- @NCU_wander
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
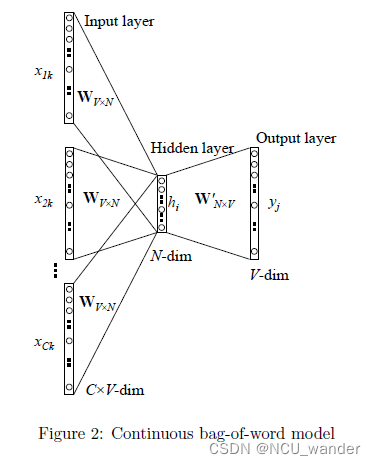
线上推理时,需要对召回的每个候选集都和 Query 一起输入模型计算,速度较慢(适合小批量数据)。对于双塔结构,其实本质上是说有一个并行的网络结构,结构上是两个独立的子网络(塔),分别处理 查询(Query)和候选(Candidate) 的特征,最后通过向量相似度(如内积、余弦相似度)计算匹配分数。T5 摒弃了 BERT 的 MLM(掩码语言模型)和 GPT 的 CLM(因果语言模型),采用了全新
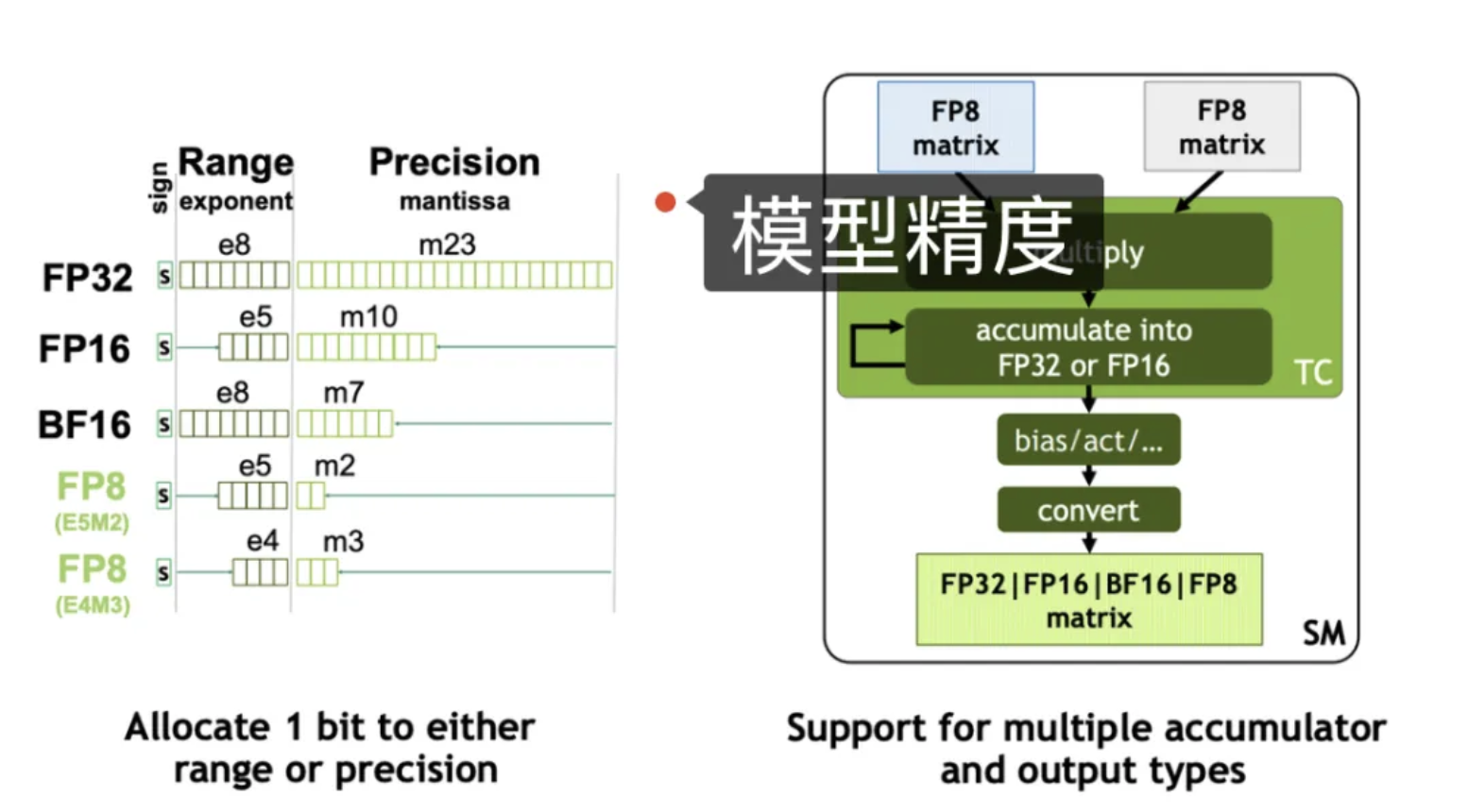
W8A8 代表 权重(Weights)和激活值(Activations)均被量化为 8 位(INT8 或 UINT8),常用于深度学习推理,以减少模型的存储、计算需求,并提升硬件执行效率。W8(8-bit Weights):将神经网络的权重从 32 位浮点(FP32)转换为 8 位整数(INT8)。A8(8-bit Activations):将神经网络的激活值从 32 位浮点(FP32)转换为 8
第一张图是比较经典的RAG知识图谱,第二张图是更加详细扎实的介绍图。

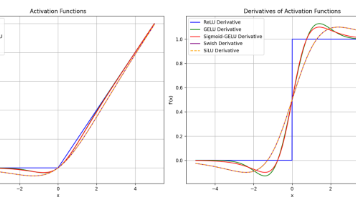
今天学习到很有启发性的一句话,gate本身也是一种attention,只是计算的level不同。言归正传,复盘总结一下大模型中常见的激活函数和归一化函数。
深度学习算法的效果离不开高质量数据集,因此在此对项目中用到的经典数据集进行梳理,本帖长期更新。1、TID2008TID2008是由乌克兰国家航空航天大学的N504信号接收、传输与处理系建立,包括25幅参考图像,四种不同变换幅度,1700幅失真图像。失真类型有17种包括:加性高斯噪声、颜色分量强于照明分量的加性噪声、空间位置相关噪声、掩膜噪声、高频噪声、脉冲噪声、量化噪声、高斯模糊、图像噪声、J..
验证加速核心:大模型通过「1次并行批量验证K个Token」替代「K次串行生成Token」,单批次验证耗时远小于逐Token生成总耗时;额外保障:小模型生成草稿的耗时极低,回滚机制仅修正错误不重复计算,进一步放大加速效果;关键结论:验证阶段的“批量并行”是投机解码(MTP)提速的核心,也是为什么“验证K个Token”比“生成K个Token”快一个数量级的根本原因。
IP 开通端口访问,只是给设备「进门的资格」(能连接 Broker);订阅和发布是「进门后的操作权限」,由 Broker 的 ACL、数据库权限等规则独立控制;「能订阅」和「能发布」没有必然关联,生产环境中更推荐「最小权限原则」:例如传感器仅允许发布数据主题,控制端仅允许订阅指令主题,避免权限滥用。
本质是copy每一份模型,所以一般而言要求模型吃显存不过大,同时显卡本身尽量大显存,保证每张显卡可以复制一份模型。PP 是把 模型的层级顺序切分成多个阶段(stage),每个阶段放到不同 GPU 上,然后用 流水线方式并行处理多个 batch。缺点:每个 stage 依赖前一 stage 输出,pipeline fill/drain 会有延迟,batch 小时效率低。模型包含多个 Expert 子
第一张图是比较经典的RAG知识图谱,第二张图是更加详细扎实的介绍图。
这一段时间大模型的相关进展如火如荼,吸引了很多人的目光;本文从nlp领域入门的角度来总结相关的技术路线演变路线。