- @boonya
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
SpringAI是Spring生态下的AI应用框架,为Java开发者提供了一套完整的AI集成解决方案。文章从全景认知、学习路径到项目实践,系统性地介绍了如何正确使用SpringAI: 核心能力:支持多模型调用、结构化输出、向量数据库集成、RAG全链路和Agent模式,相当于Java版的LangChain。 学习路径分为四个阶段: 快速入门:配置API Key实现基础对话 深入核心API:掌握Cha
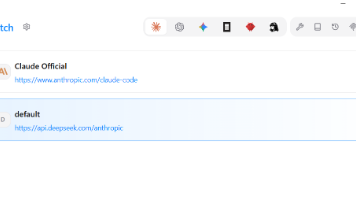
本文介绍了使用CCSwitch工具将ClaudeCode后端配置为DeepSeekv4-pro模型的完整流程。CCSwitch是一款GUI配置管理器,可自动化生成环境变量和配置文件,实现多模型后端切换。指南包含Windows平台下的安装准备、CCSwitch配置、底层文件验证及测试步骤,并提供了关键参数设置和常见问题解决方案。通过配置BaseURL、认证类型和API Key等参数,用户可将Clau
本文详细介绍了使用Docker Compose搭建Flink+Kafka+MySQL开发环境的完整流程。主要内容包括:1)通过docker-compose.yml一键部署开发环境;2)Maven项目配置关键依赖和Shade插件打包;3)开发实时计算PV/UV的Flink作业,实现从Kafka消费数据并写入MySQL;4)三种作业提交方式(WebUI、docker exec、一次性容器);5)常见问

这是一个非常核心且高频的Java面试话题。我将为你系统地梳理JVM的核心原理,并附上常见的面试题及解答思路。

Java的JIT编译器通过分层编译和热点代码探测实现性能优化。分层编译结合解释器、C1和C2编译器,在启动速度和峰值性能间取得平衡。JIT基于计数器识别热点代码,采用方法内联、逃逸分析等关键技术优化执行效率:内联消除方法调用开销,逃逸分析支持栈分配、标量替换和锁消除。开发者应编写JIT友好代码(小方法、局部作用域),避免过早优化,并利用JVM参数监控编译过程。这些机制使Java从解释执行语言发展为
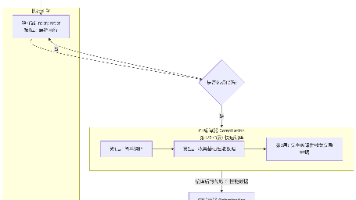
Java类加载机制解析:核心包括加载、验证、准备、解析和初始化五个阶段,双亲委派模型通过层次化加载确保类唯一性和安全性。特殊场景需打破该模型,如SPI机制通过线程上下文类加载器实现逆向委托。自定义类加载器通过重写findClass方法实现非标准类加载,常用于热部署和隔离。理解这一机制对解决类加载异常、依赖冲突及构建模块化系统至关重要。
本文介绍了如何为电商和游戏平台引入RAG技术构建AI智能体,从概念到实践的学习路径。核心包括:1)理解RAG检索增强生成原理;2)参考电商推荐、游戏客服等成功案例;3)掌握混合检索、结果精炼等优化技术;4)分阶段实施路径:从问答助手原型到流失预警系统,再到复杂任务处理和模型微调。特别针对大数据团队提出技术选型建议,推荐使用LangChain框架、Milvus向量数据库等工具,强调从实时服务和数据质

摘要:基于Langchain4j框架和阿里百炼API开发了Java版RAG智能文档聊天系统,支持PDF文档的检索与分析。项目实现了文档上传、切片、索引到RAG问答的全流程,核心应用场景包括计算机教材概念检索和个人简历分析。目前需要解决文档切片乱码和提示词优化等问题,并采用单一职责设计。相关代码已开源在boonya-game-lab项目中,作者将持续推进AI智能体开发。
Rust是一种融合C++高性能与Java安全特性的现代编程语言,其核心创新在于编译时保障内存安全的所有权系统。诞生于2006年Mozilla工程师Graydon Hoare的个人项目,Rust经过社区协作发展,于2015年发布1.0稳定版。它兼具零成本抽象、无畏并发等特性,广泛应用于操作系统、浏览器引擎等领域。Rust拥有活跃的开源社区和基金会支持,通过定期版本迭代持续完善异步编程等现代特性。在A

摘要:C++在继承C语言高性能基础上,增加了面向对象、泛型编程等现代特性,使其成为大型复杂项目开发的理想选择。C++提供丰富的标准库、智能指针内存管理、异常处理等功能,显著提升开发效率和代码质量。相比C语言,C++具有更强的抽象能力和类型安全,特别适合AI、游戏开发等高性能计算场景。现代C++特性(如模板元编程、并发支持)使其在AI时代仍保持竞争力,成为连接高层抽象与底层性能的关键语言。