- @Rabbit_QL
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Docker的网络设置踩坑记录
本文记录了一次Git分支冲突的解决过程。作者在推送调试日志时遇到分支分叉问题,Git提示需要协调分歧分支。文章详细解释了三种处理策略:merge(安全但产生额外提交)、rebase(整洁但需谨慎)和fast-forward(理想但苛刻)。作者最终选择rebase策略,因为它能保持提交历史的线性整洁,并通过实际操作为读者展示了rebase的具体步骤和注意事项。文章最后建议将pull.rebase设为

Git Reset 的本质与边界:何时该用,何时不该用 Git reset 常被视为危险命令,但关键在于理解其作用原理。Git 存在三个层次:提交历史、暂存区和工作区。reset 的本质是移动 HEAD 指针,并根据三种模式(--soft/--mixed/--hard)决定是否同步暂存区和工作区。 --soft 保留改动到暂存区,适合修改提交信息;--mixed(默认)保留改动但需重新 add,适

Git revert的设计理念:尊重历史而非抹去错误 摘要: git revert常被认为反直觉,因为它不删除错误提交,而是通过新增提交来抵消影响。这种设计体现了Git的核心价值观:已发生的代码变更应被如实记录而非抹去。在协作场景中,git revert保留了完整的因果链条,确保历史可追溯、可解释。与git reset不同,revert不会修改已有提交,只是追加修正记录,这使得它成为共享分支上最安

本文分析了单轮与多轮大模型API调用的区别及其Token成本。单轮请求是无状态的独立调用,模型仅处理当前输入。多轮对话通过显式拼接历史消息实现上下文连续性,其中assistant角色内容需手动传入。这种方式虽然简单,但会导致Token成本随轮数线性增长,尤其对长对话影响显著。文章强调模型本身无记忆能力,上下文连续性完全依赖输入Token构造,为后续优化技术(如缓存、压缩等)提供了理论基础。
本文介绍了使用Claude CLI工具时的关键第一步——执行/init命令。文章指出,许多用户会直接让Claude优化代码,却忽略了初始化项目上下文的重要性。/init命令会引导Claude识别项目类型(如Git仓库、语言框架等),建立项目级上下文,从而避免后续出现理解偏差。执行该命令后,Claude会生成包含项目概览、架构说明等信息的文档,为后续协作提供基础。作者强调,先让Claude"

本文介绍了从零开始构建生产级LLM API调用架构的实战指南。首先分析了API调用的必要性,大模型正成为基础设施服务(Model-as-a-Service),支持智能客服、报告生成等场景。然后详细讲解了OpenAI API的调用方法,包括获取API Key、Python代码示例和LLM API调用方式,并深入解析了Client对象和Prompt的工程意义。最后介绍了企业级模型服务Ark的调用方式,
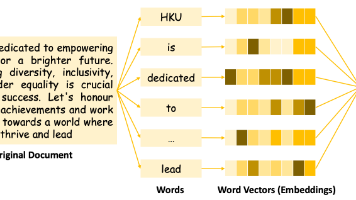
本文介绍了大语言模型中的Tokenization(分词)技术,它是将自然语言文本转换为机器可处理数字序列的关键预处理步骤。文章首先阐述了分词的基本概念和作用,指出词元(Token)是模型处理的最小单元,并通过嵌入(Embedding)转换为数值向量。随后详细解析了分词的完整流程:文本标准化、分词、数值编码和嵌入映射,其中重点说明了文本标准化的具体方法(大小写转换、Unicode归一化、标点移除等)
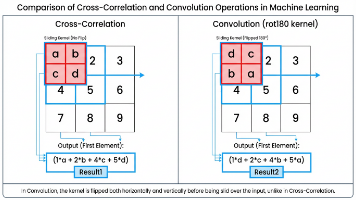
摘要:本文分析了卷积神经网络中互相关与卷积的数学区别。
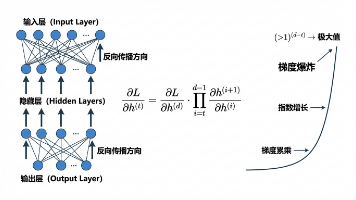
本文深入解析了深度学习中的梯度爆炸问题。梯度爆炸指反向传播时梯度值指数级增长,导致数值溢出和训练不稳定。其核心原因是深层网络梯度链式乘积中权重矩阵范数大于1时的累乘效应,尤其在ReLU激活函数下梯度路径筛选会放大该问题。数学推导和实验表明,即使初始梯度正常,连续矩阵相乘也会快速引发数值爆炸。梯度爆炸会导致浮点数溢出、参数更新失控等问题,严重影响模型训练。理解这一现象的成因有助于设计更稳定的网络结构