




- @MrJoice
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
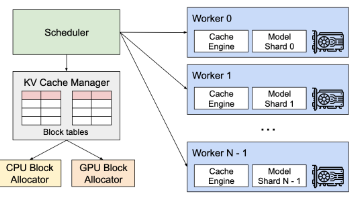
摘要:PagedAttention是vLLM系统中的创新技术,通过借鉴操作系统分页机制优化大语言模型的KV缓存管理。传统KV缓存存在内存碎片化、利用率低等问题,导致GPU内存浪费严重。PagedAttention将KV缓存分块存储,按需动态分配非连续内存块,通过块表实现逻辑连续映射。该技术修改了注意力计算内核,支持分页KV缓存的高效访问,显著提升内存利用率至96%以上。实验表明,相比传统方法,Pa
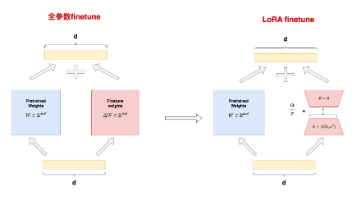
《LoRA微调技术解析与实践》 摘要:本文介绍了参数高效微调方法LoRA(Low-Rank Adaptation)的原理与应用。针对传统微调面临的高资源消耗问题,LoRA通过在原始模型权重旁添加两个可训练的低秩矩阵,仅需微调少量参数(实验显示仅1.56%)即可获得良好效果。文章详细阐述了LoRA的技术实现,包括冻结原始权重、低秩矩阵乘积计算和缩放因子设计。通过中文诗歌数据集对GPT2模型进行微调的
模型量化技术详解 模型量化是AI领域解决大模型显存和算力挑战的关键技术。随着模型参数规模从亿级增长到万亿级,FP32/FP16精度带来的显存占用和计算成本已难以承受。量化通过将高精度浮点数映射到低精度整数(如INT8/INT4),实现模型压缩和加速。其核心公式为x_int=round(x_float/scale)+zero_point,通过scale和zero_point调整数值范围。量化分为训练
模型量化技术详解 模型量化是AI领域解决大模型显存和算力挑战的关键技术。随着模型参数规模从亿级增长到万亿级,FP32/FP16精度带来的显存占用和计算成本已难以承受。量化通过将高精度浮点数映射到低精度整数(如INT8/INT4),实现模型压缩和加速。其核心公式为x_int=round(x_float/scale)+zero_point,通过scale和zero_point调整数值范围。量化分为训练
模型量化技术详解 模型量化是AI领域解决大模型显存和算力挑战的关键技术。随着模型参数规模从亿级增长到万亿级,FP32/FP16精度带来的显存占用和计算成本已难以承受。量化通过将高精度浮点数映射到低精度整数(如INT8/INT4),实现模型压缩和加速。其核心公式为x_int=round(x_float/scale)+zero_point,通过scale和zero_point调整数值范围。量化分为训练
在大语言模型(LLM)驱动的应用浪潮中,检索增强生成(Retrieval-Augmented Generation, RAG) 技术已成为连接模型与海量外部知识的桥梁,极大地提升了AI生成内容的事实性和准确性。但是,传统的RAG也有缺陷,它在面对用户意图模糊或表达方式多样的查询时,常常会遇到瓶颈。不过幸运的是,有人提出了RAG-Fusion这一技术,可以很大成大的改善这种困境。本文将从底层原理到实
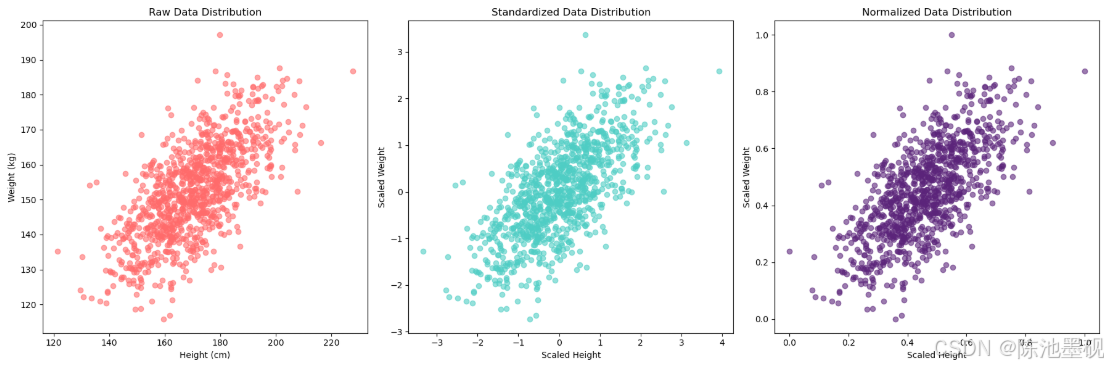
特征缩放是将不同量纲或范围的特征数据,通过数学变换映射到统一量纲区间(通常为[0, 1]或[-1, 1]的过程)。类比:把不同货币统一换算成人民币,让所有特征站在同一起跑线上目标说明类比消除量纲差异让kg和cm等不同单位具有可比性把人民币和美元换算成黄金平衡特征权重防止大范围特征(如薪资)压制小范围特征(如年龄)拳击比赛按照选手的体重分级加速模型收敛优化损失函数形状把崎岖山路("之字形")改造成高
本文记录了将FreeType库移植到鸿蒙系统的完整过程。作者首先在Windows环境下配置HarmonyOS SDK,通过CMake编译FreeType为动态库。随后创建Native工程,将编译好的库集成到项目中,并开发了文字渲染为PNG图片的功能(使用stb_image_write库)。文章详细探讨了应用沙箱目录与rawfile目录的区别,解释了为何需要将字体文件从rawfile复制到沙箱目录。

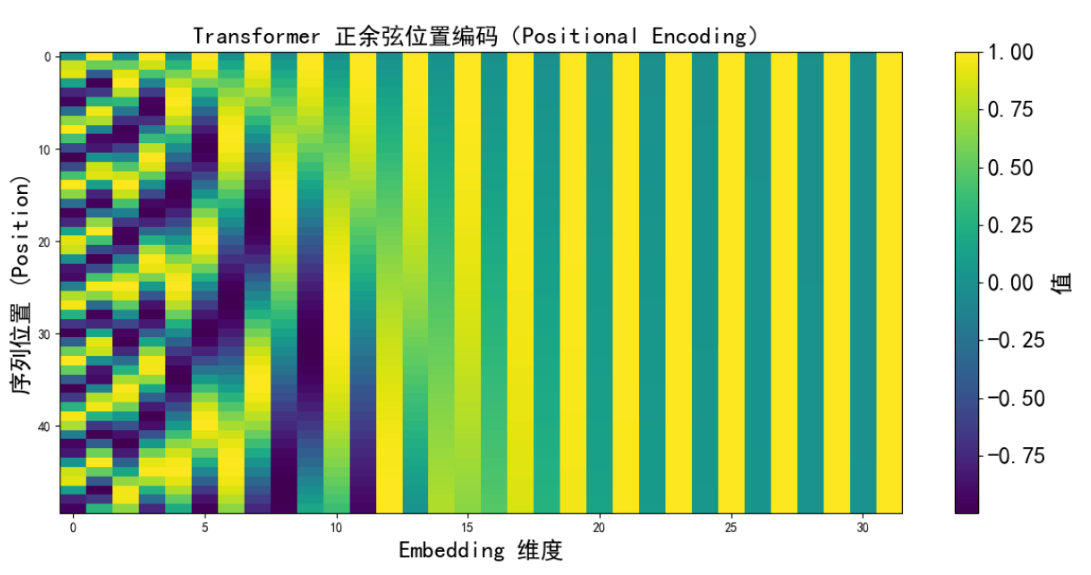
目录一、为什么需要位置编码?1.1 问题背景1.2 深层分析1.2.1 丧失顺序信息1.2.2 语义信息的丢失1.2.3 无法区分长短依赖1.2.4 模型的性能下降1.3 Solution二、位置编码长什么样三、具体数值例子四、这样做的好处是什么?4.1 Why?4.2 如何实现推断更长序列的能力?4.3 举个例子五、位置编码是怎么加进去的?六、相对 vs 绝对位置编码6.1 绝对位置编码(Abs
训练误差(Trainging Error):模型在训练数据集上的预测误差泛化误差(Generalization Error):模型在未知数据集上的期望误差,反映真实应用效果模型在训练集上表现极佳,但过度记忆了训练数据中的噪声和异常值,导致无法适应新数据经典比喻:学生A在考前死记硬背了100道题的答案(训练集),但遇到新题型(测试集)时完全不会——这就是过拟合。
