




- @Lzx116
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
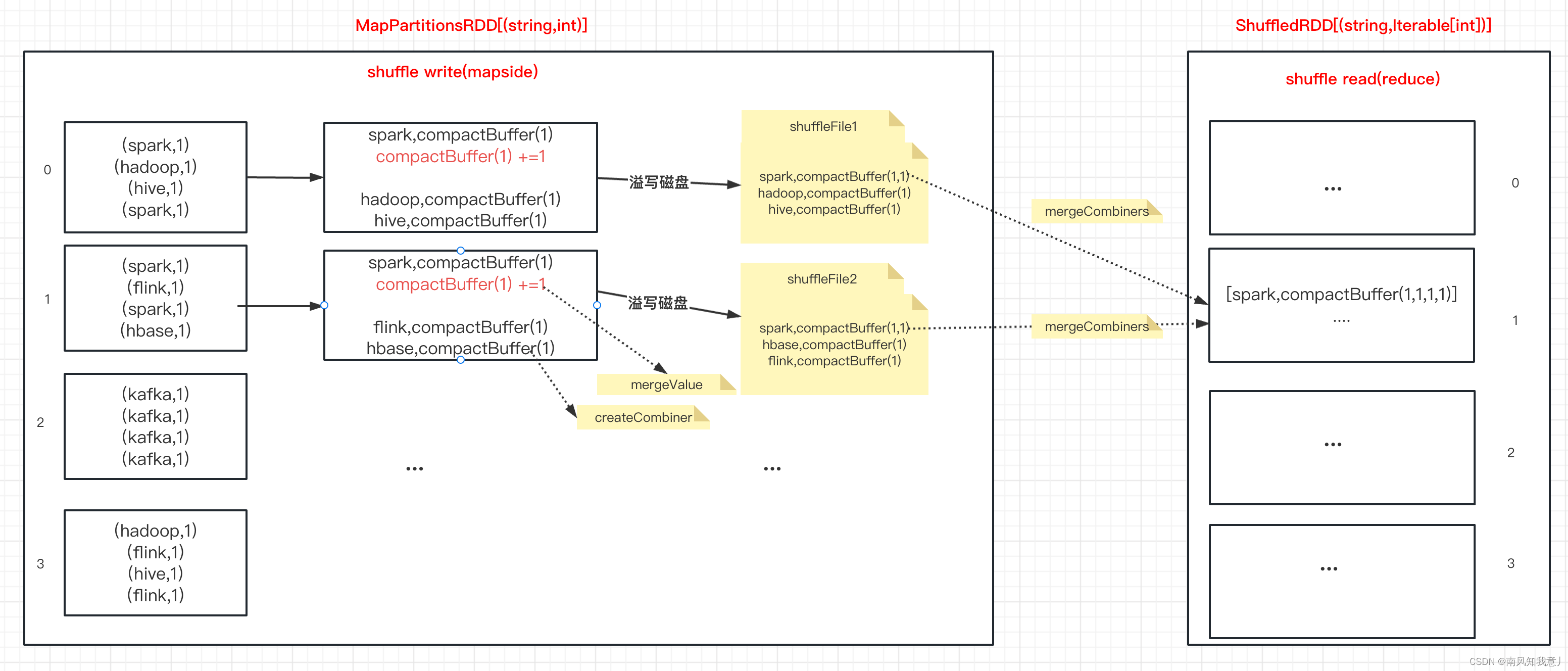
GroupByKey操作可能非常昂贵。如果您正在分组以便对每个键执行聚合(例如求和或平均),则使用 `aggregateByKey` 或` reduceByKey` 将提供更好的性能。>注意:按照目前的实现,groupByKey 必须能够保存内存中任何键的所有键值对。如果一个键的值太多,造成数据倾斜,可能会导致 `OutOfMemoryError`
然后我们直接右键运行,看下打印的日志看到提交成功了,然后我们打开yarn的监控页面看下有没有job。看到有一个spark程序在运行,然后我们点进去,看下具体的运行情况:选择一下job,看下executor打印的日志写到kafka的数据,没什么问题,停止的时候,只需要在idea里面点击停止程序就可以了,这样测试起来就会方便很多.这个是因为在本地提交的所以用户名是JasonLee,它没有访问hdfs的
在我的认识里,传统硬盘的写速度应该能够到120M/s的样子,网络传输速度也能够达到10M/s至少,在使用千兆交换机的前提下,甚至能够达到100M/s机器配置如下:机器数量:7DataNode:7内存:64G硬盘:12T 5400转 磁盘网络情况:公司内部局域网写测试:往HDFS上写100个128M的文件:使用命令 :TestDFSIO writeTest对应一个MapReduce job,每个文件
spark优雅关闭sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")// 启动新的线程,希望在特殊的场合关闭SparkStreamingnew Thread(new Runnable {override def run(): Unit = {while ( true ) {try {Thread.sleep(5000)
jstat -gcutil < pid >GC日志jmap -heap < pid>jmap -histo < pid> | head -n 30
每个`分桶文件`就是一个`数据分片(Tablet)`,`Tablet是数据划分的最小逻辑单元`。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
mysql周、季度、月、年时间操作
java.lang.ArrayIndexOutOfBoundsException
先说结论:spark sql和hive不一样,spark对count(distinct)做了group by优化>在hive中count().>hive往往只用一个 reduce 来处理全局聚合函数,最后导致数据倾斜;在不考虑其它因素的情况下,我们的优化方案是先 group by 再 count ...