




- @Wufjsjjx
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作为一名程序员,我立刻对这些招聘数据做了详细分析。接下来,我要用实打实的数据告诉你:为什么说现在是Java程序员+AI双修工程师最佳时机,以及如何抓住这波机会。
这篇指南会把这个概念彻底掰开揉碎,变成你动动鼠标就能完成的简单操作。准备好,我们要开始给你的 n8n换上强大的“中国芯”了!

担心本地部署需要写代码?别慌!这两款工具全程无需一行代码,点击鼠标就能让 DeepSeek 在你电脑里 “安家”。
DeepSeek 作为一款备受关注的模型,通过本地部署结合 Cherry Studio,能为用户带来高效、安全且个性化的 AI 体验。
LLaMA-Factory 是一个国内北航开源的低代码大模型训练框架,专为大型语言模型(LLMs)的微调而设计。

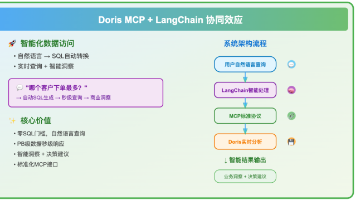
MCP协议的引入恰巧能简化这些问题。该协议定义了AI应用与外部数据源之间的标准化通信接口,使得不同系统能够通过统一的方式进行数据交换。
在成功部署 ChatGPT 模型的基础上,用咱们国产的大模型 ChatGLM ,以及 LangChain 开源框架搭建“个人专属知识库”。
微软上架了免费的生成式AI入门课程——Generative AI for Beginners。这套课程主打“新手友好”,不需要太深的技术背景,带你从零开始,一步步搞懂生成式AI应用的原理。
本文参考网上资料学习,IDEA接入DeepSeek+私有化部署DeepSeek+Dify搭建智能助手+接入微信(个人电脑Windows和mac都可以安装),手把手保姆级教程。
Prompt Engineering 就是设计和优化与AI对话的“提示词”或“指令”,让AI能准确理解并提供有用的回应。
