- @hl_java
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文探讨了如何为Java Agent设计类似ChatGPT Code Interpreter的动态代码执行能力,以解决传统硬编码工具方法的局限性。主要内容包括: 问题背景:传统Tool Calling模式需要为每个功能预定义工具,导致维护成本高且限制AI能力边界。 技术选型:选择Groovy作为动态执行引擎,因其语法兼容Java、可直接调用Java标准库且支持即时执行。 架构设计:采用两层结构,工
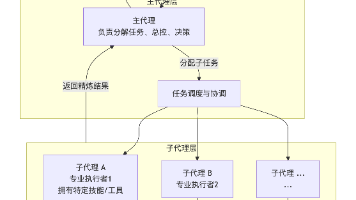
摘要: 本文演示了如何在Mac上基于Ollama和phi3:mini构建一个多智能体协作系统。通过创建一个主Agent和两个专业Subagent(任务分解专家和执行专家),实现了复杂任务的自动分解与执行。文章提供了完整的代码实现,包括: 项目目录结构 核心Agent基类定义 两个具体Subagent实现(任务分解JSON格式输出、任务执行状态报告) 与Ollama API的交互方法 错误处理机制(
本文详细介绍了在OpenClaw中配置本地qwen2.5:7b模型的完整流程。主要内容包括:通过Ollama搭建兼容OpenAI API的本地服务器,下载4.7GB的Qwen2.5模型;安装配置OpenClaw并修改相关参数;以及最后的验证测试步骤。重点解决了模型窗口大小报错等常见问题,提供了可直接使用的配置示例。该方案支持Windows/macOS/Linux系统,推荐16GB以上内存,包含手动
本文介绍了在Mac开发机上通过Ollama运行qwen2.5:7b-instruct模型并调用其API的方法。主要提供两种调用方式:推荐使用兼容OpenAI格式的/v1/chat/completions端点,以及备选的Ollama原生/api/generate端点。文章包含完整的curl命令示例、参数说明、服务验证方法和实用技巧(如结合jq格式化输出),并附有执行抓包日志截图。调用前需确保Olla
本文深入解析了AI Agent隐式工具调用的工作原理,重点介绍了ReAct模式(推理+行动)的实现机制。通过一个读取PDF文件的实例,展示了Agent如何自动完成:1)理解用户意图;2)选择并调用read_pdf工具;3)总结核心内容的三步流程。文章详细剖析了关键技术组件,包括工具注册机制、系统提示词设计、模型调用格式器以及ReActAgent的执行循环逻辑。该架构使AI助手能够智能地识别任务需求
如果你是OpenClaw的用戶,一定在文档或社区中频繁看到两个名字:OpenClaw 和 ClawHub。它们听起来像是一对孪生兄弟,但实际扮演的角色截然不同——简单来说,OpenClaw是“虾”(智能体本身),而ClawHub是“水产市场”(技能交易中心)。本文将深入解析两者的定位与协作关系,帮你彻底理清这对核心概念。OpenClaw(曾用名Clawdbot、Moltbot)是一个开源AI Ag
本文提出了一种结构化需求澄清方案,通过5个维度系统性地提问,将PRD中的隐含假设显式化。该方案包含整体流程架构(读取PRD→确认理解→5轮维度澄清→编译文档→用户确认)和数据流架构,重点设计了五大澄清维度:范围边界、交互流程、异常与边界、数据规则和非功能需求。每个维度提供具体问题模板和检查清单,确保生成AI可直接消费的精确规格文档,解决现有PRD隐含假设导致代码生成不准确的问题。
本文提出了一种结构化需求澄清方案,通过5个维度系统性地提问,将PRD中的隐含假设显式化。该方案包含整体流程架构(读取PRD→确认理解→5轮维度澄清→编译文档→用户确认)和数据流架构,重点设计了五大澄清维度:范围边界、交互流程、异常与边界、数据规则和非功能需求。每个维度提供具体问题模板和检查清单,确保生成AI可直接消费的精确规格文档,解决现有PRD隐含假设导致代码生成不准确的问题。
本文分析了为什么需求澄清适合用Skill而非Tool或SubAgent实现。关键点在于:需求澄清需要结构化流程引导用户补充PRD的隐含假设,具有多轮交互、强用户决策和模板化输出的特点。Tool适合确定性操作但缺乏流程编排能力;SubAgent过于自治可能导致脑补答案或提问混乱;而Skill的模板驱动、交互式执行和主流程无缝衔接特性完美匹配需求澄清的三个核心需求:维度覆盖、用户决策和可消费输出。这种
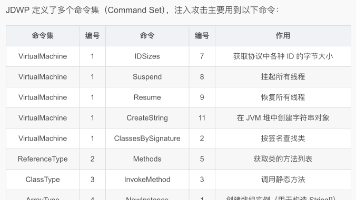
JDWP 注入的本质是利用 Java 调试协议的设计特性——无认证 + 任意方法调用——来实现远程代码执行。攻击的核心难点在于获取一个「事件挂起」状态的线程,这需要理解 JDWP 的事件机制和线程挂起模型。JDWP 无认证,连接即可完全控制 JVMInvokeMethod 需要事件挂起的线程,不能用 VM.SuspendSINGLE_STEP 事件是获取事件挂起线程的首选方式,失败时自动降级到断点