




- @htw250056
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了网络库中Poller模块的设计与实现。Poller作为底层I/O多路复用机制的封装,负责管理所有Channel的事件监控状态,弥补了Channel无法直接与操作系统交互的不足。文章首先阐述了Poller的核心功能:1) 添加/修改描述符事件监控;2) 移除监控。随后详细展示了其实现方案,包括通过哈希表维护fd与Channel的映射关系,封装epoll_ctl操作,以及实现阻塞式事件监控(

本文介绍了飞算JavaAI在Java开发中的应用价值。该工具针对重复性编码场景如业务逻辑、异常处理、注释生成等提供智能辅助,特别适合中小型项目和教学场景。通过TextAnalyzer项目案例,展示了AI如何优化代码质量:自动补全参数校验、推荐try-with-resources等现代语法、生成标准注释文档。相比人工开发,AI辅助使工具类封装效率提升66%,异常处理时间缩短75%。虽然不适合复杂系统

【VSCode高效插件推荐】本文精选18款提升开发效率的实用插件:1.调试神器:ConsoleNinja(行内显示控制台输出)、TurboConsoleLog(智能生成console)、Quokka.js(实时运行结果)2.界面优化:Peacock(多项目窗口染色)、BetterComments(分类高亮注释)、IndentRainbow(缩进可视化)3.前端必备:LiveServer(热更新服务

AI正从单一模型向系统化协作演进。早期大模型追求规模与精度,但存在记忆、调度等局限,催生了AutoGPT等智能体框架。多智能体协作(如ChatDev)通过角色分工实现任务并发,采用结构化通信协议提升效率。Devin首创AI工程师系统,集成开发环境与记忆管理,形成感知-行动-反馈循环。AgentOS雏形显现,包含智能体调度、记忆存储等模块,类似操作系统管理语义进程。当前框架如LangChain侧重工

AI研究正从语言智能转向具身智能和世界模型,这是通向通用人工智能的关键路径。当前大语言模型虽能处理文本,但缺乏对物理世界的真实理解。世界模型通过编码器、动力学模型和解码器的闭环,让AI具备"内在模拟"能力,实现预测和规划。DeepMind的Dreamer系列和MuZero等突破表明,AI已能在"梦境"中学习策略。具身智能强调感知-行动闭环,使AI通过身体交互

本文系统介绍了强化学习(RL)的核心概念与应用。从马尔可夫决策过程(MDP)到价值函数与策略优化,详细解析了动态规划、Q-learning、DQN、策略梯度及Actor-Critic等算法框架。重点探讨了现代RL算法PPO的原理及其在大模型RLHF(基于人类反馈的强化学习)中的关键作用,如ChatGPT的优化过程。同时指出RL面临的挑战(奖励设计、样本效率等)及未来发展方向(分层RL、世界模型等)

AI智能体正从单纯的语言模型向具备自主行动能力的系统进化。2023年后,ChatGPT等模型展示了理解意图、制定计划的能力,催生了AIAgent研究。AutoGPT首次实现LLM自主分解任务、调用工具,OpenDevin则构建了更结构化的多模块系统。关键技术包括记忆系统、工具调用及规划反思能力,使AI具备持续意识和元认知。当前智能体正从模块化工具链向系统级AI演进,未来或将形成具备感知、推理、学习

Any通用类型简介与实现 Any是一种类型擦除容器,能够存储任意类型的值并安全恢复原始类型。它解决了传统void*丢失类型信息的问题,避免了复杂的继承体系,适用于需要处理多种数据类型的场景(如服务器协议处理)。 核心特性: 类型擦除:统一接口存储不同类型 类型安全:运行时检查确保类型匹配 值语义:支持深拷贝和赋值操作 实现原理: 使用基类holder定义通用接口 模板子类placeholder存储

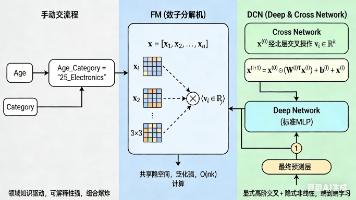
摘要:特征工程的科学与艺术进阶 本章深入探讨特征工程的高级技术,将原始数据提炼为高效特征集。主要内容包括: 特征交叉:通过手动或自动方式(如因子分解机、深度交叉网络)揭示特征间隐藏的交互模式,突破线性模型局限。 目标编码:针对高基数类别特征,用目标变量统计量进行编码,并采用留一法或K折交叉防止数据泄露。 实践工具:介绍scikit-learn的PolynomialFeatures和category
本文系统介绍了强化学习(RL)的核心概念与应用。从马尔可夫决策过程(MDP)到价值函数与策略优化,详细解析了动态规划、Q-learning、DQN、策略梯度及Actor-Critic等算法框架。重点探讨了现代RL算法PPO的原理及其在大模型RLHF(基于人类反馈的强化学习)中的关键作用,如ChatGPT的优化过程。同时指出RL面临的挑战(奖励设计、样本效率等)及未来发展方向(分层RL、世界模型等)