




- @XueFarah
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文记录一次 NemoClaw 有状态 Agent 迁移实践:为 Hermes 仓库日报助手创建快照,恢复到新沙箱,并通过 Skill、会话、路由、Dashboard 和实际推理逐项验证迁移结果。
数据集的结构如下:在实际应用场景中,由于训练数据集不足,所以很少有人会从头开始训练整个网络。普遍的做法是,在一个非常大的基础数据集上训练得到一个预训练模型,然后使用该模型来初始化网络的权重参数或作为固定特征提取器应用于特定的任务中。本章将使用迁移学习的方法对ImageNet数据集中的狼和狗图像进行分类。下载案例所用到的,数据集中的图像来自于ImageNet,每个分类有大约120张训练图像与30张验

K近邻算法(K-Nearest-Neighbor, KNN)是一种用于分类和回归的非参数统计方法,最初由 Cover和Hart于1968年提出(Cover等人,1967),是机器学习最基础的算法之一。它正是基于以上思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计出这些样本的类别并进行投票,票数最多的那个类就是分类的结果。KNN的三个基本要素:K值,

与传统方法不同,MusicGen采用单个stage的Transformer LM结合高效的token交织模式,取消了多层级的多个模型结构,例如分层或上采样,这使得MusicGen能够生成单声道和立体声的高质量音乐样本,同时提供更好的生成输出控制。MusicGen不仅能够生成符合文本描述的音乐,还能够通过旋律条件控制生成的音调结构。MusicGen是来自Meta AI的Jade Copet等人提出的

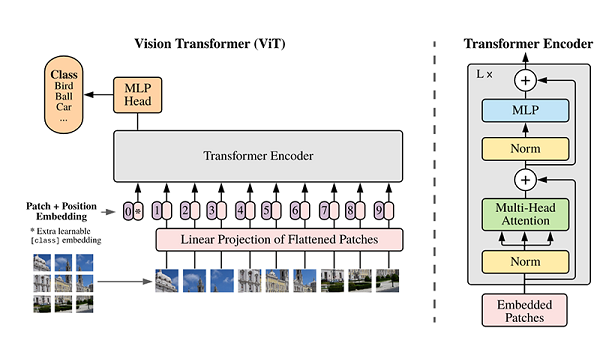
近些年,随着基于自注意(Self-Attention)结构的模型的发展,特别是Transformer模型的提出,极大地促进了自然语言处理模型的发展。由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。ViT则是自然语言处理和计算机视觉两个领域的融合结晶。在不依赖卷积操作的情况下,依然可以在图像分类任务上达到很好的效果。
序列标注指给定输入序列,给序列中每个Token进行标注标签的过程。序列标注问题通常用于从文本中进行信息抽取,包括分词(Word Segmentation)、词性标注(Position Tagging)、命名实体识别(Named Entity Recognition, NER)等。输入序列清华大学座落于首都北京输出标注BIIIOOOOOBI如上表所示,清华大学和北京是地名,需要将其识别,我们对每个输

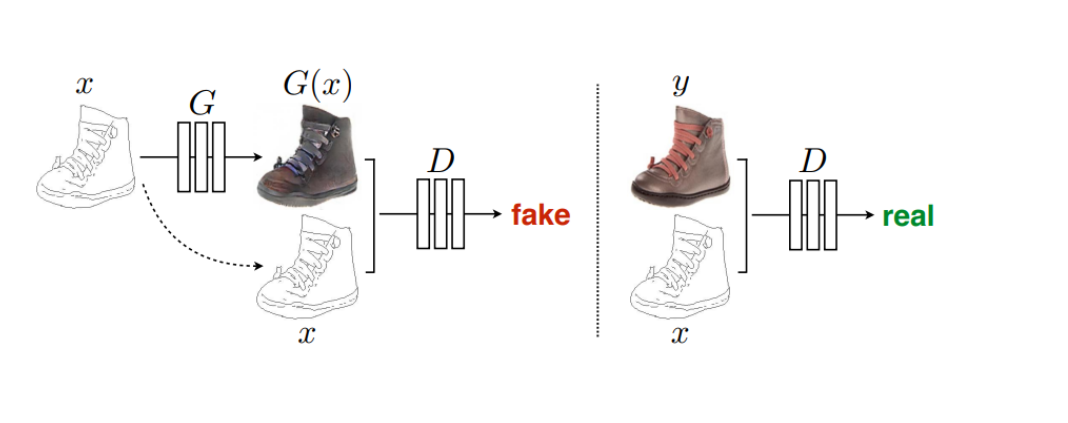
Pix2Pix是基于条件生成对抗网络(cGAN, Condition Generative Adversarial Networks )实现的一种深度学习图像转换模型,该模型是由Phillip Isola等作者在2017年CVPR上提出的,可以实现语义/标签到真实图片、灰度图到彩色图、航空图到地图、白天到黑夜、线稿图到实物图的转换。和。传统上,尽管此类任务的目标都是相同的从像素预测像素,但每项都是
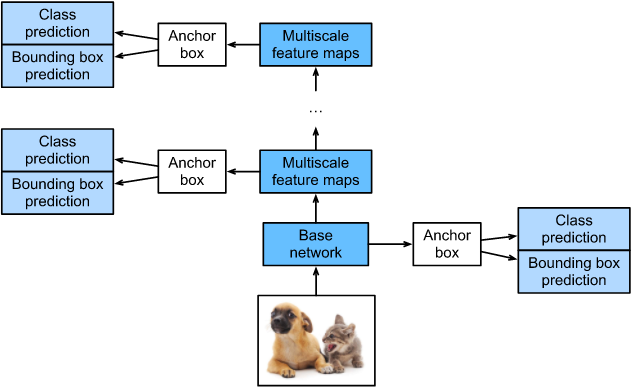
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法。使用Nvidia Titan X在VOC 2007测试集上,SSD对于输入尺寸300x300的网络,达到74.3%mAP(mean Average Precision)以及59FPS;对于512x512的网络,达到了76.9%mAP ,超越当时最强的Faster R
MNIST手写数字数据集是NIST数据集的子集,共有70000张手写数字图片,包含60000张训练样本和10000张测试样本,数字图片为二进制文件,图片大小为28*28,单通道。图片已经预先进行了尺寸归一化和中心化处理。本案例将使用MNIST手写数字数据集来训练一个生成式对抗网络,使用该网络模拟生成手写数字图片。
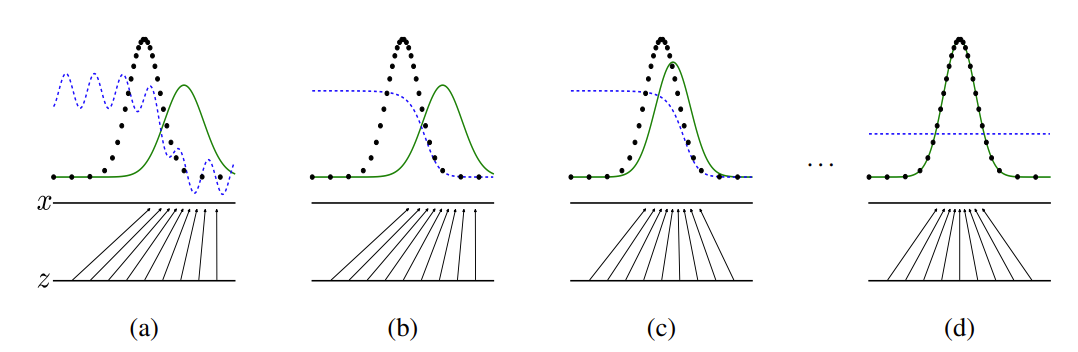
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。Diffusion对于图像的处理包括以下两个过程:我们选择的固定(或预定义)正向扩散过程qqq:它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声一个学
