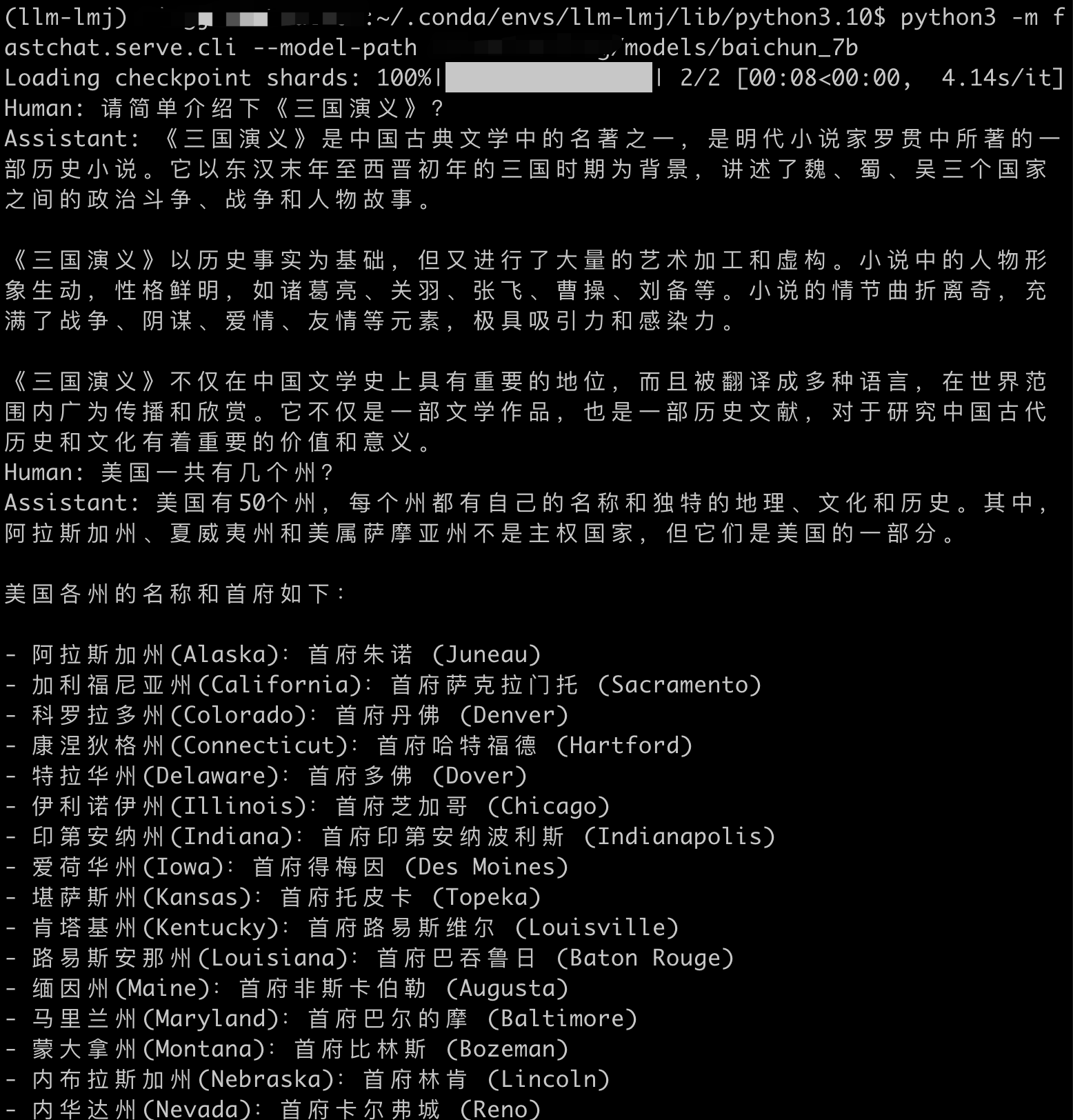
本文将会介绍如何使用FastChat来部署国产大模型——百川模型。
在本文中,笔者将介绍如何使用抽取式NLP模型来实现词义消歧(WSD),模型灵感来源于论文ExtEnD: Extractive Entity Disambiguation
本文将会介绍如何在PyTorch中使用CNN模型进行中文文本分类。

在我们的日常生活中,所碰到的图像往往都有一定的倾斜。那么,如何用OpenCV来获取图像的旋转角度呢? 我们以下面的图片为例,简单介绍如何用OpenCV来获取图像的旋转角度。 可以看到,该图像存在着许多噪声,且是彩色图片,因此,需要对图像做预处理。预处理 图像的预处理包括去除边缘,去除噪声(两条灰色线),滤波,二值化等,具体处理的Python代码如下:# -*- coding:...
本文篇幅较长,主要介绍了知识蒸馏的基本概念和原理,并通过笔者自己的亲身试验,验证了知识蒸馏的有效性,在稍微降低模型效果的前提下,模型的推理速度获得了极大提升。

简介 笔者最近在从事文本纠错的相关工作,颇有收获,因此记录于此。 文本纠错很大一部分工作在于纠正同音字、形近字,所谓形近字,是指字形相近的汉字。本文将介绍如何获取形近字。 获取形近字的算法如下:获取汉字库,将所有汉字转化为黑白图片;获取每个汉字的向量表示(即将图片转化为向量);计算两个汉字的向量的余弦相似度,得到它们的字形相似度。 下面将详细演示如何获取形近字。获取形近字 我们从网上得到
