- @aigchouse
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
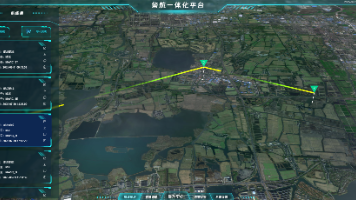
在城市管网巡检的狭窄街巷里,无人机按预设航线自动规避障碍物采集数据;在森林防火的陡峭山区,系统通过气象预警自动触发特巡任务;在公路养护现场,AI 算法实时识别路面裂缝并生成维修工单…… 这些曾经需要大量人工协调的复杂场景,如今正被一款高性价比的无人机巡检平台全面重构。这款源码交付仅需 8 万的智能平台,以 “全流程自动化 + 全场景覆盖 + 低成本落地” 三大优势,成为低空智能巡检项目的优选解决方
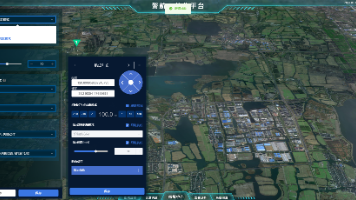
《低空经济驱动的无人机巡检技术革命》 摘要:随着2024年《无人驾驶航空器飞行管理暂行条例》实施,低空经济迎来爆发式发展。无人机巡检作为核心应用,正颠覆传统工业运维模式:通过激光雷达、红外热成像与AI算法,将单次巡检效率提升3倍,人工成本降低60%。四大技术突破(高清成像、AI识别、实时回传、自主规划)支撑五大场景应用(电力、油气、光伏、基建、林业),其中电力巡检缺陷识别率提升28%,光伏热斑检测
在城市管网巡检的狭窄街巷里,无人机按预设航线自动规避障碍物采集数据;在森林防火的陡峭山区,系统通过气象预警自动触发特巡任务;在公路养护现场,AI 算法实时识别路面裂缝并生成维修工单…… 这些曾经需要大量人工协调的复杂场景,如今正被一款高性价比的无人机巡检平台全面重构。这款源码交付仅需 8 万的智能平台,以 “全流程自动化 + 全场景覆盖 + 低成本落地” 三大优势,成为低空智能巡检项目的优选解决方
在城市管网巡检的狭窄街巷里,无人机按预设航线自动规避障碍物采集数据;在森林防火的陡峭山区,系统通过气象预警自动触发特巡任务;在公路养护现场,AI 算法实时识别路面裂缝并生成维修工单…… 这些曾经需要大量人工协调的复杂场景,如今正被一款高性价比的无人机巡检平台全面重构。这款源码交付仅需 8 万的智能平台,以 “全流程自动化 + 全场景覆盖 + 低成本落地” 三大优势,成为低空智能巡检项目的优选解决方
《低空经济驱动的无人机巡检技术革命》 摘要:随着2024年《无人驾驶航空器飞行管理暂行条例》实施,低空经济迎来爆发式发展。无人机巡检作为核心应用,正颠覆传统工业运维模式:通过激光雷达、红外热成像与AI算法,将单次巡检效率提升3倍,人工成本降低60%。四大技术突破(高清成像、AI识别、实时回传、自主规划)支撑五大场景应用(电力、油气、光伏、基建、林业),其中电力巡检缺陷识别率提升28%,光伏热斑检测
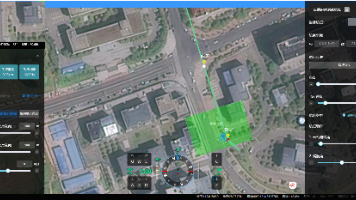
【摘要】无人机智能巡检平台正颠覆传统工业运维模式,通过四大核心技术实现效率革命:1)高清双模成像(红外+激光雷达)精准识别隐患;2)AI模型自动诊断100+类缺陷;3)5G实时回传构建云端决策闭环;4)自主规划毫米级飞行路径。在电力、油气、光伏等领域成效显著:国电网巡检效率提升3倍,光伏热斑识别准确率达99%,油气管道检测响应缩短至15分钟。未来将向AI自主决策、多机协同编队演进,形成"