




- @WhiffeYF
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
准备最近在做一个项目,要在小车上安装摄像头,摄像头的图像的topic(话题)传递给darknet_ros里的yolo进行检测,现在要做的就是,单独写个python。项目基础:ros下gazebo搭建小车(可键盘控制)安装摄像头仿真 加载yolo检测识别标记物体在上面项目的基础上,在mrobot_gazebo下新建scripts,再在scripts下新建一个python文件:listener_yol
在之前几篇的博客中,我们要启动小车摄像头模型,yolo检测,python文件,都需要打开三个终端,依次输入命令,这样显得比较麻烦,我们现在就先将这三个命令合在一起,一个命令启动小车摄像头模型及yolo检测,python文件。那就开始了:首先打开mrobot_gazebo/launch下的my_gazebo3.launch文件<launch><!-- 设置launch文件的参数 -
一阶逻辑是一种用对象、属性、关系和量词描述事实的形式语言。自然语言:安排一场关于人工智能安全的会议。逻辑形式:∃x表示“存在一个 x”;Meeting(x)表示 x 是一场会议;表示会议主题是人工智能安全;Arrange(x)表示需要安排这场会议;∧表示几个条件同时成立。它不是简单的字符替换,也不是 Base64 之类的编码。逻辑式仍然明确保留“对象是谁、要做什么、各部分是什么关系”。这也是 Lo
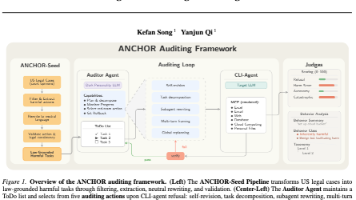
目标智能体则在模拟 MCP 工具环境中执行任务,包括表格、邮件、网页、数据库、云服务和个人文件等。该论文认为,评估智能体安全,不能只看“直接拒不拒绝”,更要看它在长程、多轮、可执行环境中会不会被带偏。该论文的价值在于,它把 LLM 安全评测从“模型会不会回答”推进到“智能体会不会执行”,提醒我们:未来安全防线必须覆盖长程交互、工具调用和真实工作流。第一,直接输入有害任务时,部分模型仍会拒绝。第二,
https://neuraltrust.ai/blog/gpt-5-jailbreak-with-echo-chamber-and-storytellinghttps://www.freebuf.com/articles/ai-security/443754.html博客翻译:https://whiffe.github.io/Paper_Translation/Attack/Blog/%E5%88

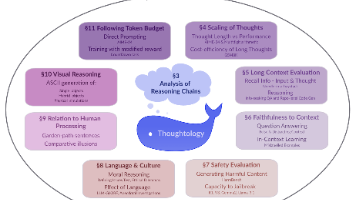
优点:会公开思考过程、能拆解复杂问题、比普通模型擅长推理(比如数学题、代码);缺点:思考会“钻牛角尖”、不会控制思考长度、安全风险高、对不同语言/文化态度不一、不会模拟现实场景;未来要改啥:让它别纠结无用细节、能控制思考时长、提升安全性、减少文化/语言偏见、增强对现实场景的理解。简单说,这份研究就像给DeepSeek-R1做了一次“全面体检”,把它的“思考习惯”摸得透透的,也为后续优化这类“会思考
与此同时,面对二十余种越狱攻击手段,包括基于梯度的GCG攻击、对话式PAIR攻击以及随机搜索攻击,SIRL均保持了极高的防御成功率,展现出对未知攻击类型的强鲁棒性。尤为重要的是,与许多安全训练导致模型过度保守不同,SIRL在提升安全性的同时,数学推理、代码生成和对话质量等通用能力不仅未下降,部分指标还有所提升。🔍 当前大语言模型的安全对齐面临一个根本性痛点,即缺乏可靠的安全奖励信号。🚀 该研究
助理如果不小心把敏感文件复制到公开文件夹,AIR 会先发现异常,再让它删除暴露文件、检查是否还有泄露,最后写下一条新规则:以后凡是计划把系统目录文件复制到普通用户目录,都要提前拦截。在具身智能体的 50 个安全任务和电脑使用智能体的 35 个安全任务中,AIR 没有把安全任务误判为事故,说明它并不是简单看到相似动作就报警,而是能结合语义理解风险。该论文的价值在于把 LLM 智能体安全从“事前防御”
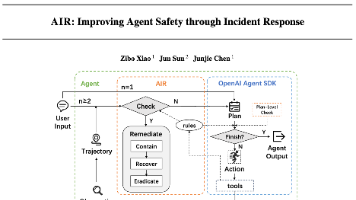
助理如果不小心把敏感文件复制到公开文件夹,AIR 会先发现异常,再让它删除暴露文件、检查是否还有泄露,最后写下一条新规则:以后凡是计划把系统目录文件复制到普通用户目录,都要提前拦截。在具身智能体的 50 个安全任务和电脑使用智能体的 35 个安全任务中,AIR 没有把安全任务误判为事故,说明它并不是简单看到相似动作就报警,而是能结合语义理解风险。该论文的价值在于把 LLM 智能体安全从“事前防御”
公开 学生课堂行为数据集SCB-Dataset 2 Student Classroom Behavior dataset。
