




- @howard_shooter
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了ClaudeCode安装后的配置文件修改方法。针对不同AI平台(智谱、DeepSeek、SilliconFlow)提供了对应的settings.json配置模板,包含API密钥、基础URL、模型名称等关键参数设置。文件路径说明:MacOS/Linux为~/.claude/settings.json,Windows为用户目录/.claude/settings.json。同时还提供了.cla
这里 “Oracle网络”,并不是指TCP/IP这种网络知识,而是指Oracle自己定义的一套逻辑和概念,它们控制着客户端与数据库的连接。Oracle 网络中的概念:listener:listener是独立于实例的Oracle服务器端进程,专门用于受远程连接。每个客户端在服务器端对应一个服务进程(server process(PGA))。但客户端首次连接的时候,不是直接连接服务进程(server
k8s虽然使用docker下载镜像,但是存储在docker image里的镜像是不能被k8s使用的,但是kind不同,可以使用下面的方法,让kind-k8s加载docker image里的镜像。可以用这个kind命令加载docker image里的镜像,到kind-k8s环境里,这样k8s就不会到网上下载镜像了。

这两篇文章讲的很好,我照着做,在我的CentOS7.9上成功安装了26.1.4。
最近通过阅读masstree、silo论文,总结出一些阅读论文的心得:1、要想读懂这些论文,有时候要去了解相关背景知识,例如,为了解决B-Tree并发访问问题,学术工业界这些年的努力,提出过哪些理论尝试?并发控制算法提出过哪些方案?如果对这些行业、技术的历史或背景知识完全不了解,阅读起来就很困难。2、要找重点,或者说找重点话题,选择一个切入点,这个切入点可以是这篇论文讨论的某个方法技术,也可以是我
关于12c 升级 19c,这篇文章写的已经很好12c升级19c我不再重复,以下记录我升级过程中的步骤和问题。之前自己摸索过在12.1.0.2上不打补丁,直接用DBUA升级,结果失败,于是老老实实按照网上的步骤做,用autoupgrade升级,12.1.0.2打补丁。使用AutoUpgrade方式升级,需要下载autoupgrade.jar和补丁包。12.2.0.1 和12.1.0.2 有各自。
解压到$ORACLE_HOME目录下(以oracle用户执行,注意:一定要解压到$ORACLE_HOME下)至此,完成了安装Oracle数据库软件,但数据库还没有创建,也没有创建任何数据库的用户,因此数据库还不能使用。选 “Single instance database installation“查看操作系统里有哪些组、组里有哪些用户:/etc/group。设置oracle密码:passwd o
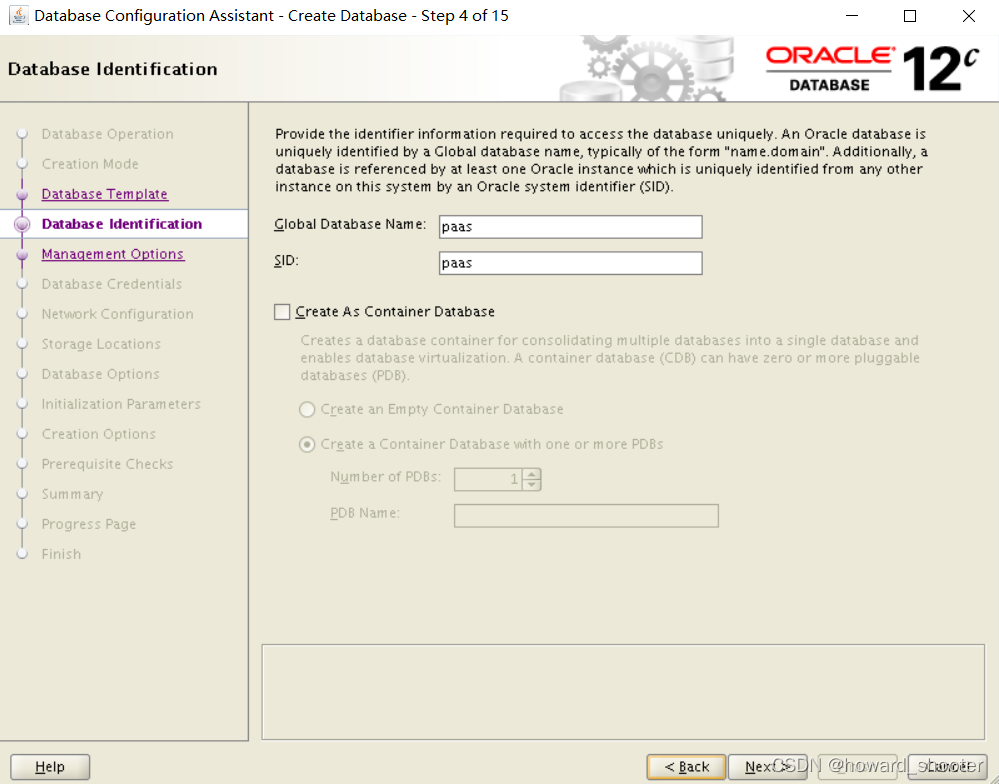
Step 4 根据需要设置Global database name(也是SID),不勾选Create as Container database,创建完数据库后要设置ORACLE_SID变量为这个SID,注意,大小写敏感!Oracle安装完成后,可以手动创建目录、参数文件、密码文件、执行SQL创建数据库,也可以用dbca命令,调出图形界面创建数据库,从体验来说,我个人比较喜欢用dbca。Step
在patroni/ha.py中替换掉enforce_master_role()对update_cluster_history()的调用,改为调用update_promote_history(),update_promote_history()就是我实现,保存当前主节点信息的函数。这里需求就是,Patroni管理的Opengauss集群,当某个节点从备机切换到主机时,会向etcd的history键的
假设IP为172.32.148.154的OpenGauss机器连接IP为172.32.148.155的机器,查询155中的表public.emp,155的端口号为31001,数据库名postgres,用户postgres/Postgres123:在154机器上执行:CREATE EXTENSION postgres_fdw;CREATE SERVER foreign_server FOREIGN