- @David_house
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
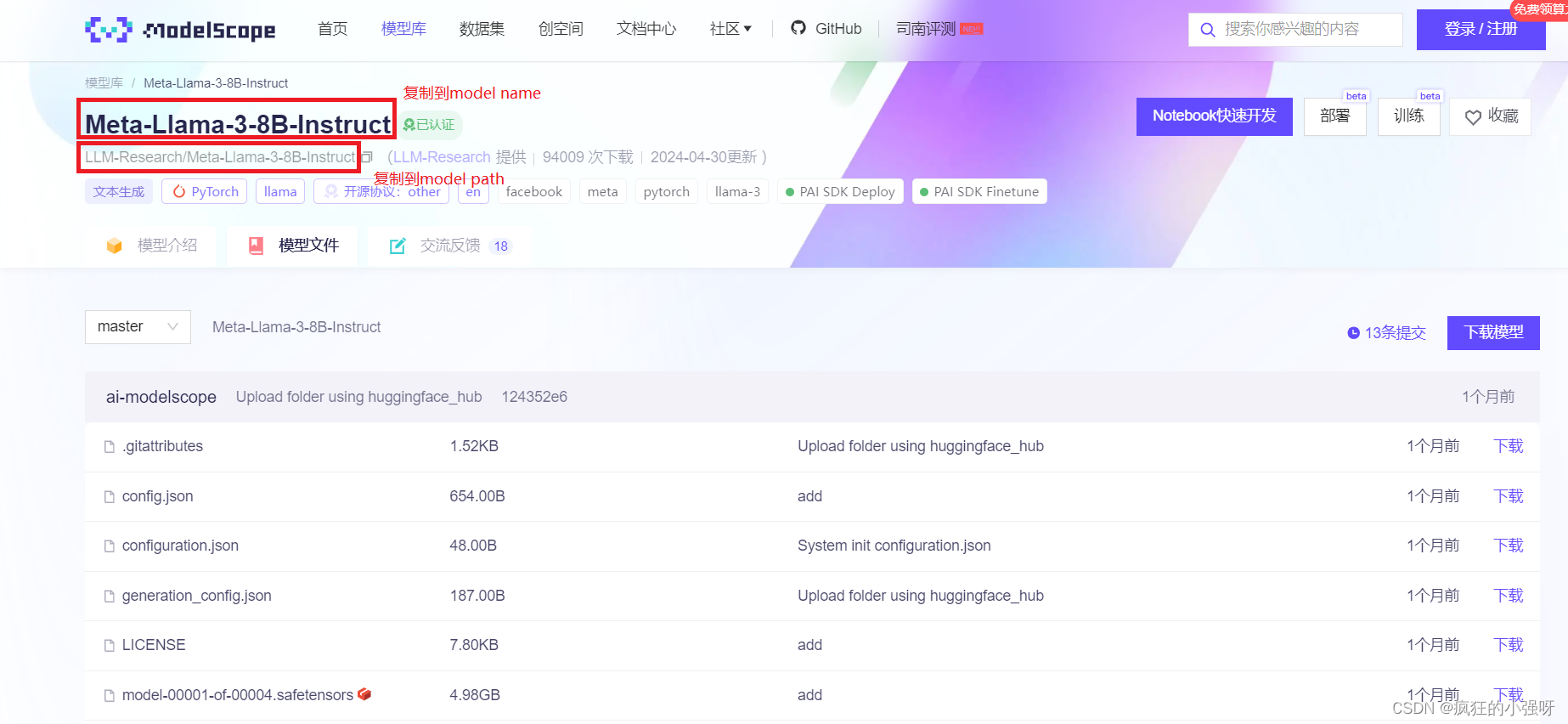
如果你尝试过微调大模型,你就会知道,大模型的环境配置是非常繁琐的,需要安装大量的第三方库和依赖,甚至需要接入一些框架。但是大模型微调的方法又是非常类似的,那有没有一种工具可以统一这些操作,让大模型微调变成一个简单易上手的事情,LLaMa-Factory就是为了解决这个问题应运而生
数据探索有利于我们发现数据的一些特性,数据之间的关联性,对于后续的特征构建是很有帮助的。对于数据的初步分析(直接查看数据,或.sum(), .mean(),.descirbe()等统计函数)可以从:样本数量,训练集数量,是否有时间特征,是否是时许问题,特征所表示的含义(非匿名特征),特征类型(字符类似,int,float,time),特征的缺失情况(注意缺失的在数据中的表现形式,有些是空的有些是”

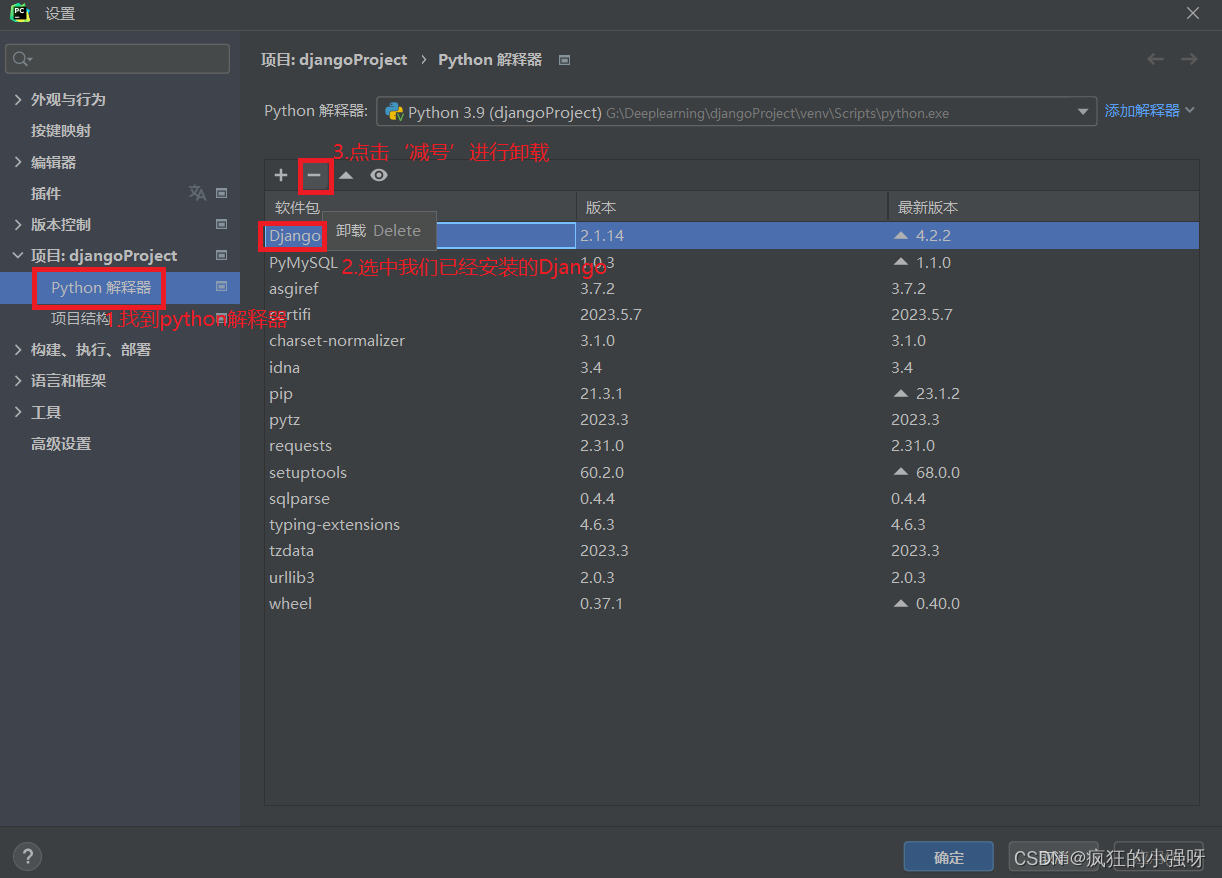
这个问题是说我们的Django框架版本比较新,已经不支持MySQL老版本5.7.2了,MySQL8或者更新的版本才是我们需要的或者说匹配的。
8080端口未出现wokers如果你已经启动hdfs和yarn,但是8080端口里面的wokers一个都没有出现或者是显示虚拟机拒绝了连接请求:一般情况下都是因为没有关闭防火墙,没有wokers出现还有一种情况就是你配置了zookeeper但是没有开zookeeper集群关闭防火墙命令:systemctl stop firewalld.service查看防火墙状态:systemctl ...
ElasticSearch启动报错Exception in thread "main" java.nio.file.AccessDeniedException: /opt/SoftWare/ES/elasticsearch-6.5.4/config/jvm.optionsat sun.nio.fs.UnixException.translateToIOException(UnixException
webpack是一个流行的前端项目构建工具(打包工具),可以解决当前web开发中所面临的问题。webpack提供了友好的模块化支持,以及代码压缩混淆、处理js兼容问题、性能优化等强大的功能,从而让程序员把工作重心放到具体的功能实现上,提高了开发效率和项目的可维护性。

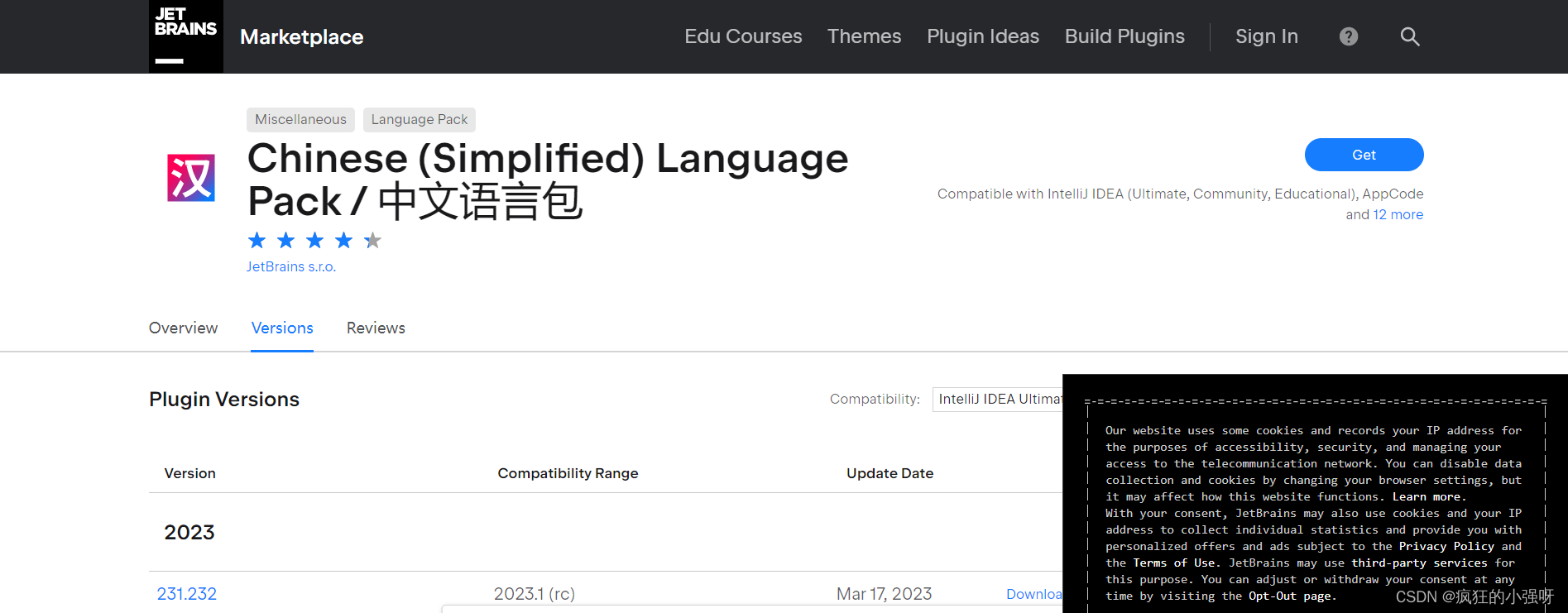
有时候因为网络等各方面原因,我们常常会遇到安装失败的情况,比如俺,用这种方法安装了很多次都没有成功,所以就用了第二种方法安装。去pycharm插件官网下载插件安装包,官网网址:https://plugins.jetbrains.com/
python之数据存储列表元组列表概念:列表是一种存储大量数据的存储类型特点列表具有索引概念,可以通过索引操作列表中的数据列表中的数据可以进行添加、删除、修改、查询等操作列表的定义和使用变量名=[数据1,数据2,……]#创建变量名[索引] #获取列表中的数据变量名[索引]=值 #修改列表中的数据操作列表常用方法方法名功能参数返回值append(data)在列表的末尾加数据data:要追加的数据No
ElasticSearch启动报错Exception in thread "main" java.nio.file.AccessDeniedException: /opt/SoftWare/ES/elasticsearch-6.5.4/config/jvm.optionsat sun.nio.fs.UnixException.translateToIOException(UnixException
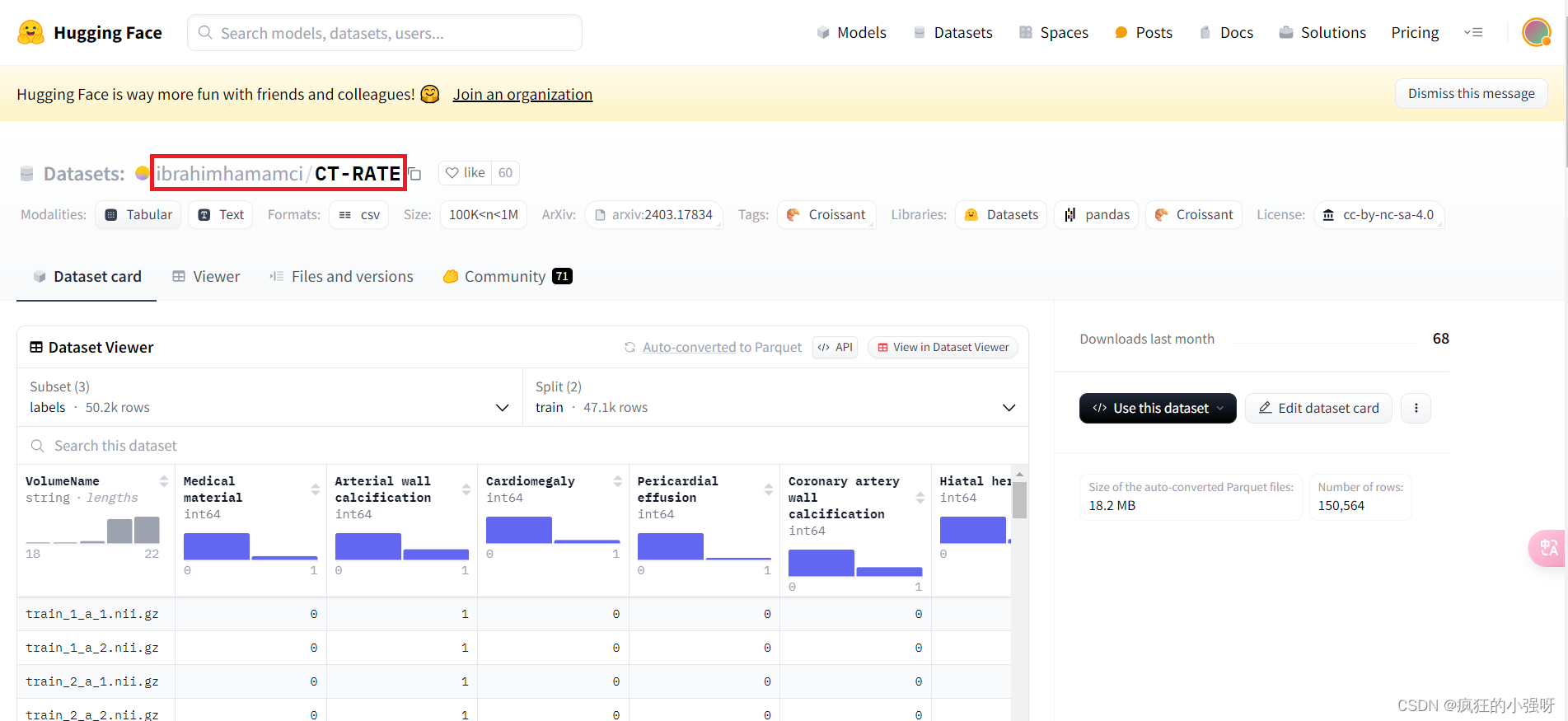
最近需要从huggingface上下载一个数据集,发现不能像模型那样能直接点击下载,需要通过代码来获取,很麻烦,谨以此博客作为记录