




- @Java_Joker
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
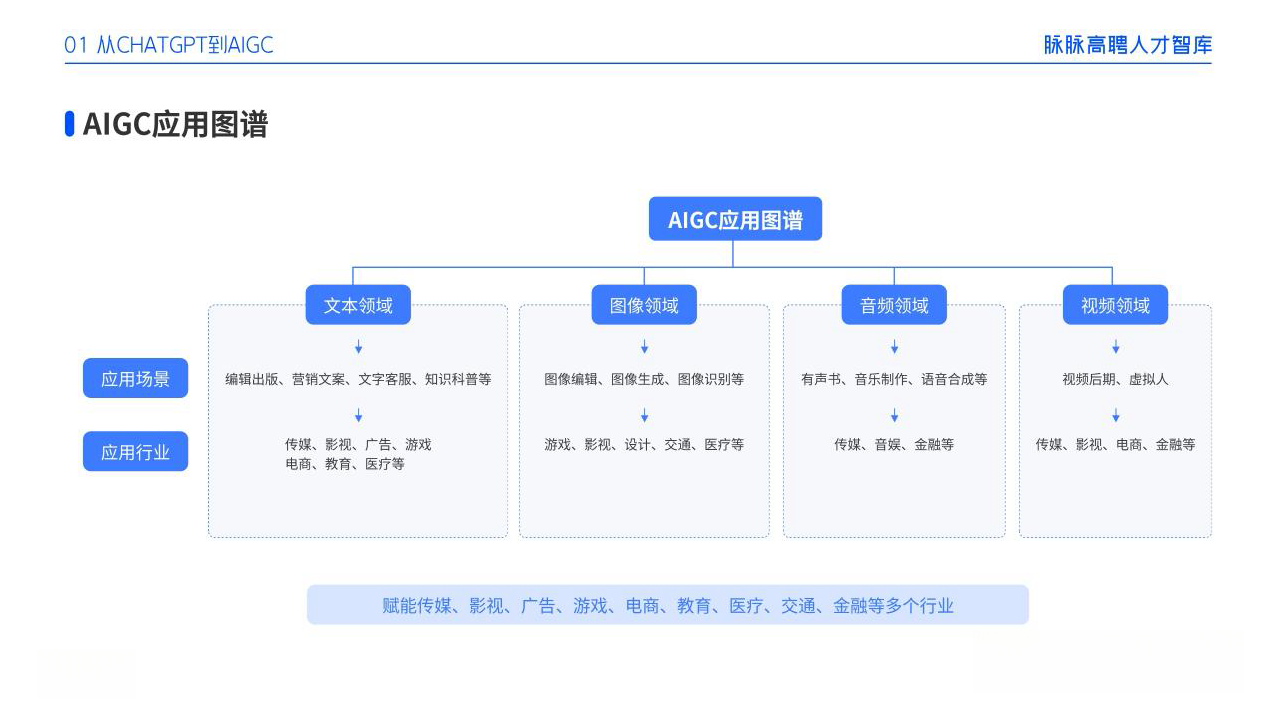
Content)技术,即人工智能生成内容的技术,具有非常广阔的发展前景。随着技术的不断进步,AIGC的应用范围和影响力都将显著扩大。以下是一些关于AIGC技术发展前景的预测和展望:1、AIGC技术将使得内容创造过程更加自动化,包括文章、报告、音乐、艺术作品等。这将极大地提高内容生产的效率,降低成本。2、在游戏、电影和虚拟现实等领域,AIGC技术将能够创造更加丰富和沉浸式的体验,推动娱乐产业的创新。

感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,

现在是人工智能时代,利用好AI 工具,可以降低普通人做副业的门槛,同时也能提高工作效率, 因此AI 赚钱的副业还是挺多的,今天拿20个普通人也能尝试的AI搞钱副业分享给大家 ,包括每个副业的名称、做法以及案例。当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。太多了,这边就先不

一、AI工具在工作中的深度应用二、AI工具在学习中的显著优势三、如何高效利用AI工具《实战ChatGPT:应用AI工具高效工作与学习》编辑推荐内容简介作者简介目录前言随着人工智能(AI)技术的蓬勃发展,AI工具已经深入渗透到我们的日常工作和学习中,为我们带来了前所未有的便利和效率。从复杂的数据分析到个性化的学习推荐,AI工具正在逐渐改变我们的工作和学习模式,让我们能够更加高效地完成任务,提升个人竞
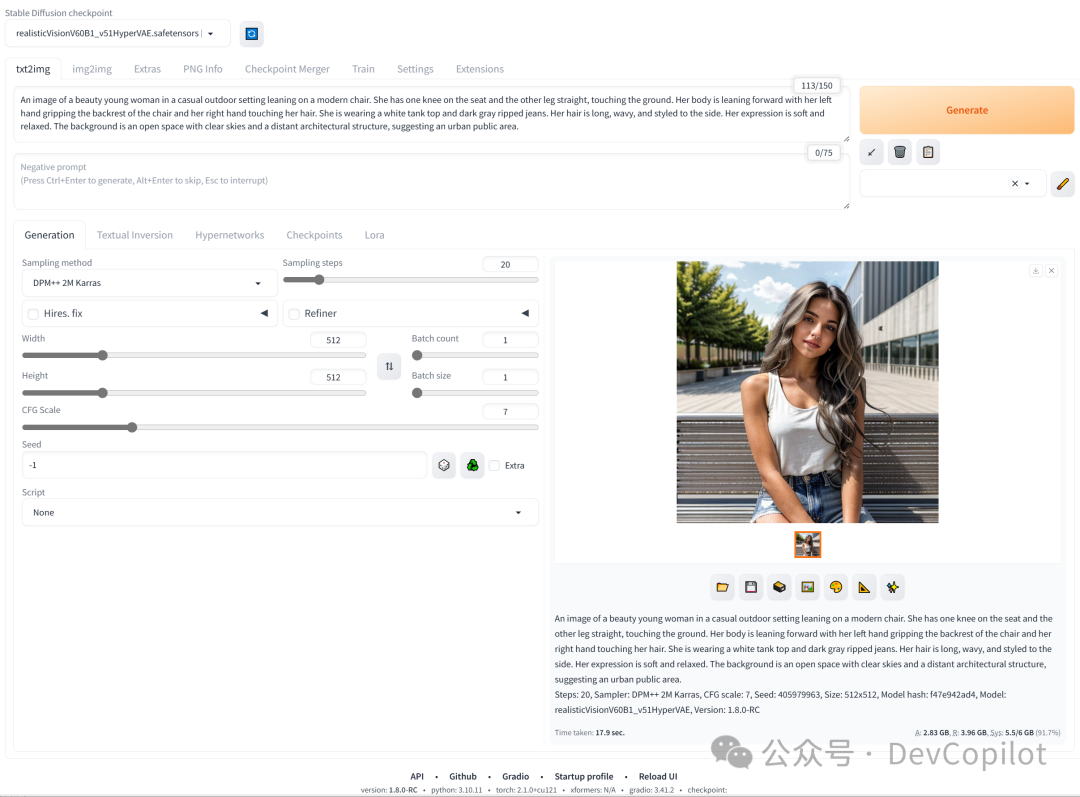
Stable Diffusion 是一种深度学习模型,用于生成高质量的图像。它基于一种名为扩散过程的生成方法,能够在给定条件的情况下生成具有丰富细节的图像。看看本文的搭建步骤,成功部署 Stable Diffusion 模型,文生图从此不求人,不用找各种代理和第三方付费的资源了。
ControlNet是一种强大的SD webui插件,它通过神经网络模型来实现对生成图像的精确控制。当然,它本身的应用远不止与此,ControlNet 在许多领域中都具有广泛的应用,包括艺术创作、图像修复、虚拟场景生成等等。在传统的图像生成任务中,我们通常使用提示词(prompt)来引导模型生成特定类型的图像。通过输入适当的提示词,我们可以约束模型生成与提示词相关的图像内容。然而,只使用提示词来引

摘要一、AI写作工具二、AI图像工具2.1、常用AI图像工具2.2、AI图片插画生成2.3、AI图片背景移除2.4、AI图片无损调整2.5、AI图片优化修复2.6、AI图片物体抹除三、AI音频工具四、AI视频工具五、AI设计工具六、AI编程工具七、AI对话聊天八、AI办公工具8.1、AI幻灯片和演示8.2、AI表格数据处理8.3、AI文档工具8.4、AI思维导图8.5、AI会议工具8.6、AI效率

今天教大家本地部署Ollama大语言模型,并接入ComfyUI中,让你的ComfyUI变得更智能。0****1介绍之前ComfyUI很多插件接入LLM大模型都得单独配置,很麻烦,今天给大家介绍一个通用的插件comfyui-ollama,再结合Ollama本地安装,让你想用什么大模型都行,从此解决提示词润色问题。今天内容比较干,主要分三块进行:Ollama本地安装提示词润色方案图片反推提示词02安装

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。感兴趣的小伙伴,赠送

而这一期给大家带来一个超级强大并且是开源的 AI 图像生成工具 Stable Diffusion,简称 SD,相信有部分网友有在使用的了,也有部分网友可能被劝退了,入门到放弃。今天,这些都不是事,将带领大家用最短的时间在电脑上部署好 SD;并且轻松的掌握 SD 的使用以及其它的注意事项小技巧,这一期是真正的干货满满。
