
PagedAttention详解
摘要:PagedAttention是vLLM系统中的创新技术,通过借鉴操作系统分页机制优化大语言模型的KV缓存管理。传统KV缓存存在内存碎片化、利用率低等问题,导致GPU内存浪费严重。PagedAttention将KV缓存分块存储,按需动态分配非连续内存块,通过块表实现逻辑连续映射。该技术修改了注意力计算内核,支持分页KV缓存的高效访问,显著提升内存利用率至96%以上。实验表明,相比传统方法,Pa
本文会先回顾背景知识,然后深入PagedAttention的核心机制、工作原理、实现细节,最后谈优势。PagedAttention是 vLLM中的关键技术,由UC Berkeley的研究者提出,主要解决内层管理的问题。
1.背景知识:Transformer模型和注意力机制
要懂PagedAttention,先得知道它在解决什么问题。LLM基于Transformer架构,在Transformer中,有一个核心部分叫“注意力机制”(Attention),它让模型“关注”输入序列中最重要的部分。
公式:
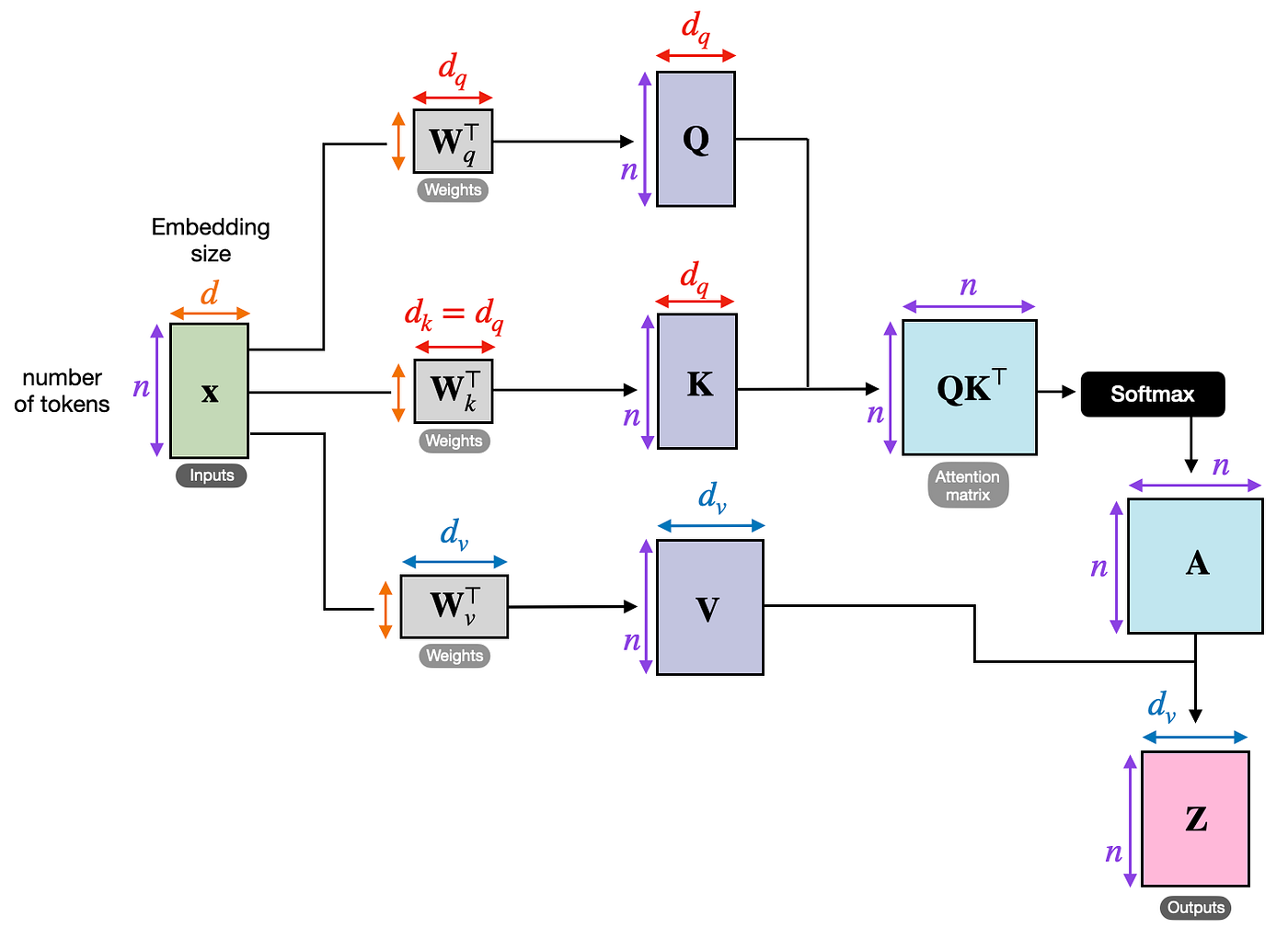
注意力机制的基本运算:假设你输入一个句子,比如"What is your name?"。模型会为每个词(token)生成三个向量:Query(查询,当前词想问什么?)、Key(键,其它词的标识)、Value(值,其它词的内容)。注意力计算是:对于当前Query,用它和之前所有的Key计算相似度(dot product,得分),然后用Softmax归一化这些得分,最后用这些权重加权求和所有Value,得到输出。
Q,K,V计算过程:输入token → embedding → 注意力层 → 用三个权重矩阵(W_q, W_k, W_v)投影得到Q, K, V
自回归生成:模型生成文本时是一个词一个词的预测(比如先预测"name",然后用它预测下一个)。但如果每次都重新计算所有过去的 Key 和 Value,会很慢。所以,用 KV Cache 把过去的 Key 和 Value 存起来,只计算新的部分。这就像记笔记:历史笔记(KV Cache)直接用,只写新笔记。
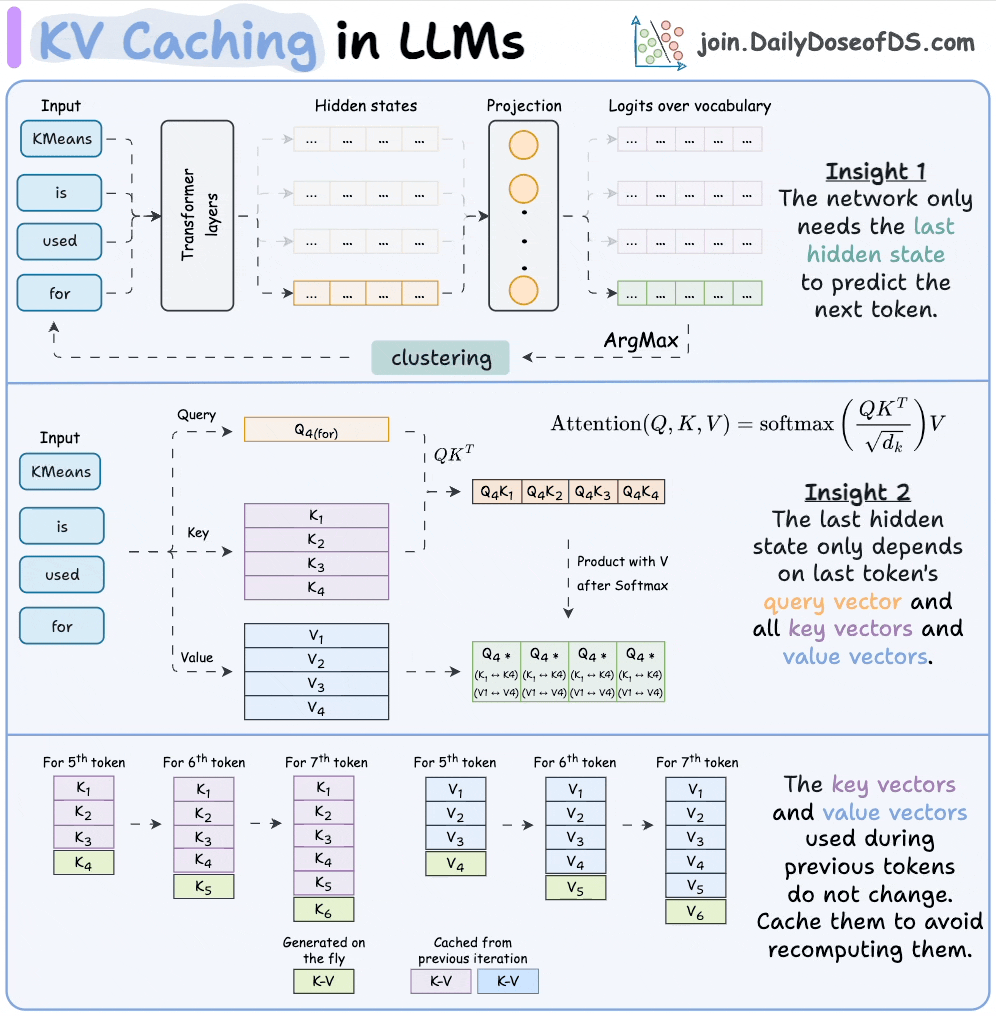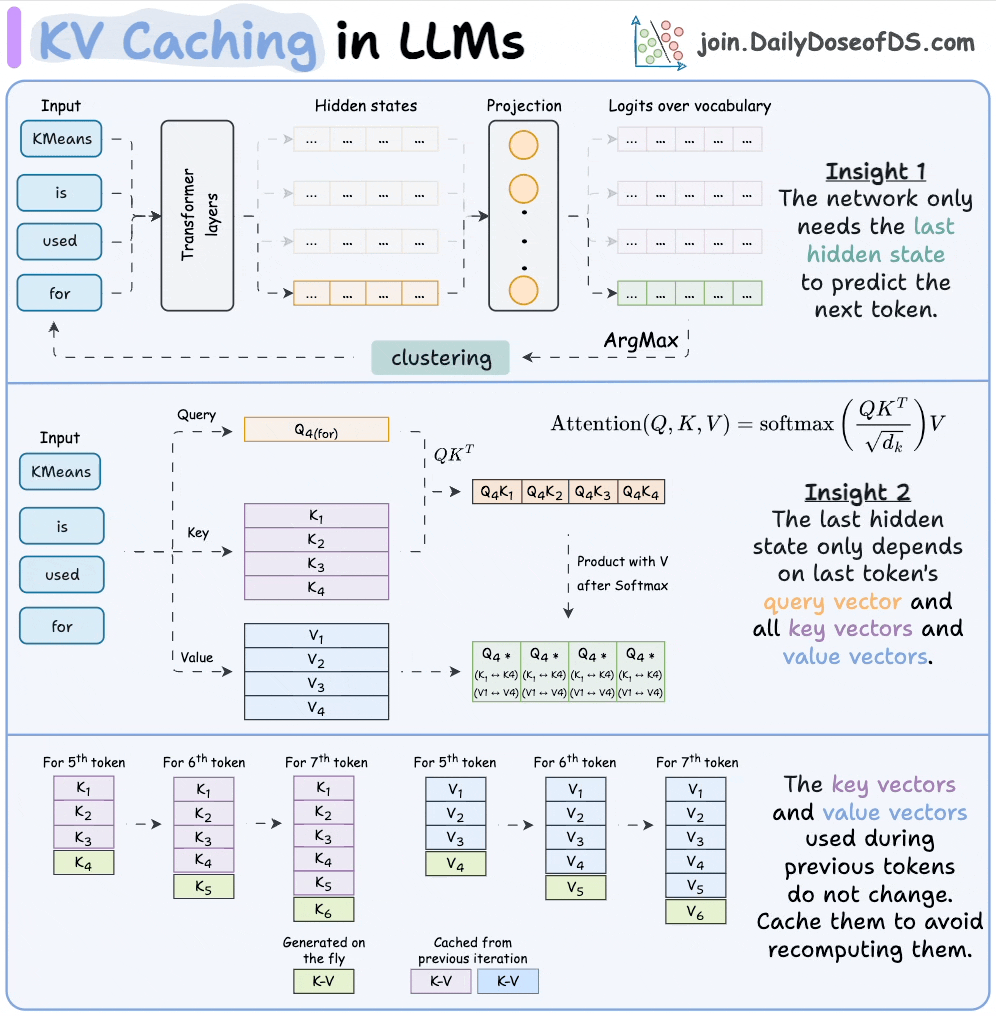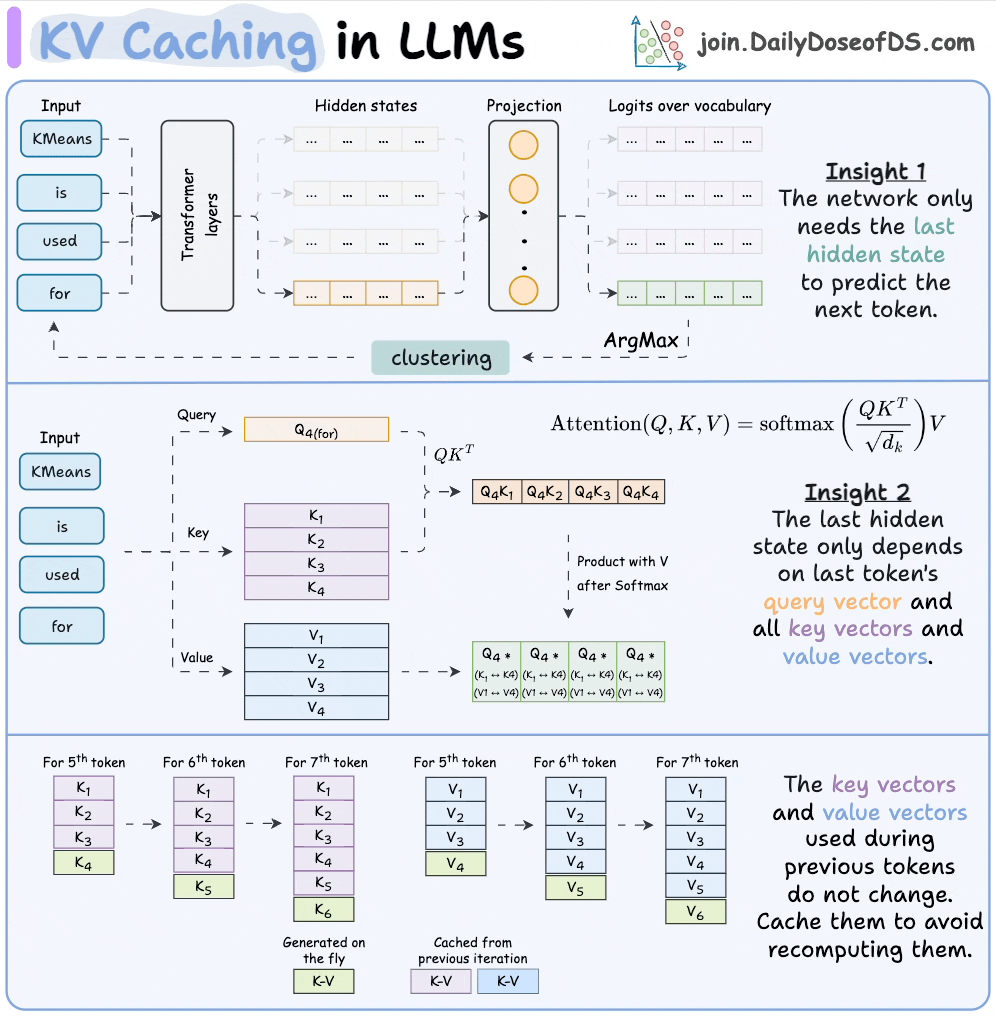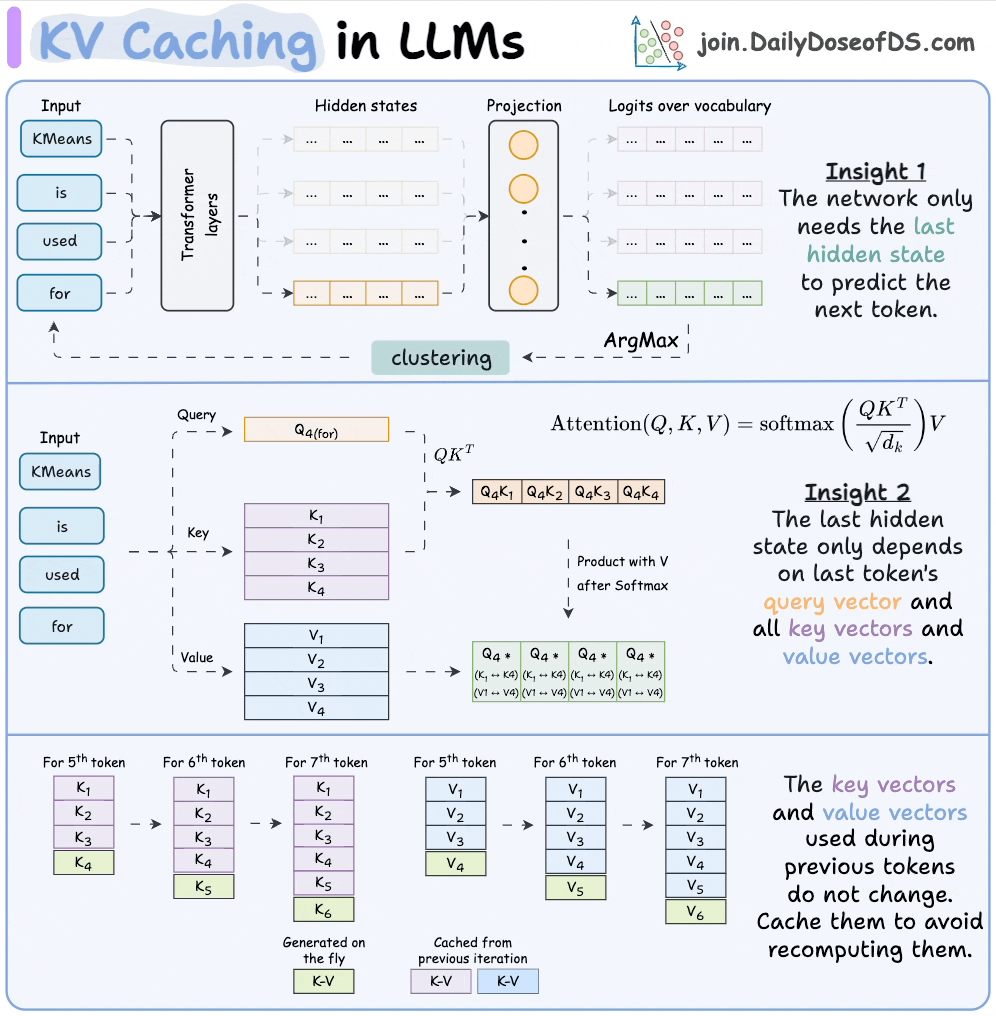
如上图所示,上半部分是无缓存的全计算,下半部分用缓存加速。缓存 Key 和 Value 后,模型只需 append 新 KV,避免重复计算。
自回归生成分成预填充和编码两个阶段:
预填充阶段:处理初始提示(prompt,"What is your name?")
- 输入是整个提示序列,一次计算所有token的Q, K,V
- 因为是causal attention,每个token只关注前面的(用mask屏蔽未来)
- 这里没有重复计算,因为是第一次
- 输出:预测第一个新token,并把提示的K和V存入KV Cache
解码阶段:逐步生成新token
- 每次生成一个新token时,输入变成:提示 + 已生成token + 新token(但新token是上一步预测的)
- 如果不缓存:模型需要从头计算整个序列的Q, K, V,包括过去的。因为Transformer是无状态的,每次forward pass都独立计算
- 为什么重复?过去的token不变,但模型输入是完整序列,必须重新投影embedding到K和V
- 这导致计算量 O(n^2) 爆炸(n是序列长度),尤其长序列时慢
- 用KV Cache:只计算新token的Q,K,V,过去的K和V直接从缓存直接拿
为什么需要重新计算过去的K和V?
假设无KV Cache:
- 生成第 1 个 token:输入提示 (长度 m),计算 m 个 K 和 V。
- 生成第 2 个:输入提示 + 第1 token (长度 m+1),重新计算所有 m+1 个 K 和 V(包括过去的 m 个)。
- 生成第 3 个:输入提示 + 前2 token (m+2),又重新计算所有...
过去的不变,但是因为输入序列变长,模型每次都全序列forward,必须重复投影过去的embedding到K和V
这就是“重新计算过去”的原因:效率低,重复工作多
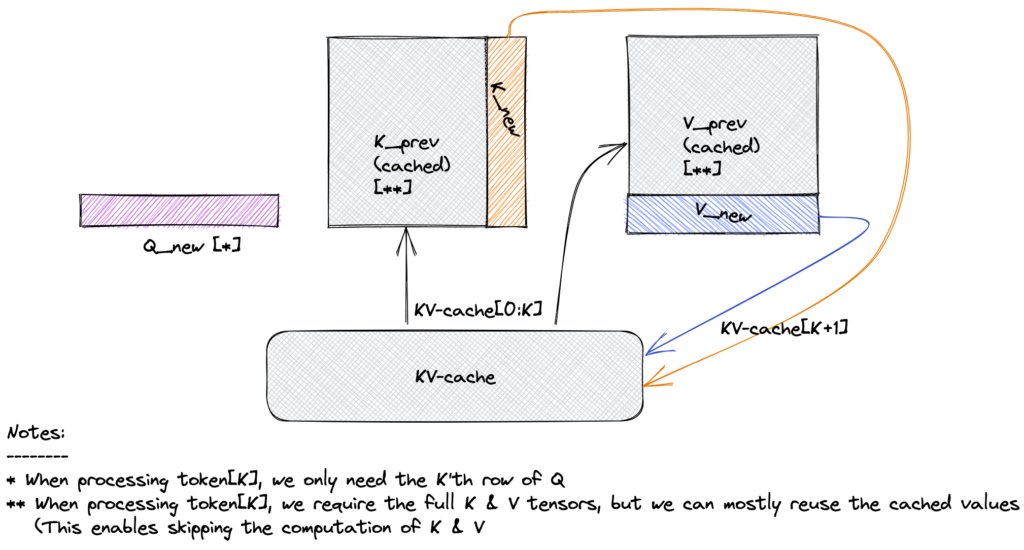
如上图:新 token 只需计算其 Q,并用缓存的过去 K 和 V。缓存后,跳过过去 K 和 V 的计算
现在我们需要解决这个问题,如果是你,你会怎么做?
我们直接把K和V缓存起来不就行了,每次从缓存里面把旧的K和V拿出来就行了,问题解决了!
下面这张图是有KV Cache和无KV Cache的对比:
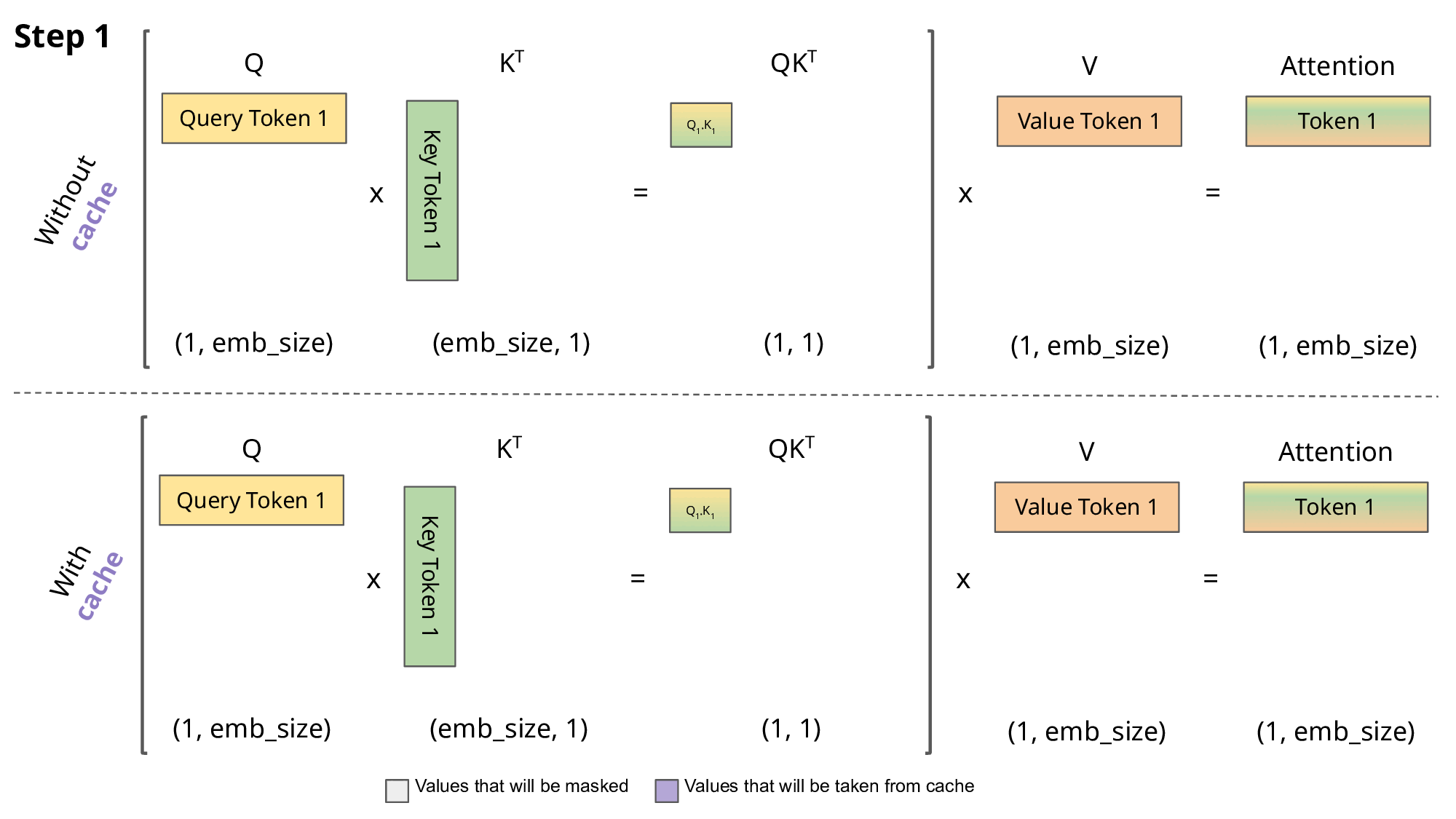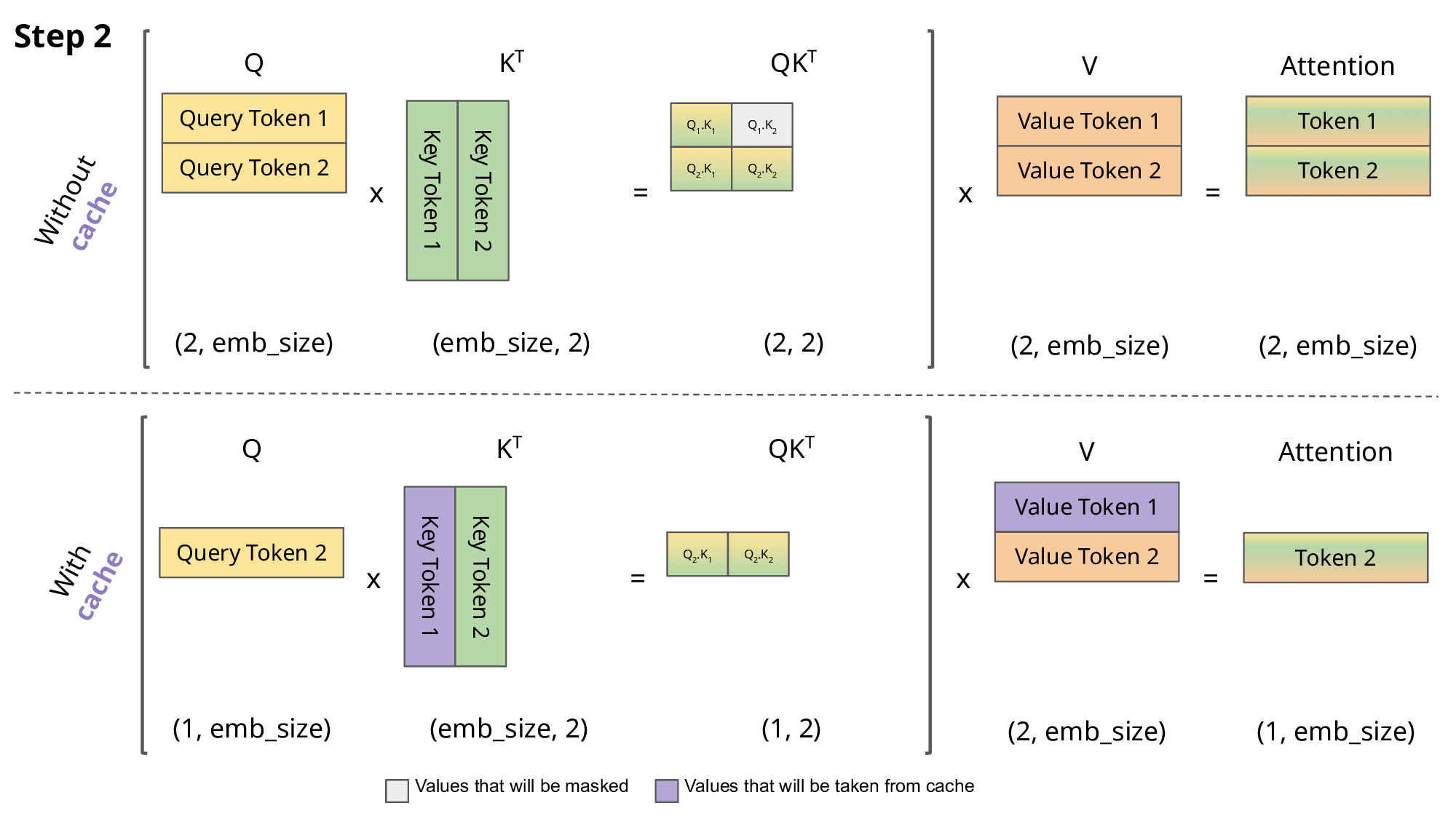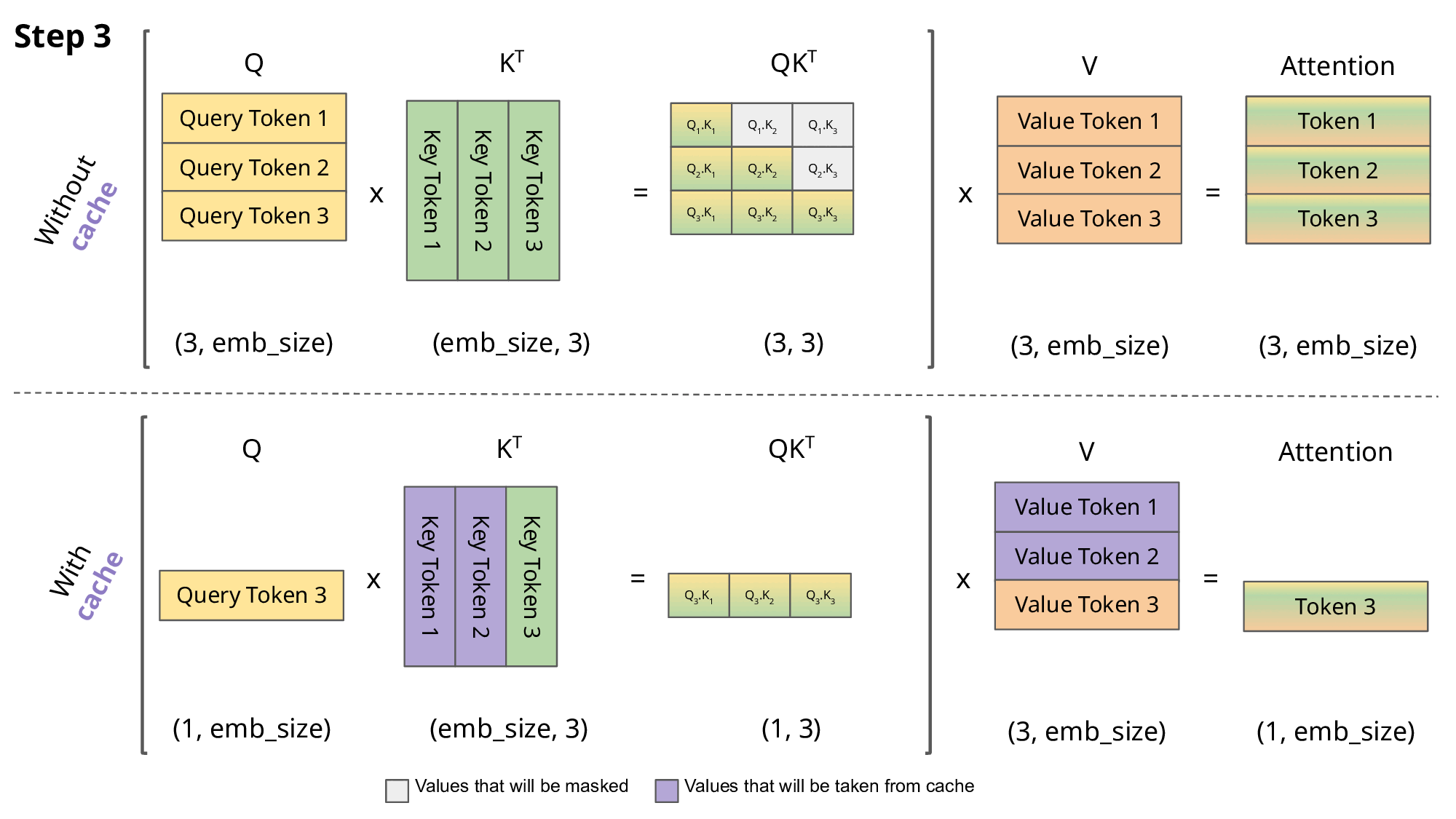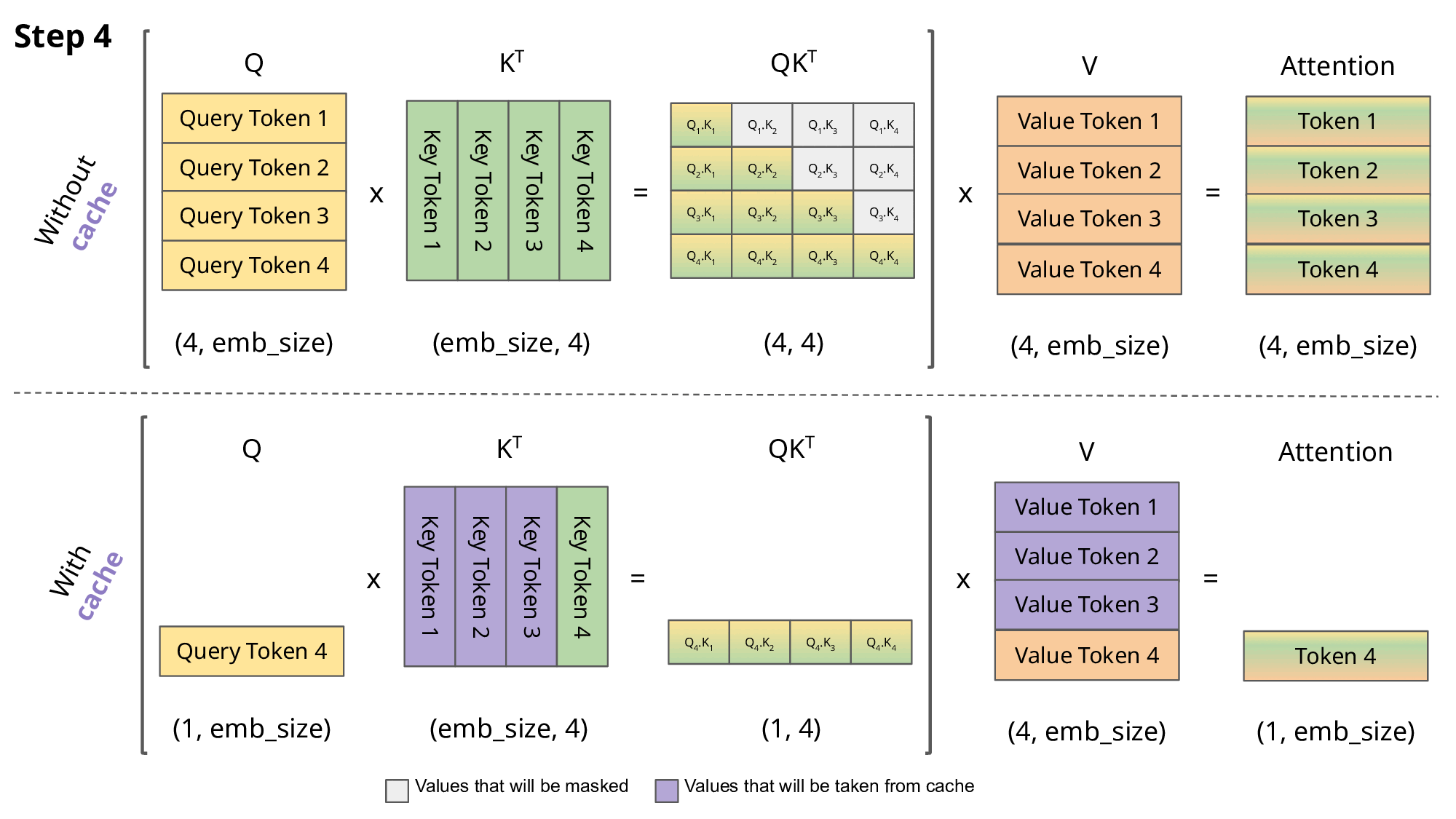
旧问题解决了,但是新问题也出现了:在实际部署模型时,尤其是处理多个用户请求(batch)或长序列,KV cache 会占用大量 GPU 内存。例如,对于 LLaMA-13B 模型,一个序列的 KV cache 可能高达 1.7GB。而且序列长度是动态的(用户输入长短不一),导致内存分配不高效。
2.传统KV Cache的问题
传统KV Cache管理要求为每个序列预分配一块连续的内存空间。这会出现什么问题?
- 内存碎片(Fragmentation):序列长度不确定,你得预留最大可能的空间(over-reservation),但实际用不完,就浪费了。或者序列增长时,需要重新分配更大的连续块,这很慢且容易失败(GPU 内存有限)。
- 浪费严重:研究显示,传统系统浪费 60%-80% 的内存。因为不同序列长度不同,内存块无法共享,导致 GPU 利用率低,只能处理少量请求,吞吐量(throughput,每秒处理的请求数)低。
- 动态问题:在服务场景,用户请求随时来,序列随时延长或结束,传统方法像固定大小的盒子装变长物品,容易溢出或空置。
类比:想象内存像一栋大楼的停车场,传统方法是为每辆车(序列)预留一整排连续车位,即使车只占一半,也不能让别人用,导致停车场很快就“满”了,但实际空位很多。
3.PagedAttention的核心机制
PagedAttention借鉴操作系统的分页和虚拟内存机制。在OS中,程序看到的内存是连续的“虚拟地址”,但实际物理内存可以是非连续的“页”,通过“页表”映射。
- 为什么叫Paged:像OS把内存分成页,程序看到连续虚拟内存,但实际物理页分散
- 优势:按需分配块,序列增长时加块就好。块可以共享(多个序列用同一提示时),减少内存用量
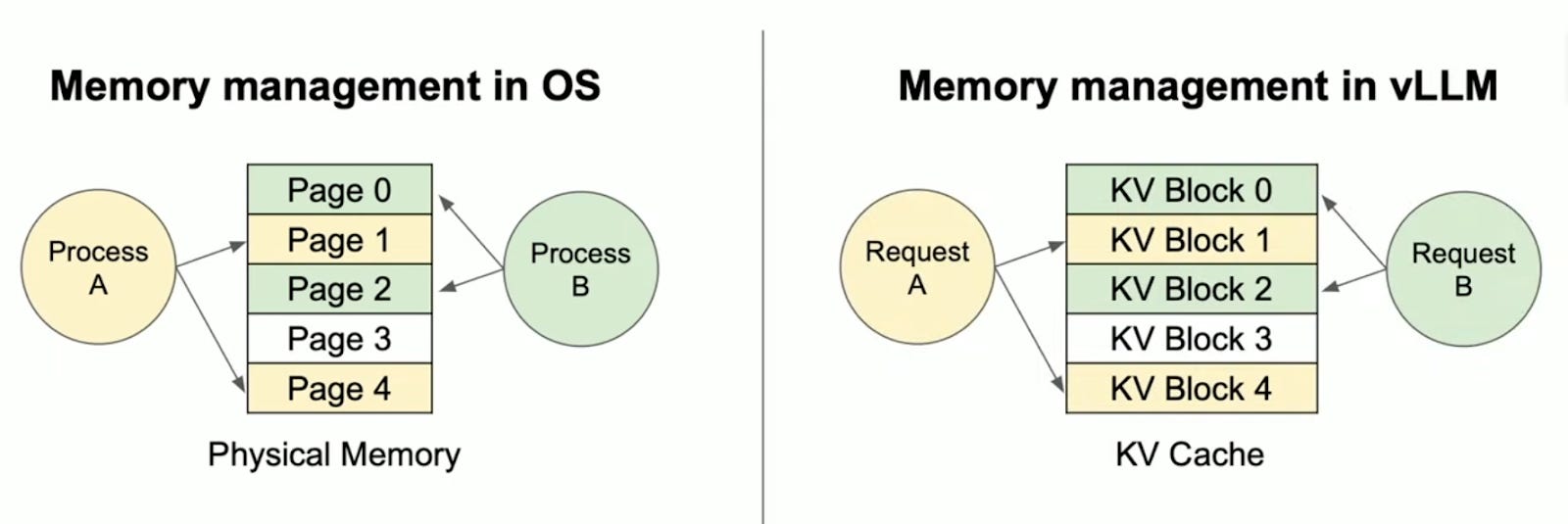
如图,左边 OS:进程 A 和 B 共享物理内存页。右边类似:请求 A 和 B 共享 KV 块。
- 分页在PagedAttention中的应用:KV cache被分成固定大小的“块”(blocks),每个块存储一定数量的token的Key和Value。这些块不需要连续存储在GPU内存中,而是分散的,按需分配。
- 块表(Block Table):每个序列有一块表,像页表一样,记录逻辑块(序列中的连续token组)到物理块(实际GPU内存位置)的映射。序列看到的是连续的KV Cache,但是底层是跳跃的。
KV Cache的分块存储:
初始化:序列开始(预填充阶段),计算第一个批次的KV,分配第一个块,存入
生成过程(解码阶段): 每生成一个新token,计算其KV
如果当前最后一个块还有空间(未满BLOCK_SIZE),直接append到这个块
如果满了,从内存池分配一个新块,添加到序列的块表中,然后存入新KV
块表就像一个列表,记录所有块的物理地址。序列增长时,块表也增长(append新块号)
释放块:序列结束或被移除时,块返回到内存池,可复用给其他序列。这叫垃圾回收,避免永久占用
额外:如果多个序列共享相同前缀(比如相同提示),它们可以共享块(通过Copy-on-Write),只在分叉时创建新块,进一步节省内存
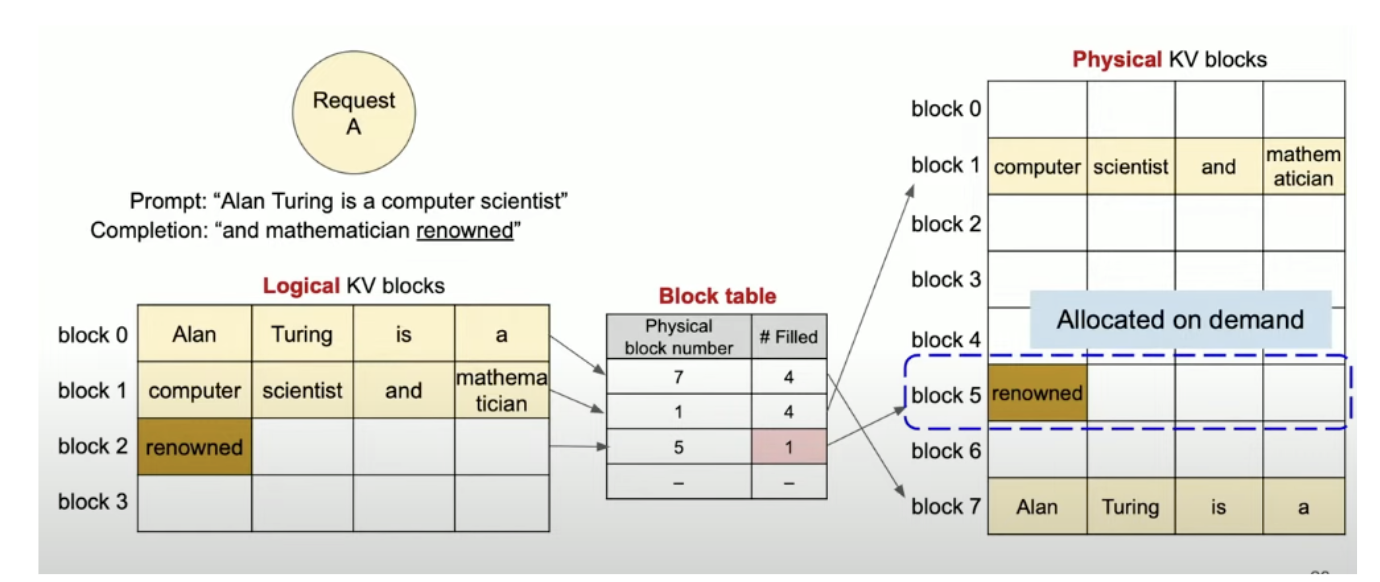
分块不是提前分好的。PagedAttention 不像传统方法那样为整个序列预先分配一大块连续内存(预留最大长度)。相反,它采用按需分配的方式:当模型开始处理一个新序列(比如用户输入一个提示)时,只分配第一个块。随着生成更多 token(词),如果当前块满了,就动态创建并分配新块。
为什么这样设计?因为序列长度是未知的(用户可能输入短句或长文),提前分好会浪费内存。动态分配像“边用边加”,更灵活。
系统会维护一个内存池(pool of blocks),从池子里拿空闲块用。如果池子空了,再从 GPU 内存分配新块。
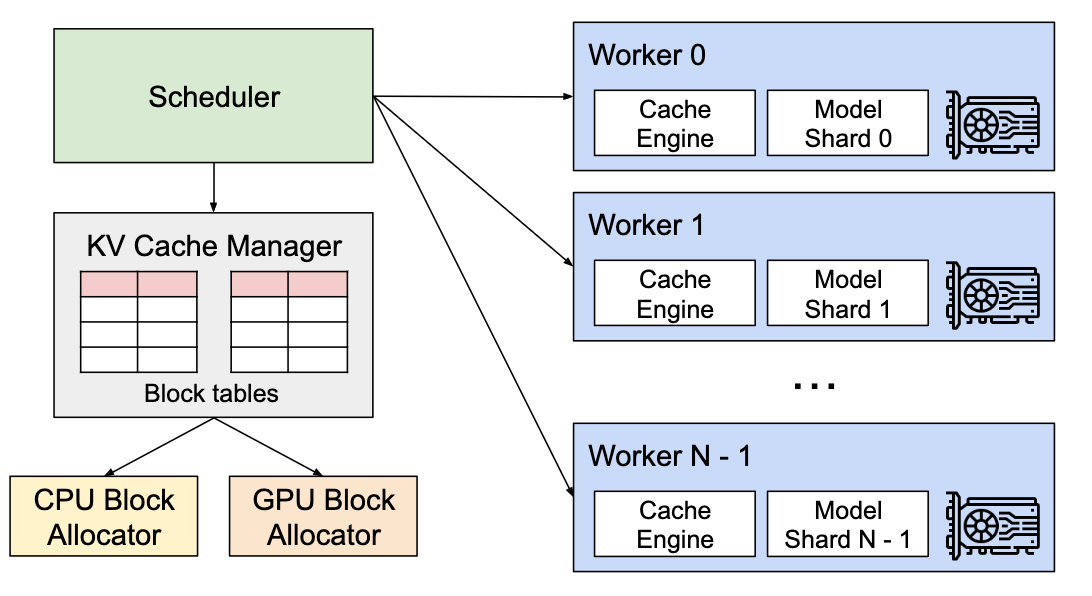
如上图所示,KV Cache Manager 从 CPU/GPU 分配器动态获取块,块表记录映射。没有提前预分所有块。
3.1 补充 Copy-On-Write机制
Copy-on-Write 是一种经典的内存优化技术,最初来自操作系统(如 Unix 的 fork 进程),它的核心想法是:当多个实体共享同一块数据时,不立即复制整个数据,而是共享指向同一物理内存的引用。只有当其中一个实体需要修改(write)数据时,才真正复制一份独立的拷贝,并在拷贝上进行修改。这样可以延迟复制,节省内存和时间。在 PagedAttention/vLLM 中,CoW 被用于 KV cache 的块共享,尤其在处理多个序列(requests)共享相同前缀(如相同提示)时,进一步减少内存占用(据报道,可节省高达 55% 的 KV cache 内存)。
在 LLM 推理中,KV cache 是append-only(只追加,不修改旧数据)的,所以“write”通常指追加新 token 的 KV 到块中。如果块是共享的且满了,追加就会触发 CoW:复制块,然后在拷贝上追加。
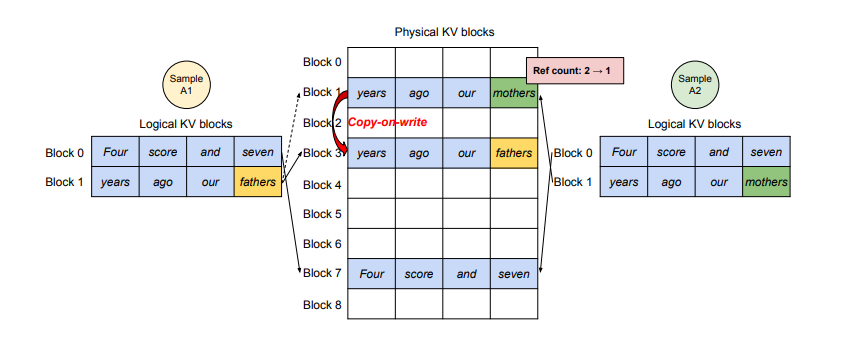
如上图所示,逻辑 KV 块通过 CoW 共享物理块。当 ref count >1 且需要写时,复制新块(见绿色部分)。
实例解释:
假设 BLOCK_SIZE=5(每个块可存 5 个 token 的 KV)。两个序列 A 和 B 共享相同提示:"Hello, how are"(3 个 token)。
-
初始共享阶段(预填充):
- 系统处理提示,计算 3 个 token 的 KV,存入一个物理块(Block X)。Block X 未满(3/5,还有 2 个空间)。
- 序列 A 和 B 的块表都指向 Block X(共享)。物理块只有一个,ref count=2。
- 内存节省:共享一个 Block X,而不是为每个序列复制。
此时,两个序列的 KV cache 相同。
-
A 分叉(生成新 token):
- 模型为 A 生成第一个新 token:"you?"(KV 需要追加)。
- Block X 是最后一个块,未满(有空间),所以追加 = 修改 Block X(写到剩余空间)。
- 但 Block X 共享(ref count=2 >1),不能直接改(会影响 B)。触发 CoW:
- 系统拷贝 Block X 的当前内容(3 tokens)到新物理块 Block Y(ref count of X 减1,现在=1,由 B 持有)。
- A 的块表更新为 [Block Y]。
- 在 Block Y 上追加 "you?" 的 KV(现在 Block Y 有 4/5 tokens,还未满)。
- B 仍指向原 Block X,无变化。
为什么 A 需要拷贝?因为要“写”共享的未满块。CoW 确保安全:拷贝后修改拷贝,不影响别人。
-
B 分叉(生成不同新 token):
- 现在 B 生成新 token:"today?"(KV 需要追加)。
- Block X 是 B 的最后一个块,未满(3/5,有空间),追加 = 修改 Block X。
- 但现在 Block X 的 ref count=1(只剩 B),无需 CoW——直接在 Block X 上追加 "today?" 的 KV(现在 Block X 有 4/5 tokens)。
- B 的块表仍 [Block X],但 Block X 被修改了(因为不共享,没问题)。
- 结果:前缀 KV 通过 CoW 实现了安全共享,新部分独立(A 在 Block Y 上,B 在 Block X 上)。避免了从头复制整个前缀。
为什么 B 不需要拷贝?因为 ref=1,不共享,修改安全。A 先分叉导致 ref 降到1,让 B 可以直接“写”。
4.PagedAttention的工作原理
PagedAttention 不只是内存管理,还修改了注意力计算内核(kernel),让它能高效处理这些分页的 KV cache。以下是详细流程:
-
步骤1: KV cache 分块 KV cache 被分成块,每个块大小固定(e.g., BLOCK_SIZE=16 token)。对于一个头(head,在多头注意力中),块存储 [num_blocks, num_heads, head_size, block_size] 形状的数据。Key 和 Value 分开存储,但逻辑上关联。
-
步骤2: 块表管理 对于一个序列,块表是一个数组,索引是逻辑块号,值是物理块号(GPU 内存地址)。序列增长时,添加新条目到块表,并从内存池分配新物理块。
-
步骤3: 注意力计算适应分页 传统注意力假设 KV 是连续的,现在不是了。所以 PagedAttention 用自定义 CUDA 内核(paged_attention_kernel)处理:
- 输入:Query (q),分页的 k_cache 和 v_cache,块表,序列长度等。
- Query 处理:每个线程组(thread group,小组线程)加载 Query 向量到共享内存(shared memory),分成向量(vecs)以优化访问。
- Key 处理:迭代序列的块。通过块表找到物理块地址,加载 Key 向量到寄存器(registers)。用线程组计算 QK dot product(相似度得分),应用掩码(mask)忽略无效 token。
- Softmax:在共享内存计算最大值(qk_max)和指数和(exp_sum),然后归一化得分。涉及 warp-level(32线程组)和块级减缩(reduction)。
- Value 处理:类似 Key,加载 Value 向量,加权求和(logits × Value),累加到输出。
- 输出:写回全局内存。
伪代码如下:
// 加载 Query
load_query_to_shared_memory(q, shared_q_vecs);
// 迭代块
for each block in sequence (via block_table):
compute_physical_address(block_number);
load_keys_to_registers(k_cache, k_vecs);
qk_score = dot_product(shared_q_vecs, k_vecs) * scale;
if (token_idx >= context_len) mask qk_score; // 忽略填充
// Softmax
compute_max_and_exp_sum(qk_scores, shared_logits);
normalize_logits(shared_logits);
// Value 加权
for each block:
load_values_to_registers(v_cache, v_vecs);
accumulate_output = dot_product(normalized_logits, v_vecs);
// 写输出
write_to_global_memory(output, accumulate_output);整体注意力流:
5. 优势和性能提升
- 内存效率:浪费降到 <4%,比传统低 60%-80%。允许更大 batch size(更多并发请求)。
- 吞吐量:vLLM 用 PagedAttention 比 HuggingFace Transformers 高 14x-24x,比 TGI 高 2.2x-3.5x,尤其在长序列、大模型、复杂解码(如 beam search)中。
- 灵活性:支持连续批处理(continuous batching),请求随时加减,不浪费计算。
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)