




- @baoyan2015
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
交叉熵是衡量两个概率分布( p )和( q )之间差异的指标。在机器学习中,( p )通常代表真实分布,而( q )代表模型预测的分布。

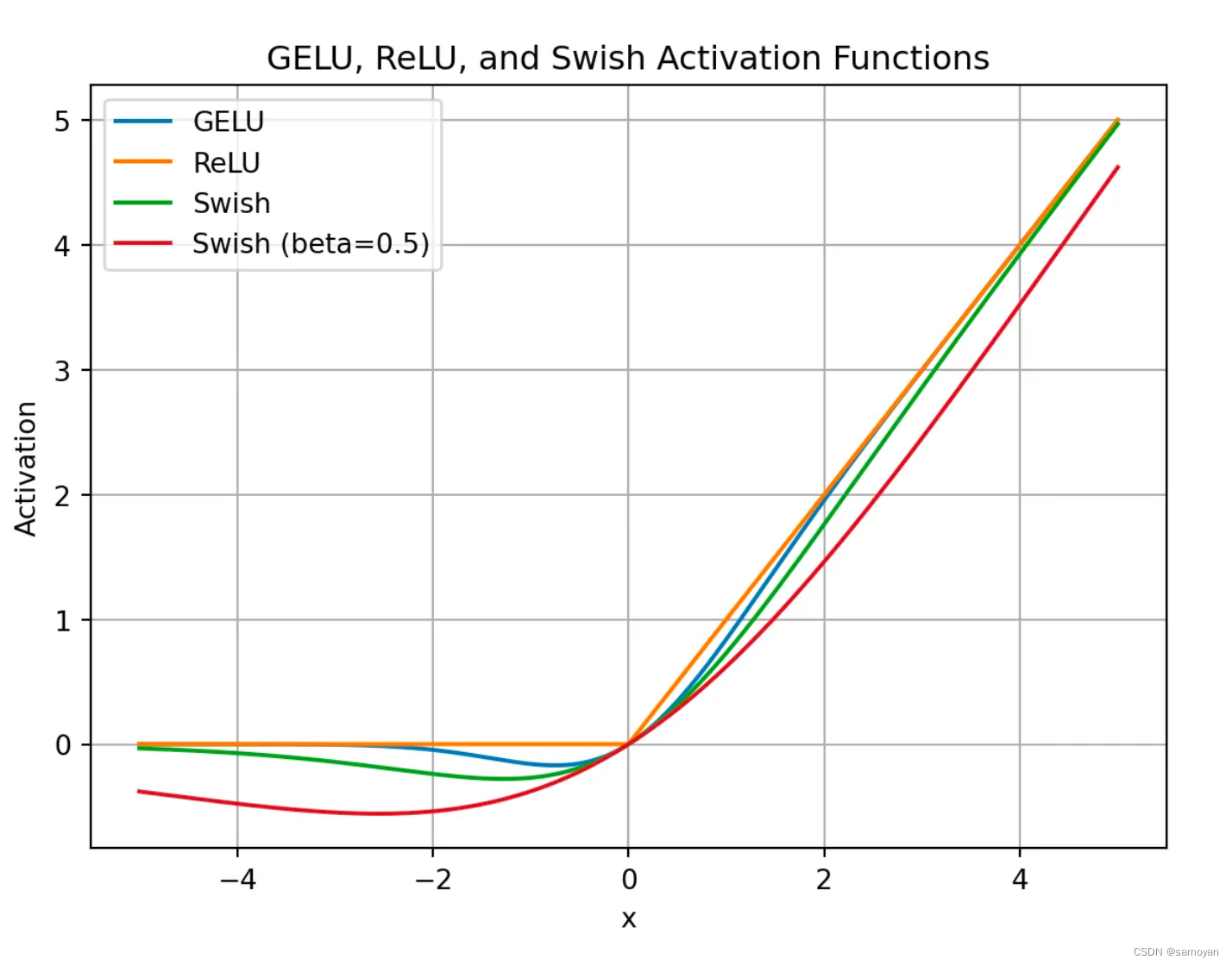
3.3 自适应性:GLU是一种类似于长短期记忆网络(LSTM)带有门机制的网络结构,通过门机制控制信息通过的比例,来让模型自适应地选择哪些单词和特征对预测下一个词有帮助。Swish函数结合了线性函数和非线性函数的特点,能够自适应地调整激活函数的形状,因此在某些深度学习模型中,Swish函数的表现优于常见的ReLU函数。其中,Swish_β(x) = x σ(β x),σ为sigmoid函数,⊗为逐
Scaling Transformers 是一种用于图像生成的神经网络架构,它通过扩展传统的 Transformer 模型来处理大规模数据集和高分辨率图像。这种模型通过改进注意力机制和网络结构,提高了处理大型图像的效率和生成质量。
一文理解CNN、DNN、RNN 内部网络结构区别:http://www.36dsj.com/archives/65643理解 LSTM 网络:http://www.jianshu.com/p/9dc9f41f0b29RNN以及LSTM的介绍和公式梳理:http://blog.csdn.net/Dark_Scope/article/details/47056361深度学习解决局部极值和梯
docker run hello-world出现一下问题,docker: Error response from daemon: OCI runtime create failed: container_linux.go:348:starting container process caused "process_linux.go:297:copying bootstrap data to pip
例如,在InstructGPT项目中,使用PPO算法训练LM时,会计算LM当前输出与初始输出之间的KL散度作为惩罚项。例如,InstructGPT项目中,标注人员会创造性地编写输入提示(比如,“给出五个重燃职业激情的建议”)和对应的输出,覆盖了开放式问答、创意思考、对话和文本重写等多种创造性任务。值得注意的是,在某些情况下,这一步骤可能不是必需的。以InstructGPT为例,标注人员会将模型生成

总结来说,PPO和DPO在算法框架和目标函数上有共同之处,但在实现方式、并行化程度以及适用的计算环境上存在差异,DPO特别适用于需要大规模并行处理的场景。总结来说,PPO专注于通过剪切概率比率来稳定策略更新,而DPO在此基础上引入分布式计算,以提高数据收集和处理的效率,加快学习速度。
在深度学习中,学习率退火是比较常见的,它涉及到在训练过程中逐渐减少学习率。在模型训练中,逐渐减少学习率可以帮助模型在训练早期快速收敛,在训练后期通过更小的步长精细调整,避免过度拟合,从而找到损失函数的全局最优或较好的局部最优解。这可能是因为在退火阶段,模型的学习率较低,能够更精细地适应高质量数据的特点,而且避免了小数据集在长期预训练中的过度使用。通过在退火阶段混合使用高质量数据和通用数据,可以有效
使用fuser命令可以查看哪些进程正在使用指定的文件或目录。在Linux系统中,GPU设备通常被映射到/dev/nvidia*文件中,因此可以使用fuser命令来查看哪些进程正在使用GPU设备。在上述示例中,可以看到/dev/nvidia0设备正在被PID为1234的python进程使用,/dev/nvidia1设备正在被PID为5678的tensorflow进程使用。执行上述命令后,会列出所有正

OpenClaw记忆系统采用本地优先的双层存储架构,以Markdown文件为原始真相层,SQLite为派生索引层。系统分为短期记忆(内存缓存)和长期记忆(Markdown持久化),遵循本地优先原则,不上传云端。社区优化后采用分层架构,包括身份层、活动上下文和档案层,显著降低Token消耗。支持多种向量数据库后端,并提供插件优化记忆管理。核心设计强调透明可编辑,实现从prompt到workspace