




- @ank1983
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
用电商思维做新零售,极致的效率+极致的体验。本以为小米之家从一开始就是复制苹果零售店,结果发现小米之家也走了不少弯路,才重回极致效率的轨道上。极致扁平的结构,这几乎是当前零售业态下的终极模式。数据真实、实时,这样才可能真正实现数据驱动业务。

试了各种办法,重新安装python, pip,matplotlib,kiwisolver都不管用。气死了,死活找不到模块,最终重新安装Microsoft Visual C++ Redistributable,终于解决问题!ImportError: DLL load failed while importing _cext: 找不到指定的模块。

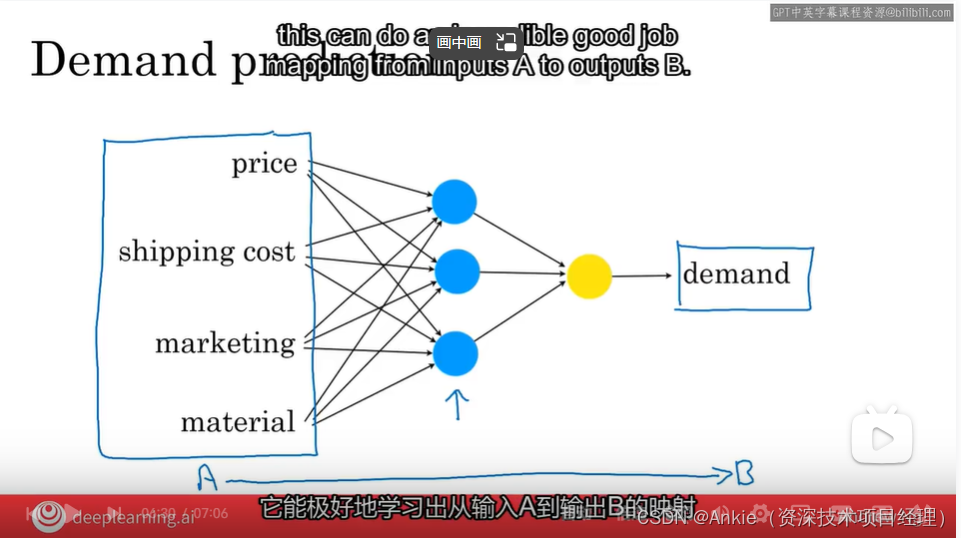
学习-吴恩达《AI for everyone》2019 神经网络的魔法就在于 你并不需要知道神经网络 里面到底在干嘛, 你只需要 给它很多像A这样的图片数据 和像B这样的正确人脸的身份标签, 然后这个学习算法 自己就会弄清楚这中间的 每一个神经元需要计算什么!
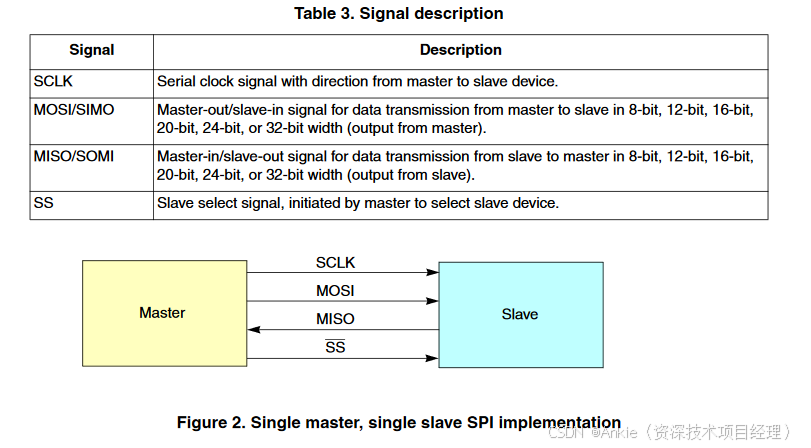
问题一:从设备如何主动向主设备发送数据从 SPI 的硬件结构来看,其标准配置仅有 4 根信号线(MOSI、MISO、SCLK、SS/CS),且主设备控制着片选信号(SS/CS)和时钟信号(SCLK)。如果SS和SCLK一直都使能,从设备可以随时给主设备发送数据。当休眠的时候,从设备需要主动向主设备发送数据时,面临着一个难题:如何通知主设备打开 SS/CS 信号并供应时钟信号,以便进行数据传输?
最近有个临时紧急的需求,要每隔5摄氏度测试高低温,因此必须使用脚本实现自动控制温箱。温箱厂商提供了一个控制APP,是通过串口发命令控制温度,但是我们需要cmd实现自动化。因此,我们通过串口监控抓取了设置温度的字符串,参考了温箱设计文档。在AI的帮助下,快速实现了这个控制脚本。

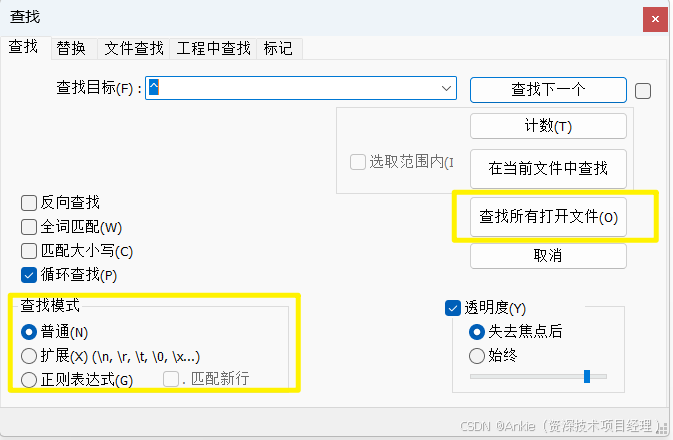
notepad++ 有很多优点:多标签,代码高亮,我最喜欢的是查找和替换。除了可以一次性查找所有打开文件,还可以使用 扩展 or 正则表达式。例如:去掉空行:正则表达式: ^\s*$\r\n
而Sora不仅理解人类的语言和文字,还要通过人类视频深入探索和理解物理世界的运动规律、自然现象等复杂系统,然后模拟出一个虚拟世界。例如下面这个Sora生成的视频,根据以下提示文本生成:在东京的一条街道上,一位时髦的女士自信而随意地走着。她穿着一件黑色皮夹克,一条长长的红裙子,黑色靴子,还提着一个黑色包包。观看Sora生成的视频,其逼真程度令人惊叹,仿佛实际拍摄的作品,展现了其强大的潜力和无限的可能

近30年,人工智能几个关键节点:深蓝,AlphaGo,ChatGPT,Sora。

为什么是自注意力Why Self-Attention?一个是每层的总计算复杂度。另一个是可以并行化的计算量,这通过所需的最少顺序操作数来衡量。第三个是网络中长期依赖关系的路径长度。学习长期依赖关系在许多序列转换任务中是一个关键挑战。影响学习这种依赖关系能力的一个关键因素是前向和后向信号在网络中必须遍历的路径长度。输入和输出序列中任意位置组合之间的这些路径越短,学习长期依赖关系就越容易。因此,我们还

我们探索了在视频数据上大规模训练生成模型。具体来说,我们在可变片长、分辨率和纵横比的视频和图像上联合训练文本条件扩散模型text-conditional diffusion models。我们利用一种 transformer 架构,该架构在视频和图像潜在代码的时空补丁 spacetime patches上运行。我们最大的型号 Sora 能够生成一分钟的高保真视频。我们的结果表明,扩展视频生成模型s
