




- @benben044
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
vLLM框架通过PagedAttention技术革新了LLM推理的内存管理,将KV缓存分块存储并支持动态共享,使内存利用率提升至80%以上。其核心架构包含调度器、块管理器、工作引擎和内存池四大组件,采用动态批处理消除请求阻塞,实现高吞吐与低延迟的统一。
本文介绍了强化学习环境OpenAI Gym的核心概念和使用方法。主要内容包括:1. Agent智能体与Gym环境交互的基本原理;2. 环境安装教程(MuJoCo、Atari等)及测试方法;3. Gym中的空间类型说明;4. Q-Learning算法实现(含Q-Table和DQN两种版本),重点讲解了ε衰减策略和目标网络机制;5. 自定义Atari环境的Wrapper技术,包括NoopReset、M
本文系统介绍了深度学习模型部署的核心技术,重点讲解了ONNX中间表示和TensorRT推理引擎的应用。主要内容包括: 模型部署基础 模型部署的定义与挑战:环境配置和运行效率优化 标准部署流程:深度学习框架→中间表示→推理引擎 关键概念:ONNX格式、计算图静态化 ONNX实践 详细解析torch.onnx.export参数 PyTorch到ONNX的转换方法 ONNXRuntime推理实现 动态输
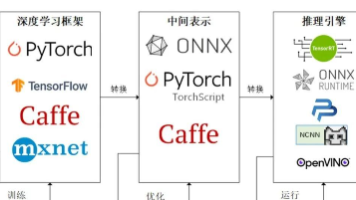
本文系统介绍了深度学习模型部署的核心技术,重点讲解了ONNX中间表示和TensorRT推理引擎的应用。主要内容包括: 模型部署基础 模型部署的定义与挑战:环境配置和运行效率优化 标准部署流程:深度学习框架→中间表示→推理引擎 关键概念:ONNX格式、计算图静态化 ONNX实践 详细解析torch.onnx.export参数 PyTorch到ONNX的转换方法 ONNXRuntime推理实现 动态输
大语言模型推理包含Prefill和Decode两个阶段。Prefill阶段利用GPU并行计算能力,通过矩阵乘法一次性处理完整Prompt序列,实现QKV向量计算、注意力分数计算和信息聚合的高度并行化。而KVCache不能复用是因为每个Token的向量表示会随上下文层层进化,最终存储的是经过多层网络加工后的特定语境状态。
本文系统介绍了基于人类反馈的强化学习(RLHF)技术框架。主要内容包括:1)RLHF数据格式,包含prompt、优质回答(chosen)和劣质回答(rejected)的成对偏好数据;2)奖励模型训练方法,通过Bradley-Terry损失函数学习人类偏好排序;3)PPO算法原理,通过策略裁剪和KL惩罚实现稳定优化;4)DPO算法创新,直接利用偏好数据优化模型而无需复杂强化学习流程。文章详细阐述了从
在聊天场景中,针对用户的问题我们希望把问题逐一分解,每一步用一个工具得到分步答案,然后根据这个中间答案继续思考,再使用下一个工具得到另一个分步答案,直到最终得到想要的结果。这个场景非常匹配langchain工具。在langchain中,我们定义好很多工具,每个工具对解决一类问题。然后针对用户的输入,langchain会不停的思考,最终得到想要的答案。

摘要:本文系统介绍了目标检测中的关键评估指标。首先解析混淆矩阵中的TP、FP、FN、TN概念及其实际含义;其次阐述准确率(衡量预测正样本的准确性)和召回率(衡量检出真实正样本的完整性)的计算方法;然后详细说明IoU(交并比)的定义及其对TP/FP判定的影响机制,包括定位和类别的双重考核标准;最后对比mAP50(IoU阈值为0.5)和mAP50-95(IoU阈值0.5-0.95范围平均)两个指标的区

摘要:OpenAI Triton是一种开源的类Python编程语言和编译器,专为GPU并行计算设计。其核心概念Program相当于CUDA中的线程块,自动处理线程调度和并行化。Triton提供高效的内存访问优化、边界检查机制和JIT即时编译功能,支持TMA硬件加速和持久化内核设计。关键特性包括:1)基于Block粒度的编程模型;2)自动并行化处理;3)L1/L2缓存优化;4)TMA硬件加速数据传输
(1)通过SocketTask = wx.connectSocket创建连接。3、测试发现,websocket性能有问题,有时候几个字的返回要卡半分钟。(4)通过SocketTask.onMessage接收对方发送的消息。(3)通过SocketTask.send发送消息,这个是异步的。(2)通过SocketTask.onOpen打开连接。
