




- @hgj1h
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
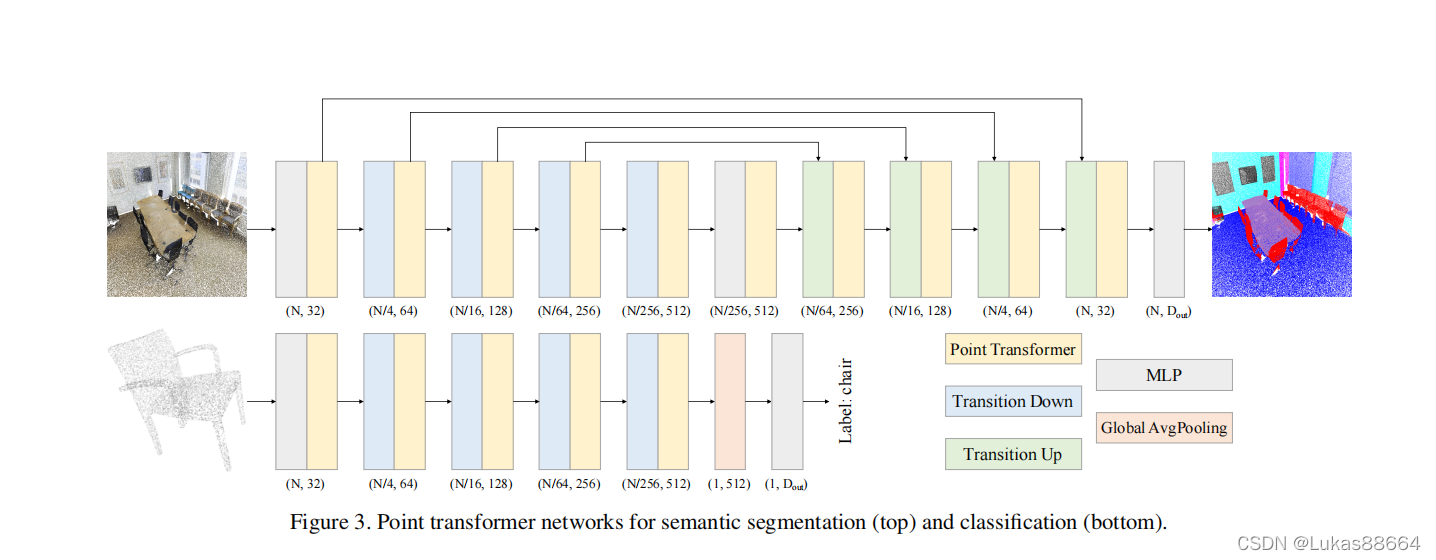
论文标题:Point Transformericcv2021用transformer做点云工作出于点云的随机性 transformer正好处理此类问题但是 很显然对于大规模的点云 直接使用transformer计算量是巨大的 所以作者提出来一种新的transformer处理形式,那便是knn查找临近点。首先 作者介绍了transformer的背景 自注意力操作主要可以分为scalar和vector
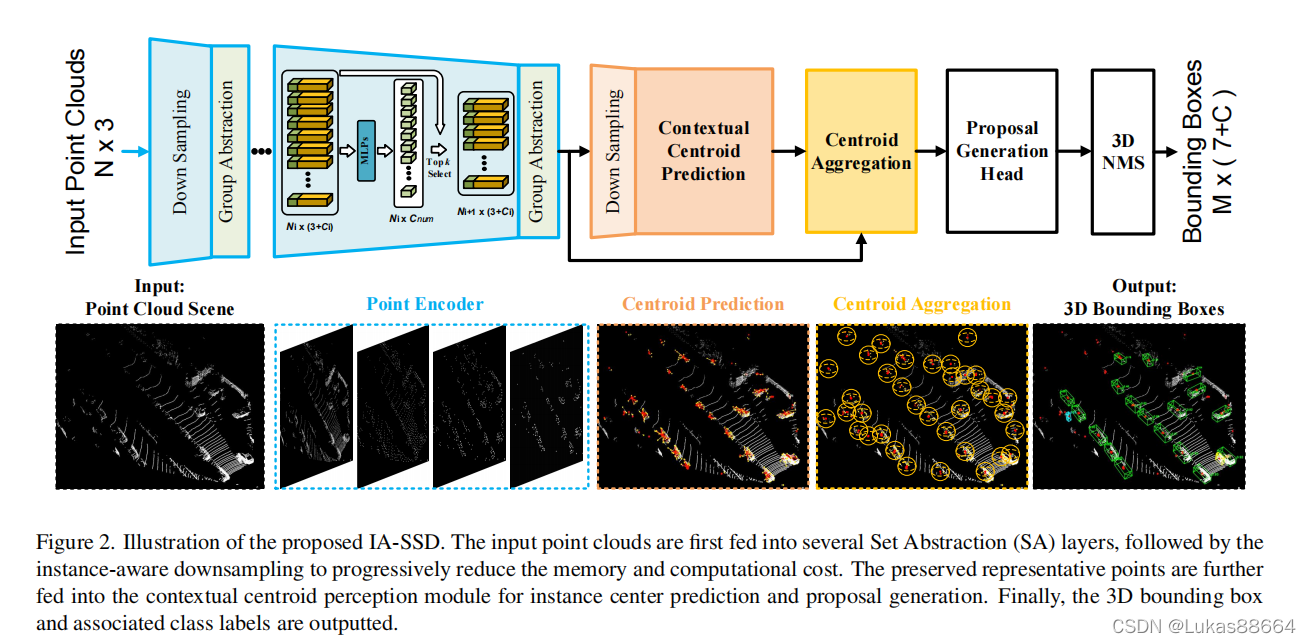
论文题目:Not All Points Are Equal: Learning Highly Efficient Point-based Detectorsfor 3D LiDAR Point Cloudscvpr 2022如题目所说,本篇文章认为像pointnet++的sa层来采取下采样点或者像pvrcnn中的基于feature距离的代表点,随着下采样的进行,往往会遗漏一些前景目标,作者做了个实
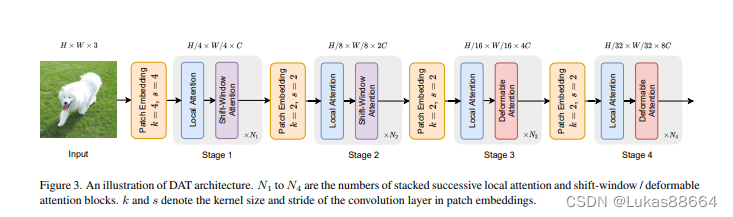
随着swin transformer成为best paper。transformer用于2d图像领域更加引起人们的广泛关注,划分框框的方法确实有些笨拙。我也看了一些相关的文章,不过有些文章没有开源出代码来。记录一下:Vision Transformer with Deformable Attention论文连接:https://arxiv.org/abs/2201.00520v1已开源放心使用 用
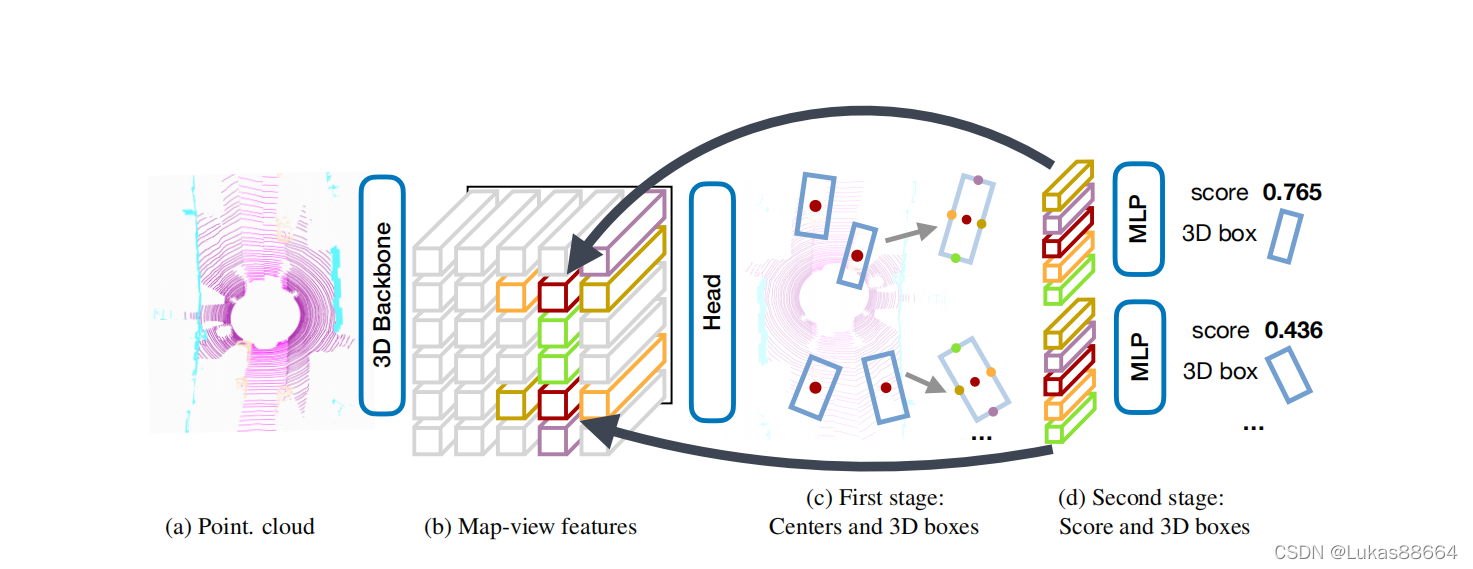
论文标题:Center-based 3D Object Detection and Tracking一篇基于中心的3d目标检测文章,2021年文章在waymo、nuscene上做了实验。还是比较充分的。和其他一些anchorbased的方法进行了对比 突出了其优越性。废话不多说 上图!该网络是一个二阶段的网络:RPN首先对点云进行voxel处理,从后面的实验可以看出作者用了两种backbone —
论文标题:Point Transformericcv2021用transformer做点云工作出于点云的随机性 transformer正好处理此类问题但是 很显然对于大规模的点云 直接使用transformer计算量是巨大的 所以作者提出来一种新的transformer处理形式,那便是knn查找临近点。首先 作者介绍了transformer的背景 自注意力操作主要可以分为scalar和vector
这篇文章主要介绍了lidcamnet,利用lidar及camera进行道路检测,主要创新点在于提出了三种网络结果,并进行对比。首先提出base网络,分为编码器 解码器及中间的语义分析网络,语义分析网络利用空洞卷积的方法增大感受野。二种传感器的融合分为了三种融合方式为 前融合 (直接将camera及lidar信息在深度方向上叠加) 后融合(在decision层叠加二种的feature map ) 及
论文标题:Point Transformericcv2021用transformer做点云工作出于点云的随机性 transformer正好处理此类问题但是 很显然对于大规模的点云 直接使用transformer计算量是巨大的 所以作者提出来一种新的transformer处理形式,那便是knn查找临近点。首先 作者介绍了transformer的背景 自注意力操作主要可以分为scalar和vector
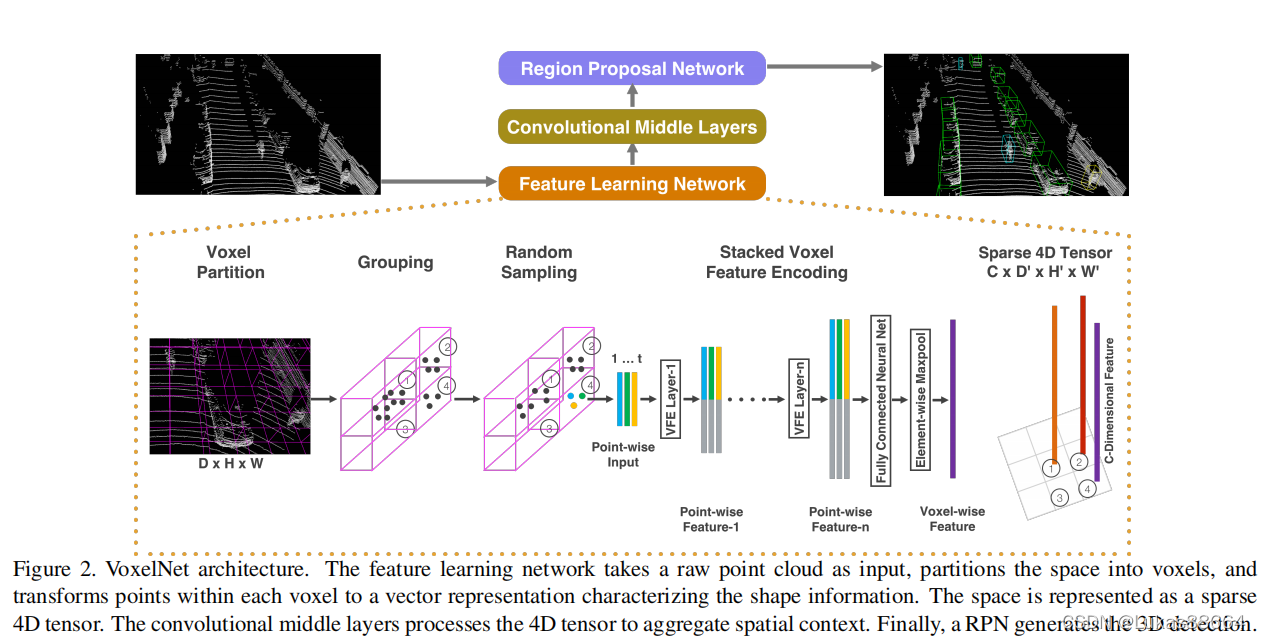
论文标题:VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection挺经典的一篇文章,苹果公司出品。挺久前看的了,感觉需要记录一下结构,方便以后查阅。网络架构分为三个部分: (1) Feature learning network, (2) Convolutional middle layers, and (3)
随着swin transformer成为best paper。transformer用于2d图像领域更加引起人们的广泛关注,划分框框的方法确实有些笨拙。我也看了一些相关的文章,不过有些文章没有开源出代码来。记录一下:Vision Transformer with Deformable Attention论文连接:https://arxiv.org/abs/2201.00520v1已开源放心使用 用