- @Andy_shenzl
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
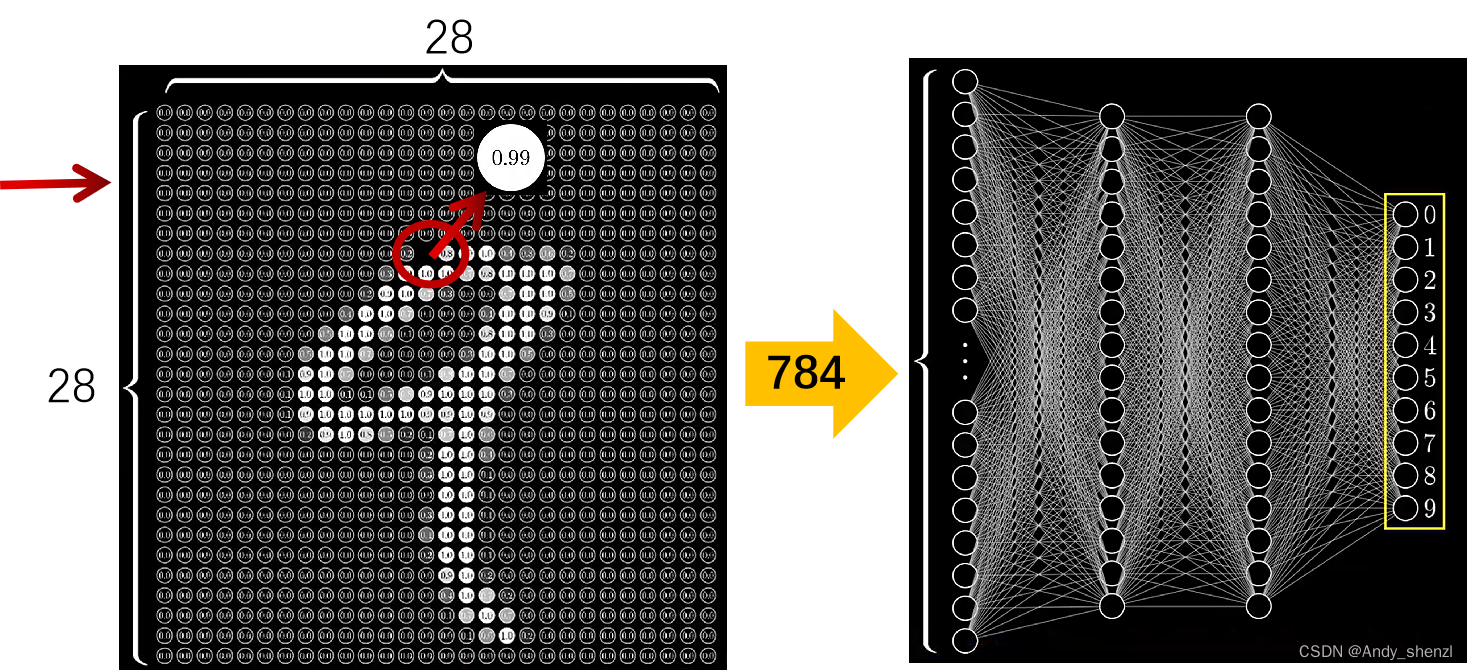
DeepSeek-OCR以“上下文光学压缩”的理论创新为基石,以轻量部署、高精度解析、全场景适配为核心优势,打破了传统OCR与通用VLM之间的能力鸿沟。它不仅是一款OCR工具,更是多模态时代连接视觉信息与文本知识的关键桥梁,为科研创新、企业数字化转型、个人高效办公提供了强大动力。随着多模态RAG技术的普及,DeepSeek-OCR正成为文档理解领域的“标配引擎”,推动数字化处理迈入“精准理解”的新
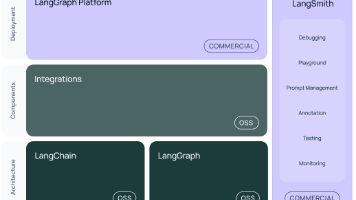
根据前面的内容,在对LangChain 1.0有了一定的基础了解之后,对于开发者来说,还需要进一步了解和掌握LangChain Agent必备的开发者套件。分别是LangChain Agent运行监控框架LangSmith、底层LangGraph图结构可视化与调试框架LangGraph Studio和LangGraph服务部署工具LangGraph Cli。可以说这些开发工具套件,是真正推动Lan
PyTorch DNN回归实战

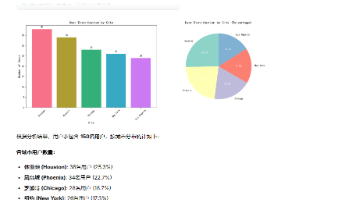
模块技术组件说明PDF 问答构成 RAG 检索增强流程CSV 分析实现代码生成 + 可视化LLM统一 Agent 调用向量库支持中文语义匹配UIStreamlit + 自定义 CSS提供多 Tab 页面与交互式聊天状态管理管理历史、数据、图片等上下文PDF相关功能解说见上篇文章,这里主要对数据分析功能进行说明Step 1. CSV 文件上传与 DataFrame 显示。
定义LSTM模型else:具体解析可参考RNN代码解析唯一的不同这里介绍下,就是RNN没有cell,所以这里需要加上。在模型中,这行代码是对RNN层的最后一个时间步的隐藏状态应用dropout正则化。hidden: 这是RNN层的输出之一,表示隐藏状态。对于每个时间步,RNN会产生一个隐藏状态。如果RNN是多层(n_layers大于1),那么每个时间步的隐藏状态会经过所有的层。因此,hidden的

它们只是额外工具没配置,不影响你用 Hermes 进行本地对话、代码执行、浏览器自动化、文件操作等基础功能。说明:Hermes 已经装好,并且 DeepSeek API 也配置成功了。命令加入用户 PATH。官方说明里,这个安装器会自动处理。安装 Hermes 时推荐用。检查关键项是否通过检查。
LangChain框架为LLM应用开发提供全流程支持,通过标准化接口(LCEL/Tool/Retriever)降低集成成本,实现模型快速切换。核心组件包括:基础框架LangChain支持模块化构建;LangGraph实现复杂工作流编排;LangSmith提供开发生产可观测性;LangFlow实现低代码可视化开发。该生态覆盖从简单链到多智能体系统的全谱系需求,通过分层架构(LCEL轻量编排↔Lang
模块技术组件说明PDF 问答构成 RAG 检索增强流程CSV 分析实现代码生成 + 可视化LLM统一 Agent 调用向量库支持中文语义匹配UIStreamlit + 自定义 CSS提供多 Tab 页面与交互式聊天状态管理管理历史、数据、图片等上下文PDF相关功能解说见上篇文章,这里主要对数据分析功能进行说明Step 1. CSV 文件上传与 DataFrame 显示。
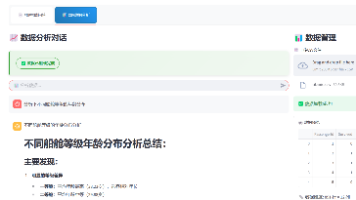
titanic数据集Titanic数据集是机器学习领域经典的入门数据集,记录了1912年泰坦尼克号沉船事件中部分乘客的生存信息。该数据集常用于分类任务(预测乘客是否幸存)和数据探索分析。你可以访问一个名为 `df` 的 pandas 数据框,请根据用户提出的问题,编写 Python 代码来回答。只返回代码,不返回其他内容。只允许使用 pandas 和内置库。"""])chain.invoke({"