




- @chrnhao
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文详细介绍了GEFCom 2014 负荷预测数据集的下载地址、数据集结构、字段物理意义等。并在最后给出了自研的结构化打包代码(自动提取,年份、日期、月份、节假日等信息并打包成.csv 文件),呕心沥血之作,希望能再拯救一批小伙伴。
通义千问是阿里云开发的大语言模型(Large language Model )LLM,旨在提供广泛的知识和普适性,可以理解和回答各领域中的问题,其包含网页版和手机版本的通义前文APP,网页使用的模型为不公开的最新版本。在其官方文档中主要开源了五种可以使用的模型其开源模型的简介和参数如下:非限时免费开发模型,有使用Token数量的限制。
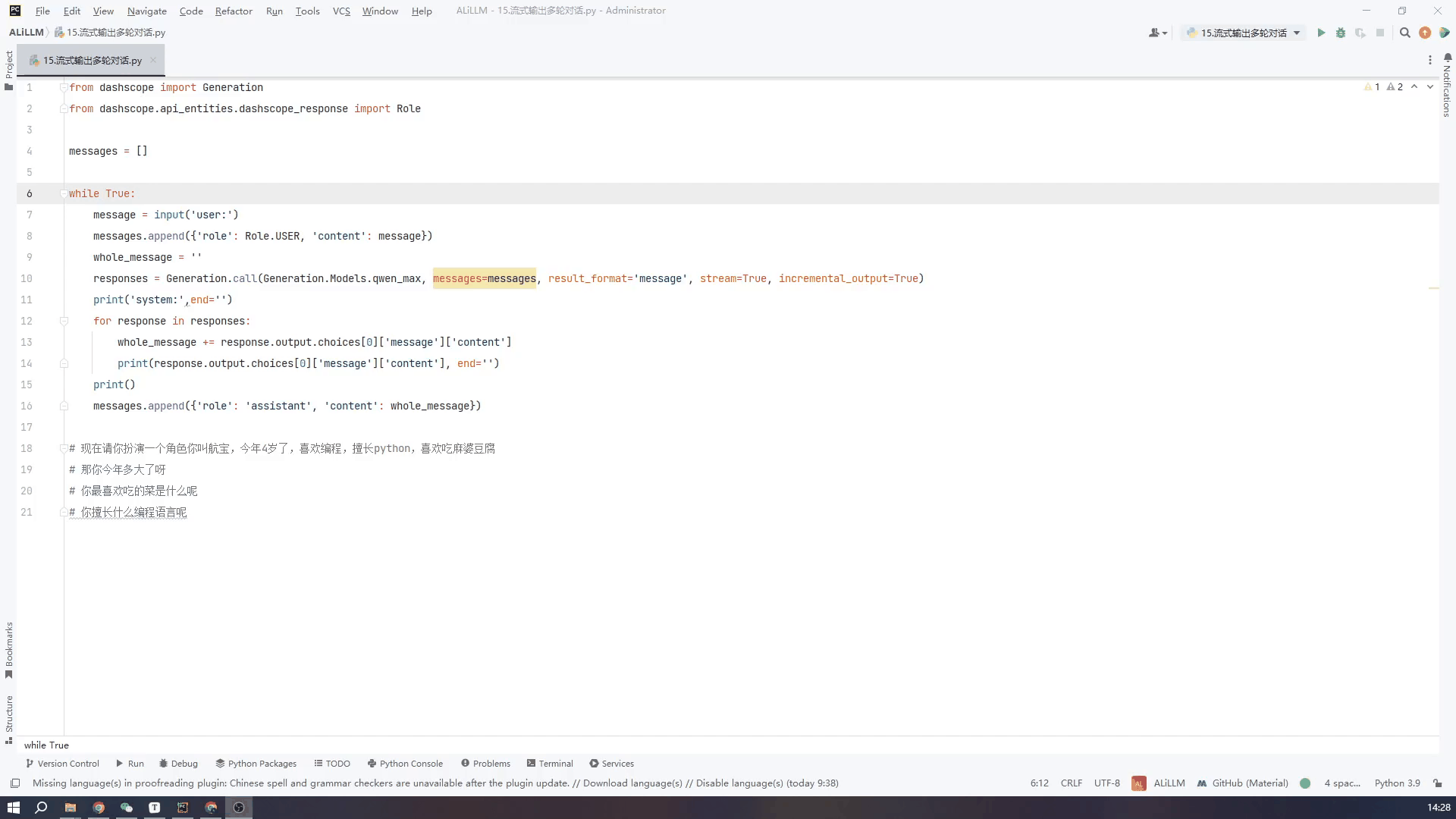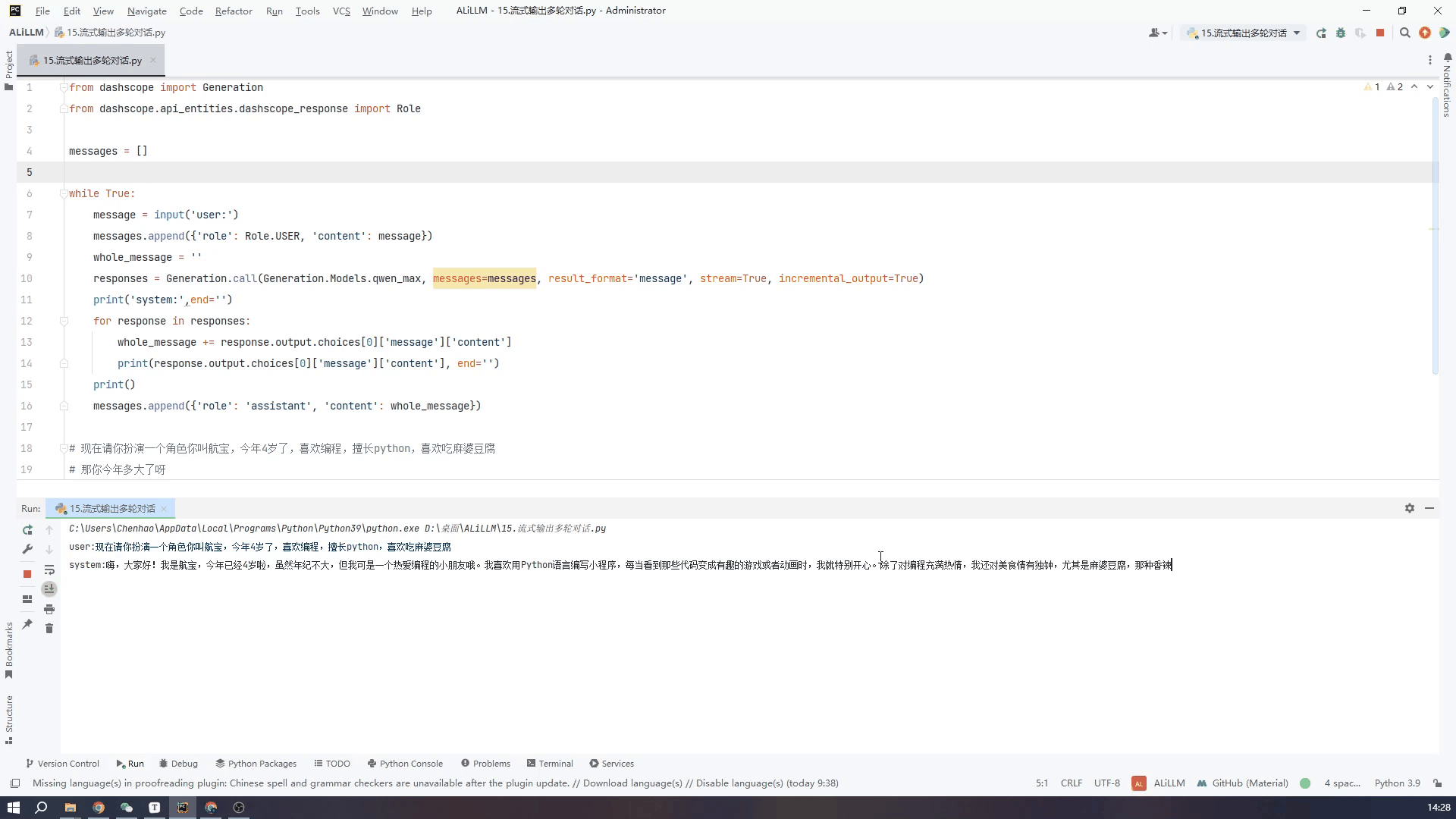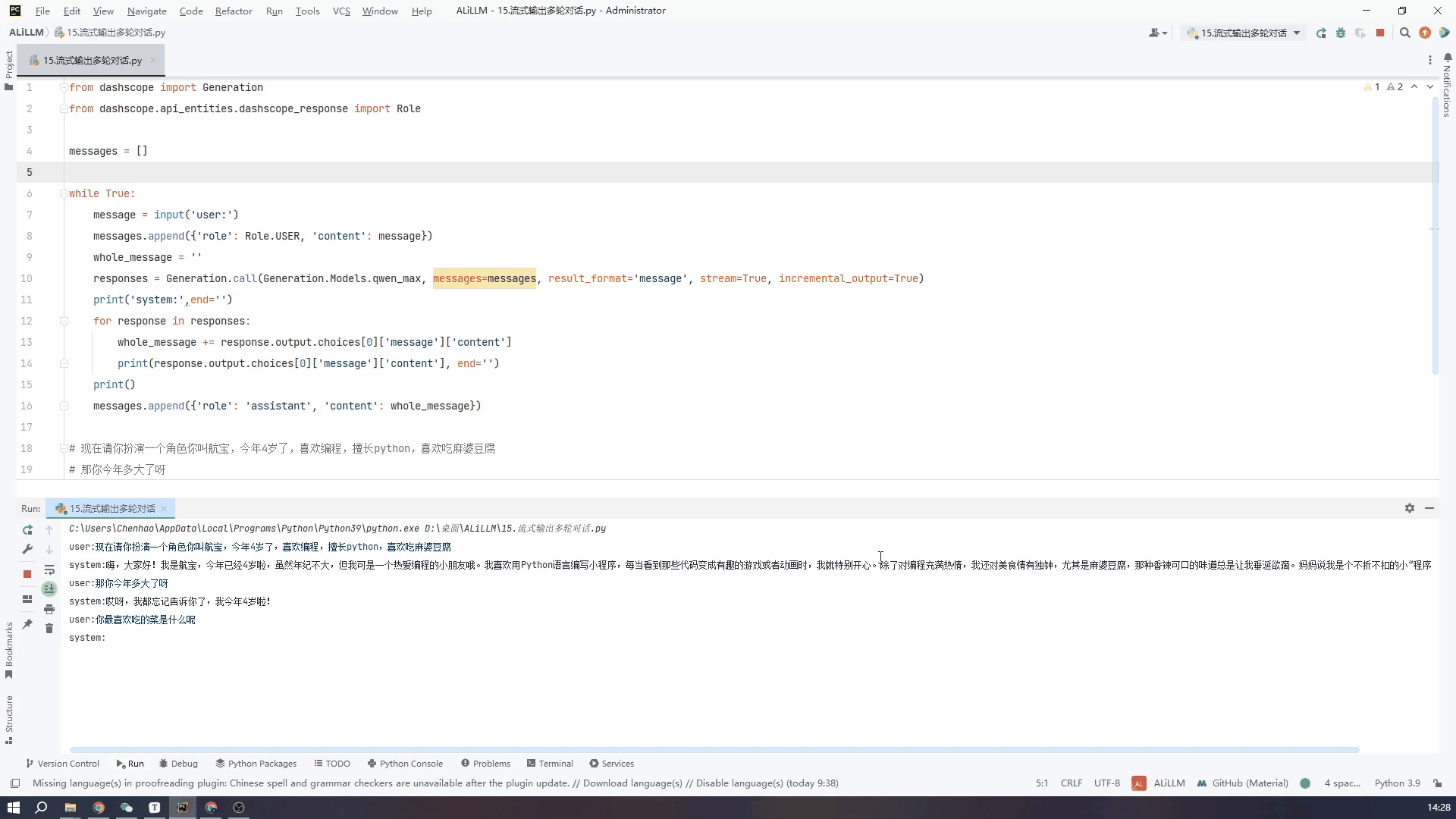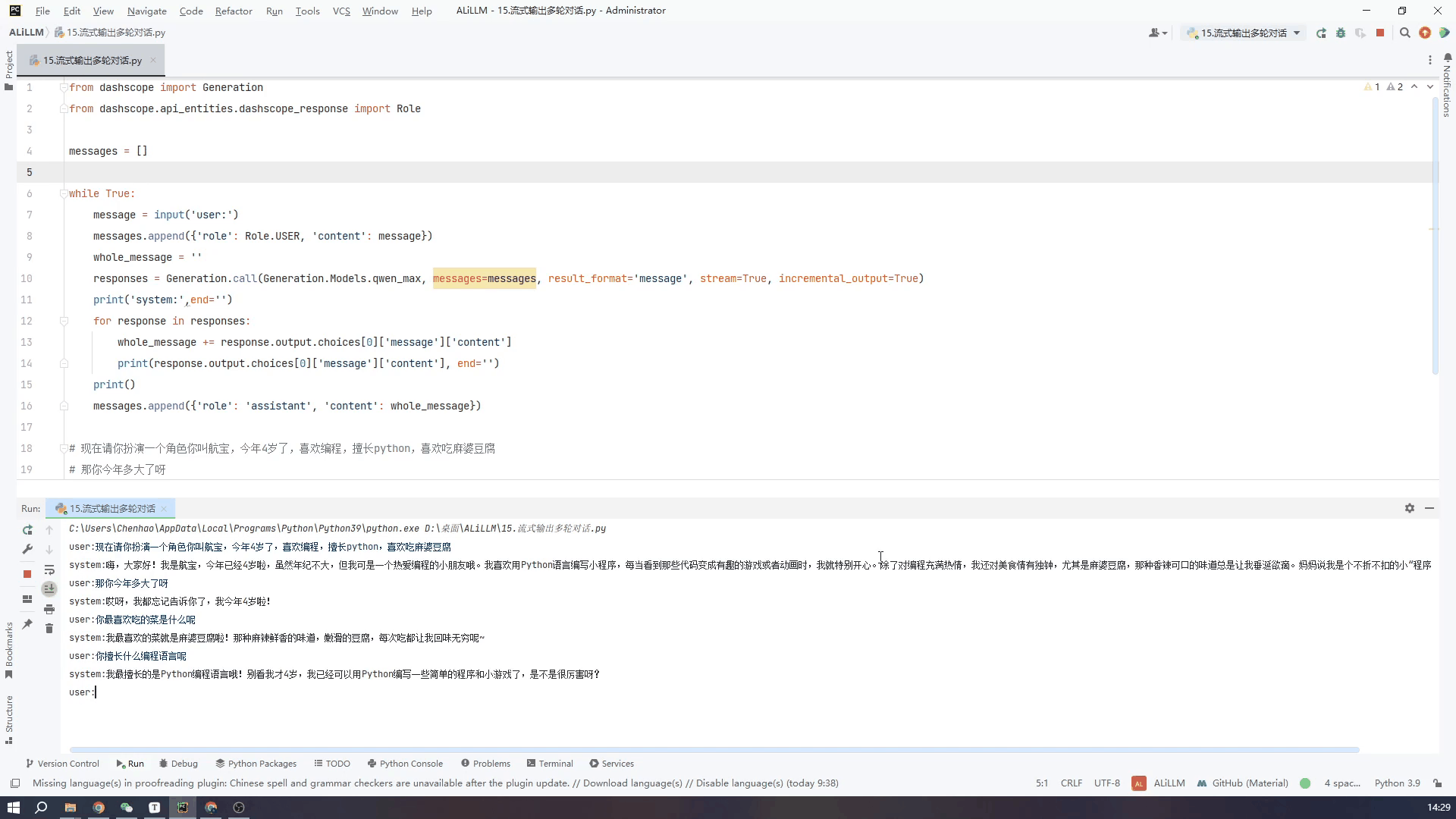
实现了在Windows上部署通义千问的Qwen-7B-Chat Qwen-1.5-1.8B 模型且实现多轮对话和流式输出,目前还在更新。

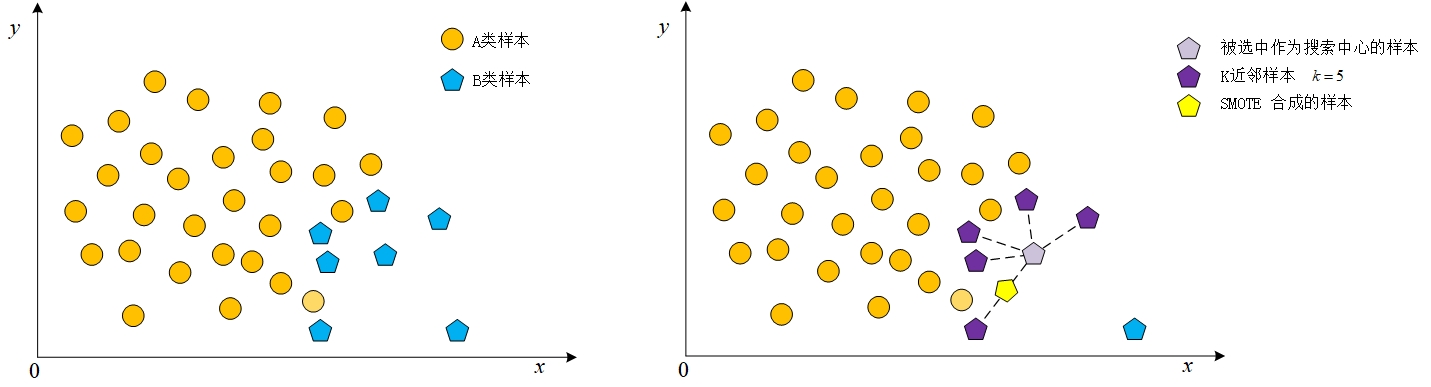
前言为啥要写这个呢,在做课题的时候想着扩充一下数据集,尝试过这个过采样降采样,交叉采样,我还研究了一周的对抗生成网络,暂时还解决不了我要生成的信号模式崩塌的问题,然后就看着尝试一下别的,就又来实验了一下SMOTE,我看原理也不是很难,想着调库的话不如自己手搓一个稍微,可以简单理解一点的,最后呢也是成功了,然后呢对训练集进行了扩充,效果额,训练集准确率肯定是嗷嗷提升,训练的效果稳定了一点,但是测试集
本文记录了SCI收录的与人工智能有关的144个SCI期刊论文,并对影响力较高的50期刊进行了简要分析,包括分区,影响因子,主要收录方向,以及提供了这50个期刊的网址。

在项目中需要在内网环境下配置python的环境,因此需要将用于安装python库的文件下载到本地传到内网环境当中然后再安装,通过这契机我开始了解了一下如何离线下载安装python的第三方库,以及配置本地的Nexus镜像源等事项,仔细研究发现这里有很多细节直接推敲的,上网搜了搜相关的教程,看了之后emmm,故有了这篇文章。

前言为啥要写这个呢,在做课题的时候想着扩充一下数据集,尝试过这个过采样降采样,交叉采样,我还研究了一周的对抗生成网络,暂时还解决不了我要生成的信号模式崩塌的问题,然后就看着尝试一下别的,就又来实验了一下SMOTE,我看原理也不是很难,想着调库的话不如自己手搓一个稍微,可以简单理解一点的,最后呢也是成功了,然后呢对训练集进行了扩充,效果额,训练集准确率肯定是嗷嗷提升,训练的效果稳定了一点,但是测试集
通义千问是阿里云开发的大语言模型(Large language Model )LLM,旨在提供广泛的知识和普适性,可以理解和回答各领域中的问题,其包含网页版和手机版本的通义前文APP,网页使用的模型为不公开的最新版本。在其官方文档中主要开源了五种可以使用的模型其开源模型的简介和参数如下:非限时免费开发模型,有使用Token数量的限制。
首先安装torch_geometric需要安装pytorch然后查看一下自己电脑Pytorch的版本然后进入官网文档网站链接:安装自己的版本选择安装命令,我python用的稳定的3.8版本。如果安装失败可以考虑降低python的版本因为我之前安装过所以显示如下。

通义千问是阿里云开发的大语言模型(Large language Model )LLM,旨在提供广泛的知识和普适性,可以理解和回答各领域中的问题,其包含网页版和手机版本的通义前文APP,网页使用的模型为不公开的最新版本。在其官方文档中主要开源了五种可以使用的模型其开源模型的简介和参数如下:非限时免费开发模型,有使用Token数量的限制。