




- @Toky_min
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
异常报告消息 org.apache.jasper.JasperException: java.lang.ClassNotFoundException: org.apache.jsp.index_jsp描述 服务器遇到一个意外的情况,阻止它完成请求。Exceptionorg.apache.jasper.JasperException: org.apache.jasper.Jaspe...
Physical Intelligence公司推出的π₀模型代表了通用机器人策略领域的重大进展。这款融合视觉-语言-动作三模态的基础模型,通过8种不同机器人收集的多样化数据集训练,具备执行复杂物理任务的能力。π₀创新性地结合互联网规模预训练知识和实时动作输出功能,在衣物折叠、餐桌清理等传统难题上展现出超越专用模型的性能。测试显示,π₀在五项评估任务中均显著优于OpenVLA等现有模型。这一突破为机
本文提出了一种新型量化技术——半二次量化(HQQ),用于解决大型机器学习模型部署中的内存需求问题。该方法无需校准数据,通过引入稀疏促进损失和半二次求解器,在保持与GPTQ等校准方法相当压缩质量的同时,显著提升量化速度。实验显示,HQQ量化Llama-2-70B仅需5分钟(比GPTQ快50倍),且2位量化模型的性能优于全精度Llama-2-13B。在视觉Transformer测试中,HQQ同样展现出
Microsoft Word很抱歉,无法打开文档,因为内容有问题。确定详细信息(D)详细信息xml 字符非法。位置:行:3,列:2439。

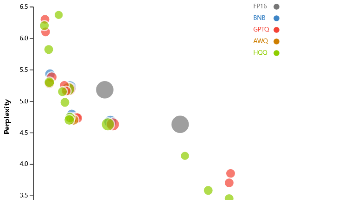
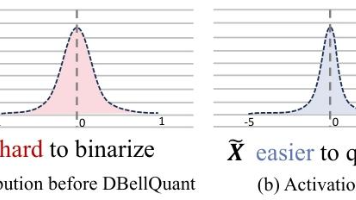
摘要:本文提出DBellQuant框架,通过创新的双钟形可学习变换(LTDB)算法实现大语言模型(LLM)的高效训练后量化。该方法将单钟形权重分布转换为更适配二值化的双钟形分布,同时通过逆变换平滑激活值异常值。实验表明,DBellQuant在保持模型性能的同时,首次实现近1位权重压缩与6位激活量化。在LLaMA2-13B等模型上,其困惑度(14.39)显著优于现有方法(21.35),为LLM的高效
摘要:大型语言模型(LLMs)的快速发展推动了自然语言处理领域的重大进步,但其大规模部署仍面临计算、内存和能效等挑战。本文系统综述了剪枝、量化、知识蒸馏和神经架构搜索(NAS)等最先进的压缩技术,这些技术可有效减小模型规模、提高推理速度并降低能耗。研究提出了一个整合传统指标(如准确率和困惑度)与高级标准(延迟-准确率权衡、参数效率、多目标优化等)的评估框架,并探讨了公平感知压缩、对抗性鲁棒性和硬件
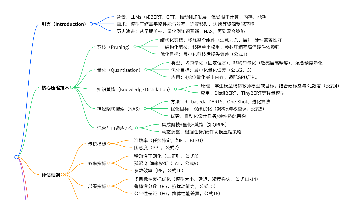
当前主流的大模型架构主要分为三类:1)Encoder-Decoder结构(如T5、BART),擅长理解类任务;2)CausalDecoder结构(如LLaMA),适合文本生成;3)PrefixDecoder结构(如ChatGLM),在对话场景表现突出。其中Decoder-only结构凭借简单高效、适配性强等优势成为主流选择。 在训练机制上,CausalDecoder对所有token计算损失,而Pr
为了确定最有效的生成风格,我们通过训练 1.8B 模型进行了对比实验,其中我们使用不同的 Cosmopedia v1 子集数据,共计有 80 亿 token 的数据量。SmolLM-1.7B 还在 Python 编程能力上表现抢眼 (我们测评的 Qwen2-1.5B 分数和 Qwen 团队给出的不同,我们的实验配置是: temperature 设为 0.2,top-p 设为 0.95,样本量为 2
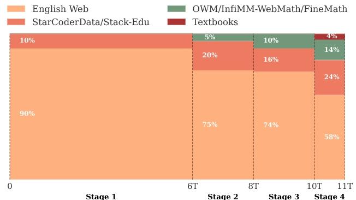
虽然大语言模型在人工智能的许多应用中取得了突破,但其固有的大规模特性使得它们在计算上成本高昂,并且在资源受限的环境中部署具有挑战性。在本文中,我们记录了SmolLM2的开发过程,这是一种最先进的 “小型”(17亿参数)语言模型(LM)。为了获得强大的性能,我们使用多阶段训练过程,在约11万亿个词元的数据上对SmolLM2进行过度训练,该过程将网页文本与专业的数学、代码和指令跟随数据混合在一起。此外
继续学习SmolLM模型概述SmolLM 是一系列小型语言模型,有三种规模:参数数量分别为 1.35 亿、3.6 亿和 17 亿。这些模型在 SmolLM 语料库上进行训练,该语料库是经过精心整理的高质量教育及合成数据集合,专为训练大语言模型而设计。更多详细信息,请参阅我们的博客文章。为构建 SmolLM-Instruct,我们在公开可用的数据集上对基础模型进行了微调。变更日志版本发布描述v0.1
