




- @CSDNXXCQ
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
利用计算机视觉和图像处理基于未标记图像的多类分类是目前的一个重要问题。在这项研究中,我们重点研究了为类驱动的无标记数据构建高级特征检测器的现象。我们提出了一种归一化受限玻尔兹曼机(NRBM)来形成一个鲁棒的网络模型。所提出的NRBM的开发是为了实现降维的目标,并在学习更合适的数据特征方面提供更好的特征提取,并进行增强。为了提高学习收敛速度并降低NRBM的复杂度,我们在训练更新参数时添加了Polya
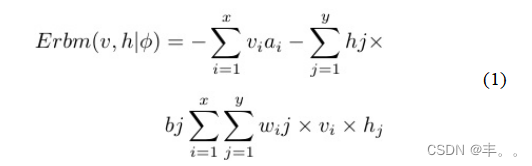
CLIP (Contrastive Language-Image Pre-Training) 是一种联合训练算法,可以训练出一个可以处理图像和文本的模型,从而使得模型可以同时理解图像和对图像的描述。CLIP 的核心思想是使用对比学习(contrastive learning)的方法,将图像和文本对应起来,然后对这些对进行训练。具体来说,CLIP 在训练时使用一组图像和相应的文本描述,然后通过对比这

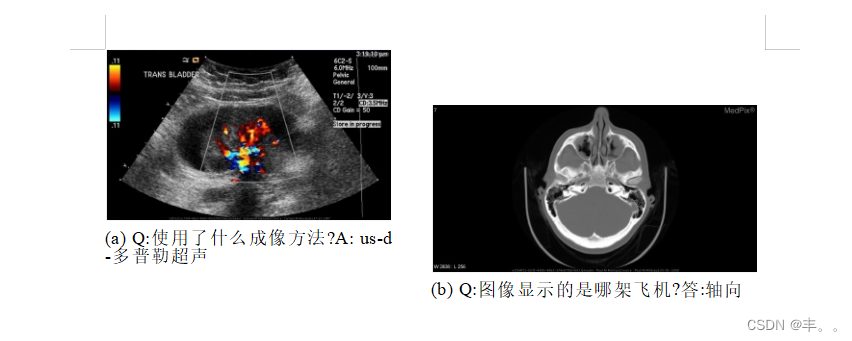
本文介绍了ImageCLEF 2019上的医学视觉问答任务(VQA-Med)的概述。参与系统的任务是根据放射学图像的视觉内容回答医学问题。在VQA-Med的第二版中,我们重点讨论了四类临床问题:模态、平面、器官系统和异常。利用分类和文本生成方法,这些类别的设计具有不同程度的难度。我们还确保所有问题都可以从图像内容中回答,而不需要额外的医学知识或特定领域的推理。我们创建了一个包含4200个放射学的新
动量梯度下降法(Momentum Gradient Descent)是一种优化算法,用于加速梯度下降的收敛速度,特别是在存在高曲率、平原或局部最小值的情况下。动量法引入了一个称为“动量”(momentum)的概念,它模拟了物体在运动中积累的速度,使得参数更新更具有惯性,从而更平稳地更新参数并跳过一些不必要的波动。动量梯度下降法可以帮助算法跳过较为平坦的区域,加速收敛,并减少参数在局部最小值附近的震
概念引入命名实体识别命名实体识别(Named Entity Recognition,NER)是NLP中一项非常基础的任务。NER是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。定义命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文
我们可以先定义一个类NeuralNetwork,其中包含神经网络的层数、每层神经元个数、权重矩阵和偏置向量等属性,以及前向传播和反向传播等方法。在上面的代码中,layer_sizes是一个列表,包含了每层神经元的个数,例如[2, 3, 1]表示输入层有2个神经元,隐层有3个神经元,输出层有1个神经元。weights是一个列表,其中每个元素是一个权重矩阵,表示该层和前一层之间的权重关系。biases
在多任务学习中,不同任务之间可以是相关的,共享的,或者相互支持的,因此通过同时训练这些任务可以提供更多的信息来改善模型的泛化能力。多任务学习的优势在于可以通过共享模型参数和特征表示来促进任务之间的知识传递,从而加速模型训练,提高模型的泛化性能,减少过拟合,并能够从有限的数据中更有效地学习。迁移学习:多任务学习可以被视为一种特殊的迁移学习,其中任务之间的知识传递有助于提高目标任务的性能。相关任务:多
学习率衰减(Learning Rate Decay)是一种优化算法,在训练深度学习模型时逐渐减小学习率,以便在训练的后期更加稳定地收敛到最优解。学习率衰减可以帮助在训练初期更快地靠近最优解,而在接近最优解时减小学习率可以使模型更精细地调整参数,从而更好地收敛。指数衰减:使用指数函数来衰减学习率,例如每隔一定迭代步骤,将学习率按指数函数进行衰减。定期衰减:在训练的每个固定的迭代步骤,将学习率乘以一个
机器学习(ML)在最近的研究中越来越受欢迎。它已经在一个巨大的应用范围包括图像识别、多媒体概念检索、社交网络分析、视频等推荐、文本挖掘等。深度学习(DL)在这些应用中得到了广泛的应用[117]。指数计算技术的增长、令人难以置信的发展和数据可用性促成了DL的研究。深度学习的成功一直是解决更复杂的机器学习问题的激励因素。此外,深度学习的主要优势是它以层次形式表示,也就是说,它可以通过一个通用的目的学习

本文为简单机翻,参考学习用1多模态机器学习:综述与分类Tadas Baltruˇsaitis, Chaitanya Ahuja,和Louis-Philippe Morency抽象——我们对世界的体验是多模态的——我们看到物体,听到声音,感觉到纹理,闻到气味,尝到味道。模态是指某件事情发生或体验的方式,当一个研究问题包含多个这样的模态时,它就被称为多模态。为了让人工智能在理解我们周围的世界方面取得进