- @BlueSocks152
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
文章探讨企业如何通过AI Agent解决大模型落地"最后一公里"困境。AI Agent作为业务适配的智能执行体,通过场景化组织、执行体定位和复用型平台,将大模型能力转化为实际业务价值。文章介绍"智擎"平台作为企业构建AI Agent的底座框架,分享多个应用案例,提出四阶段行动建议,强调业务、技术、组织三者深度融合的重要性。

本文详细介绍了如何使用LlamaIndex微调Cross-Encoder类型的Rerank模型,显著提升RAG系统检索精度。通过微调,可在不改变Embedding模型的情况下,将检索准确率提升10-30%,是优化RAG系统的高性价比方法。文章涵盖Rerank模型基础概念、数据准备、微调流程、评估方法及最佳实践,提供完整代码示例,特别适用于垂直领域RAG系统的性能优化。

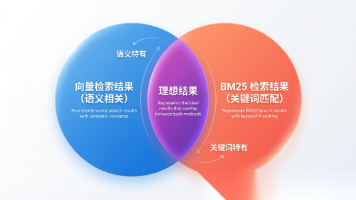
文章讨论了RAG应用中单一检索策略的局限性,特别是专有名词匹配失败和语义漂移问题。提出采用混合检索(结合向量检索和关键词检索)并通过RRF算法融合结果,以提高召回率。随后引入Cross-Encoder重排序技术对候选文档进行精细筛选,提升检索精度。这种"漏斗筛选"架构在保证计算效率的同时,显著提升了RAG系统的检索准确性和适用性,特别适合法律、医疗、金融等对精确性要求高的领域。
本文从基础定义、技术原理(预训练、后训练、强化学习)到实用技巧全面解析大语言模型(LLM)。预训练阶段通过互联网数据训练基础模型;后训练将模型转变为对话助手;强化学习优化输出质量。文章探讨幻觉问题、思维链等关键概念,并提供use code等实用技巧,帮助读者理解LLM工作原理和应用方法。
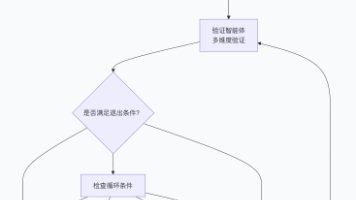
本文介绍了AI Agent的自我反馈机制,通过双智能体架构(生成智能体与验证智能体)实现代码的持续优化。反射协调器控制反思循环,设置质量阈值、迭代限制等条件确保高效退出。案例展示了一款质数过滤函数如何从初版65分优化至92分,体现了AI从"执行工具"到"学习实体"的进化。这一机制使AI具备元认知能力,在不依赖人类反馈的情况下自主改进,标志着AI能力的重要跃迁。
文章全面分析了AI Agent的定义、能力水平划分(L0-L5)、模态分类和应用场景。重点探讨了Agent的核心架构、Plan模块(任务分解、反思和提炼)以及评测体系,并对多个开源项目(Dify、langflow、MetaGPT等)进行了深度评测。指出当前Agent项目主要集中在流程编排阶段(L2),未来将朝着多模态、个性化和群体智能方向发展,为开发者提供了全面的Agent开发参考。

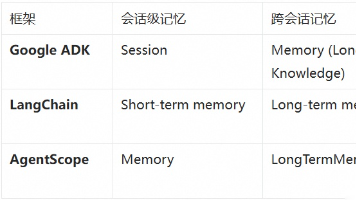
本文详细介绍了AI Agent记忆系统的概念、分类及实现架构,包括短期记忆的上下文工程策略(压缩、卸载、摘要)和长期记忆的技术架构(记录与检索流程)。文章对比了Google ADK、LangChain和AgentScope等主流框架的记忆系统实现,分析了行业发展趋势,并提供了Mem0等长期记忆组件的集成方案,为构建高效、个性化的AI Agent提供了技术指导。
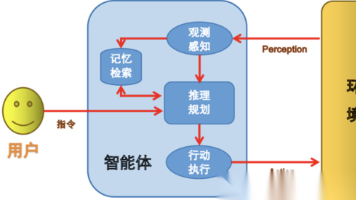
本文全面介绍了AI智能体(Agent)的原理与实现,包括智能体的定义、特征与传统LLM应用的区别,以及构建智能体的三要素(模型、工具、指令)。文章详细讲解了智能体的编排模式(单智能体/多智能体系统)和护栏体系,并通过LangGraph框架提供了最小可运行智能体的代码示例。智能体的本质是执行任务而非简单对话,适合处理模糊性和上下文判断的场景。
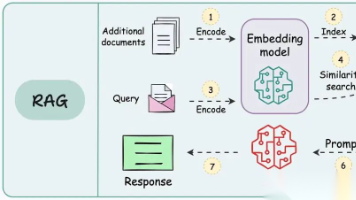
本文详细介绍RAG(检索增强生成)系统,通过手把手教学解决大模型知识冻结和幻觉问题。文章从RAG原理出发,详解数据准备、检索工程和结果生成三大阶段,提供开源技术栈实战代码,并讨论系统局限性。强调在AI项目中,80%时间应投入数据工程和检索策略优化,确保大模型能基于准确资料生成可靠回答。
文章通过"新员工"的生动比喻解释了大模型智能体(Agent)的工作原理。智能体如同职场新人,需要通过"系统提示词"了解角色职责,配备"工具"完成工作。其流程是:理解任务→尝试解决→根据反馈优化。开发者需优化提示词、工具和模型来提升智能体表现,使其能更好地处理复杂问题。