- @itlodge
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Flink Native Kubernetes 部署:Flink 直接调用 Kubernetes API,按需动态创建 JobManager 和 TaskManager Pod,实现流处理任务的云原生自动化管理。简单说:Flink 变成了 Kubernetes 的" Citizens",而不是 Kubernetes 里的"租客"。

除了系统自动生成技能,Hermes 也支持手动创建、编辑技能,使用者可以根据业务需求定制专属执行规则,进一步强化工具能力。框架沿用通用的技能标准,技能文件以 Markdown 格式编写,上手门槛极低,所有自定义技能统一存放在目录下。# 新建自定义技能文件 touch ~/.hermes/skills/git-commit-style.md打开文件写入规则内容,一份完整的技能文档可以包含标题、触发条

最近看了Hermes Agent的文档,它的设计思路确实有点不一样。不是那种堆功能的框架,而是内部有一套让AI自己改进的逻辑。这篇聊聊学习循环、三层记忆、Skill系统和工具集成这几个方面。

这两年看 AI Agent 工具,会有一个挺明显的感觉:大家都在往同一个方向加东西。多工具调用、多模型路由、多智能体协作、自动化工作流……每一项单独看都合理,甚至必要,但组合在一起之后,体验并没有线性变好。很多系统在某个 demo 里看起来很完整,但一旦放进真实使用环境,就会开始暴露一些老问题,比如行为不稳定、上下文漂移、或者“看起来能做很多事,但真正可靠的只有一小部分”。Hermes Agent
这两年看 AI Agent 工具,会有一个挺明显的感觉:大家都在往同一个方向加东西。多工具调用、多模型路由、多智能体协作、自动化工作流……每一项单独看都合理,甚至必要,但组合在一起之后,体验并没有线性变好。很多系统在某个 demo 里看起来很完整,但一旦放进真实使用环境,就会开始暴露一些老问题,比如行为不稳定、上下文漂移、或者“看起来能做很多事,但真正可靠的只有一小部分”。Hermes Agent
对于一个网盘搜索引擎来说,搜索速度很重要,但比速度更重要的,其实是结果质量。过去几个月,我们一直在持续扩充万盘搜的数据规模。目前平台已累计收录超过 150 万条公开网盘资源,覆盖影视、动漫、课程、电子书、软件工具、AI资源等多个领域。数据量越来越大之后,一个问题开始变得明显:用户搜索到了结果,但未必是最想要的结果。例如搜索:美女 古风以前系统能够快速返回大量相关资源,但搜索结果更多是按照更新时间排
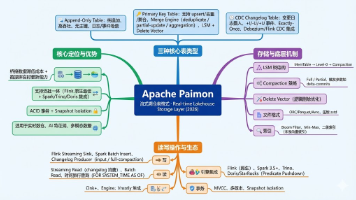
本文深入解析Apache Paimon的核心概念与存储机制,重点介绍其三种表类型:Append-Only表(纯追加)、Primary Key表(主键约束)和CDC Changelog表(变更日志)。详细阐述了Paimon基于LSM树的存储架构、Compaction策略及多引擎集成能力,并分析了不同表类型的适用场景与参数配置。作为2026年实时湖仓架构的关键组件,Paimon通过创新的数据模型实现了