




- @Zbreakzhong
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
神经网络训练最怕的事情不是模型跑不起来,而是好不容易跑完训练之后发现模型过拟合了无法使用(血的教训),这里记录一下我自己最常用的避免过拟合的方法(并不是完全避免过拟合,只是提供了一种你可以判断是否过拟合的方式)。文章中会给出我自己编写的一个分类神经网络训练模板(GAN和目标检测的以后出),有需要的直接复制之后替换掉一些关键语句即可。下面直接上代码(我尽量都写上注释)!

前言由于最近项目的需要利用深度学习模型完成图像分类的任务,我的个人数据集比较简单因此选用VGG16深度学习模型,后期数据集增加之后会采用VGG19深度学习模型。目录1、VGG16网络2、训练以及需要注意的地方3、测试使用自己的模型进行图像分类正文1、VGG16网络废话不多说import torch.nn as nnclass Vgg16Net(nn.Module):def __init__(sel
零废话,直接上数据集链接和代码

能产生这三种数据的标注工具有很多,本文以最常用的labelme标注工具举例(labelme的安装此处略过,网上也有很多教程,大家可以根据自己的实际情况选择合适的安装教程)。例如此处,我的原图像都放在了data文件夹下,所有标注好的json类型文件都放到了result文件夹下,那么我们就将labelme提供的。的文件,这份文件可以帮助我们将标注好的json类型文件转为图像文件,将其复制到你需要转换j
前言由于最近项目的需要利用深度学习模型完成图像分类的任务,我的个人数据集比较简单因此选用VGG16深度学习模型,后期数据集增加之后会采用VGG19深度学习模型。目录1、VGG16网络2、训练以及需要注意的地方3、测试使用自己的模型进行图像分类正文1、VGG16网络废话不多说import torch.nn as nnclass Vgg16Net(nn.Module):def __init__(sel
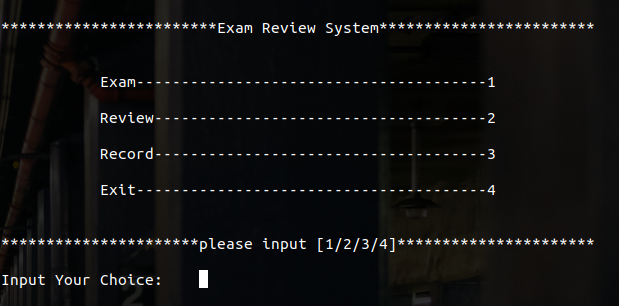
Linux Bash Shell语言 考试系统(纯Shell脚本,带虚拟机共享文件夹配置教程)项目开源地址:Linux-Shell-Exam-System本项目基于Linux Bash Shell脚本语言实现,代码当中有详细的注释,几乎每一行都打上了,还有不清楚的欢迎大家目录题目要求虚拟机配置共享文件夹代码下载实现效果题目要求基于Linux系统,使用bash shell语言设计一款功能完善、性能良
pyhton基于PocketSphinx实现简单语音识别源码网址:PocketSphinx_Speech_Recognition一、实现环境系统环境:win 10编译环境:Pycharm 2020.1.4 x64编程语言:python3.8.3依赖库的版本:SpeechRecognition3.8.1PocketSphinx0.1.15PyAudio0.2.11Numpy1.18.1Scipy1.