




- @Langchain
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
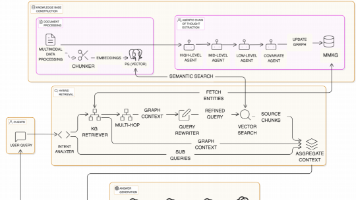
DO-RAG 采用创新的Agentic CoT架构,从多模态文档中提取结构化关系,构建动态知识图谱以提升检索精度。
GitHub 86k+ Star!Awesome-LLM-Apps:年度最热的 LLM 应用宝藏库
纯小白用时3 小时,终于成功本地化部署了一套 Coze,血泪踩坑经验分享
今天要给大家安利一个超级给力的开源项目——awesome-llm-apps。老实说,第一次看到这个项目的时候,我都惊呆了,这也太全面了吧
最新版本的PIGAI中已经完全适配了,像milvus 、pgvector、ocenbase 等的混合检索策略大大提升RAG搜索的准确性。
langchain4j 是一个面向 Java 开发者的 LLM 应用开发框架。就像 Spring 统一了 Java Web 开发的接口一样,langchain4j 也在做类似的事情——为 Java AI 开发提供统一的抽象层。
今天想掏心窝子跟还在犹豫的后端同行说句实话:现在AI应用开发的社招窗口确实在放大,但早就不是“随便学Python、调个API就能混进去”的时代了。尤其是这三类后端同学,转型前真的要慎重避坑!
对于深耕Java领域的程序员而言,从传统业务开发转向大模型相关开发,早已不是“可选项”而是“加分项”——这既是突破3-5年职业瓶颈的核心路径,更是借势技术风口实现薪资翻倍的绝佳机遇。
Multi-Agent 的价值就在这里:把“复杂问题”变成“多人协作问题”,用架构把能力放大、把流程跑顺、把结果稳定下来。
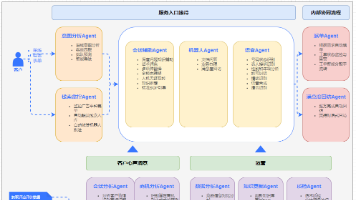
今天主要给大家介绍一下如何使用 LangChain 快速构建 RAG 应用。
