




- @daweq
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
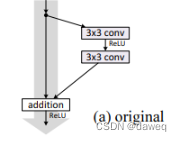
一、背景传统的神经网络,由于网络层数增加,会导致梯度越来越小,这样会导致后面无法有效的训练模型,这样的问题成为梯度消弭。为了解决这样的问题,引入残差神经网络(Residual Networks),残差神经网络的核心是”跳跃”+“残差块”。通过引入RN网络,可以有效缓解梯度消失的问题,可以训练更深的网络。二、残差网络的基本模型下图是一个基本残差块。它的操作是把某层输入跳跃连接到下一层乃至更深层的激活

第一个卷积层的输入通道为1,输出通道为10,卷积核的大小为5x5,通过此卷积层,输出数据的大小为(batch,10,24,24),通过第一个ReLU激活层,大小不变。第二个卷积层的输入通道为10,输出通道为20,卷积核的大小为5x5,通过此卷积层,输出数据的大小为(batch,20,8,8),通过第一个ReLU激活层,大小不变。卷积->激活->池化->卷积->激活->池化->转变为线性数据->线性

(2)使用jieba分词对文本数据进行分词,并可视化分词效果。(3)设计停止词表,对文本数据的多余部分进行删除。(1)用合适的格式读取文本数据。(4)对文本数据进行词云展示。(5)TF-IDF提取关键词。(6)LDA主题模型。

将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。3x3的卷积核的参数为9,5x5的卷积核参数为25,所以理论上使用3x3的卷积核更好,那么我们能不能找一种特殊的卷积方式,在不改变表达方式的情况下,分解卷积核呢?的作用是减少输入数据的维

ResNet18的基本含义是,网络的基本架构是ResNet,网络的深度是18层。但是这里的网络深度指的是网络的权重层,也就是包括池化,激活,线性层。3,步长为1,padding为1。这个卷积层的卷积核的大小为7。7,步长为2,padding为3,输出通道为64。也就是说这个池化不改变数据的通道数量,而会减半数据的大小。224,也就是3个通道,每个通道的大小为224*224。也就是将输出通道翻倍,输
当“soft targets”具有很高的熵时(也就是各个概率差异不会很大,不会有数量级的差距,比如一个为0.5,一个为10^-10这样),它相对于“hard targets”能够提供更多的信息,同时会使得每一个类别的训练梯度不会过于分散,所以小模型可以使用更少的数据进行学习,同时可以提高学习率。如果繁琐的模型泛化得很好,例如,它是不同模型的大型集合的平均值,那么以相同方式训练泛化的小模型在测试数据

一、目标本文主要完成除带随机失活(dropout shortcut)以外的模型。二、关键代码(1)constant scaling与原始残差块的差别在于,将输出从y=f(x)+x变成了y=0.5[f(x)+x]。如图Fig.2(b)所示,设置\lambda=0.5,即h(xl)=0.5xl,对于残差函数F有两种处理方式,一种是不加缩放系数,另一种是残差函数F以1-\lambda为系数进行缩放。试验

ResNet18的基本含义是,网络的基本架构是ResNet,网络的深度是18层。但是这里的网络深度指的是网络的权重层,也就是包括池化,激活,线性层。3,步长为1,padding为1。这个卷积层的卷积核的大小为7。7,步长为2,padding为3,输出通道为64。也就是说这个池化不改变数据的通道数量,而会减半数据的大小。224,也就是3个通道,每个通道的大小为224*224。也就是将输出通道翻倍,输