




- @YBK233
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
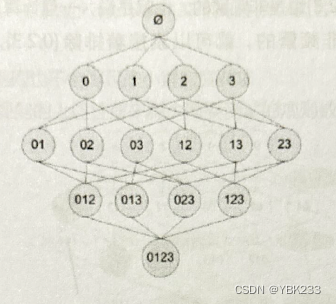
第一次遍历,对所有单项的支持度进行计数,并确定频繁项;在后续的每次遍历中,利用上次遍历所得频繁项集作为种子项集,产生新的频繁项集-候选项集,并对候选项集的支持度进行计数,在本次遍历结束时统计满足最小支持度的候选项集,本次遍历对应的频繁项集就算是确定了,这些频繁项集又成为下一次遍历的种子;例如:在7条记录中,购买牛肉的记录有4条,在4条记录中又有3条记录显示购买了鸡肉,即R:牛肉→鸡肉的置信度为3/
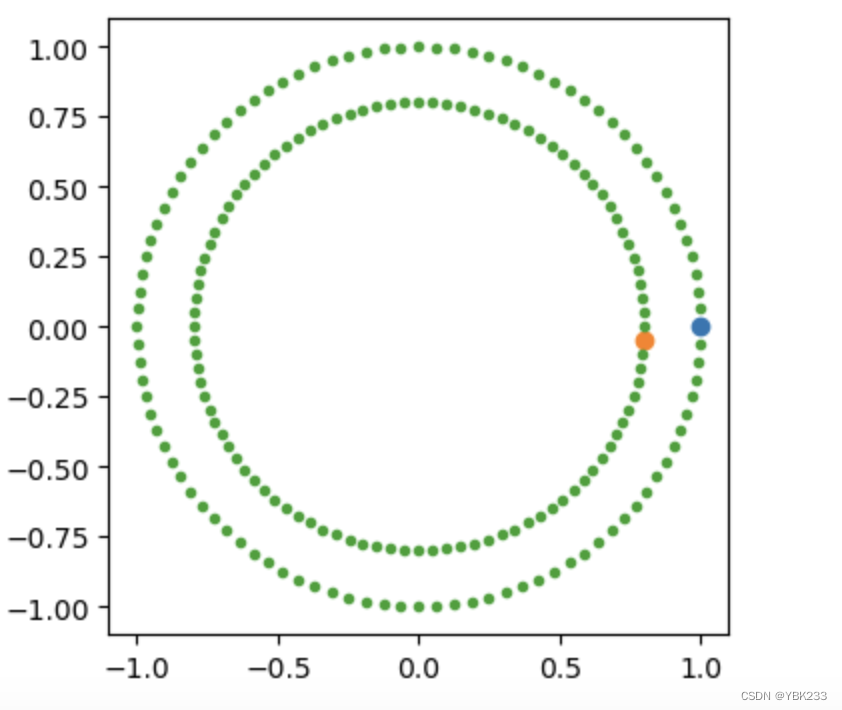
半监督学习(Semi-Supervised Learning,SSL)是机器学习领域中的一个重要分支,它结合了监督学习和无监督学习的思想,用于处理标签数据稀缺而无标签数据丰富的场景。Self Training自训练Label Propagation标签传播Label Spreading标签扩散Self Training自训练是一种简单的半监督学习方法,它首先使用已标记的数据训练一个监督学习模型。然
注意:在Hadoop集群搭建完成的基础上进行此种操作;我是三台虚拟机同时进行安装操作,当然也可以通过scp方式进行虚拟机直接文件的传递,在此不表。首先安装scala下载地址:https://www.scala-lang.org/download/根据自己需要进行选择,我选择的是scala-2.12.7.tgz,然后将安装包放到共享目录下1、创建镜像容器 -P将容器的所有端口映射到主机端口...
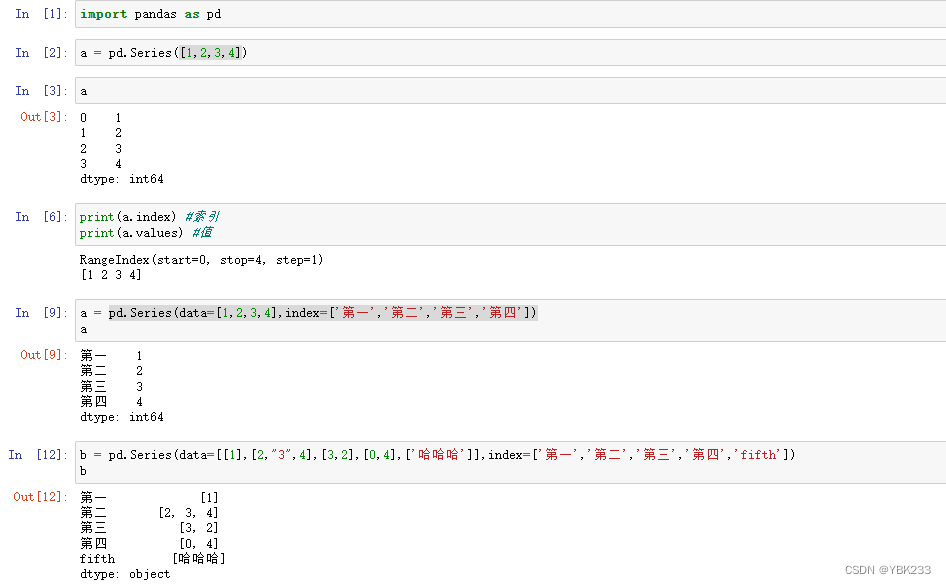
pandas有两种基本对象:Series、DataFrameseries和字典非常类似,我们可以将index看成key,对应值为value如果在series中找不到要找的值,则返回预设的默认值。
决策报表的制作大致步骤是:新建决策报表→选中模板主题→新建数据集→拖拽组件→设计组件→报表预览(得分:2分 满分:2分)决策报表设置为横向自适应时,在不同屏幕分辨率下,单页显示不全时,纵向会出现滚动条(得分:2分 满分:2分)决策报表中,其他组件引用报表块中的单元格数据,也可以引用数据集中的数据(得分:2分 满分:2分)用户管理可以通过三种形式添加用户:手动添加用户、导入用户、同步用户(得分:2分

研究算法时均认为数据是对称分布的,即正负样本数据相当。现实数据中少数类占比20%,甚至10%都不到,容易对模型算法产生影响。sampling_strategy: default= "auto" 过采样策略,可以为0.5,即调整样本比例为0.5倍;minority:只过采样类别比例最少的样本,多分类时用;not_minority出了最少、最多的样本,其他类别过采样,过采样到和最多类别的样本数量一样多

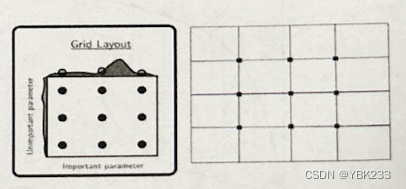
网格搜索(grid search)是一种用来选择模型超参数的方法。它通过遍历超参数的所有可能组合来寻找最优的超参数。通常,网格搜索和交叉验证结合使用,以便在选择超参数时考虑模型的泛化能力。如图,每个格子都是一组参数,使用交叉验证测试参数效果。但是效率低下。HalvingGridSearchCV使用连续减半搜索策略来评估指定的参数值。搜索开始时,使用少量资源(默认为样本数量)评估所有候选参数组合,并
个人建议:在anaconda环境下安装scrapy框架安装anaconda1.从清华镜像站下载anaconda网址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/64位虚拟机版本:Anaconda3-5.1.0-Linux-x86_64.sh64位Windows版本:Anaconda3-5.1.0-Windows-x...