




- @Ai17316391579
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
【WAIC2026前瞻:聚焦AI规模落地与产业赋能】本届世界人工智能大会以"去泡沫、重落地"为主基调,呈现四大核心赛道:1)垂直化大模型转向行业适配;2)国产算力全链条突破;3)具身智能机器人实景应用;4)千行百业智能化解决方案。大会将展示AI从技术突破到产业渗透的全景图,通过高峰论坛、实景演示和行业报告释放商业化信号,为不同观众提供差异化的技术对接与体验场景,标志着AI发展进

【WAIC2026前瞻:聚焦AI规模落地与产业赋能】本届世界人工智能大会以"去泡沫、重落地"为主基调,呈现四大核心赛道:1)垂直化大模型转向行业适配;2)国产算力全链条突破;3)具身智能机器人实景应用;4)千行百业智能化解决方案。大会将展示AI从技术突破到产业渗透的全景图,通过高峰论坛、实景演示和行业报告释放商业化信号,为不同观众提供差异化的技术对接与体验场景,标志着AI发展进
4090没有涡轮版,多卡机器配置会受到限制,以单台机器对比会比较合理,最大10卡3090平台只能配置5卡4090,以上简单分析,希望对配置4090GPU服务器的您有所帮助参考。,目前价位(12999~17000)x5=3090单精度浮点35.7TFLOPs。4090单精度浮点73TFLOPs。,目前价位13000x10=从单精度浮点计算能力来讲,10块RTX3090是。5块RTX4090是。

对于预算有限的用户,可以选择性价比较高的V100 32G或A800/H800等型号的GPU。它采用了先进的Ampere微架构,具备强大的浮点运算能力和高效的内存带宽,能够满足大模型训练推理的高计算需求。此外,还需要考虑GPU的散热性能,以确保在高负载运行时能够保持稳定的温度。这类配置不仅能够满足大规模模型的训练需求,还能提供优秀的推理性能,为用户带来流畅的使用体验。服务器,入围政采平台,H100、
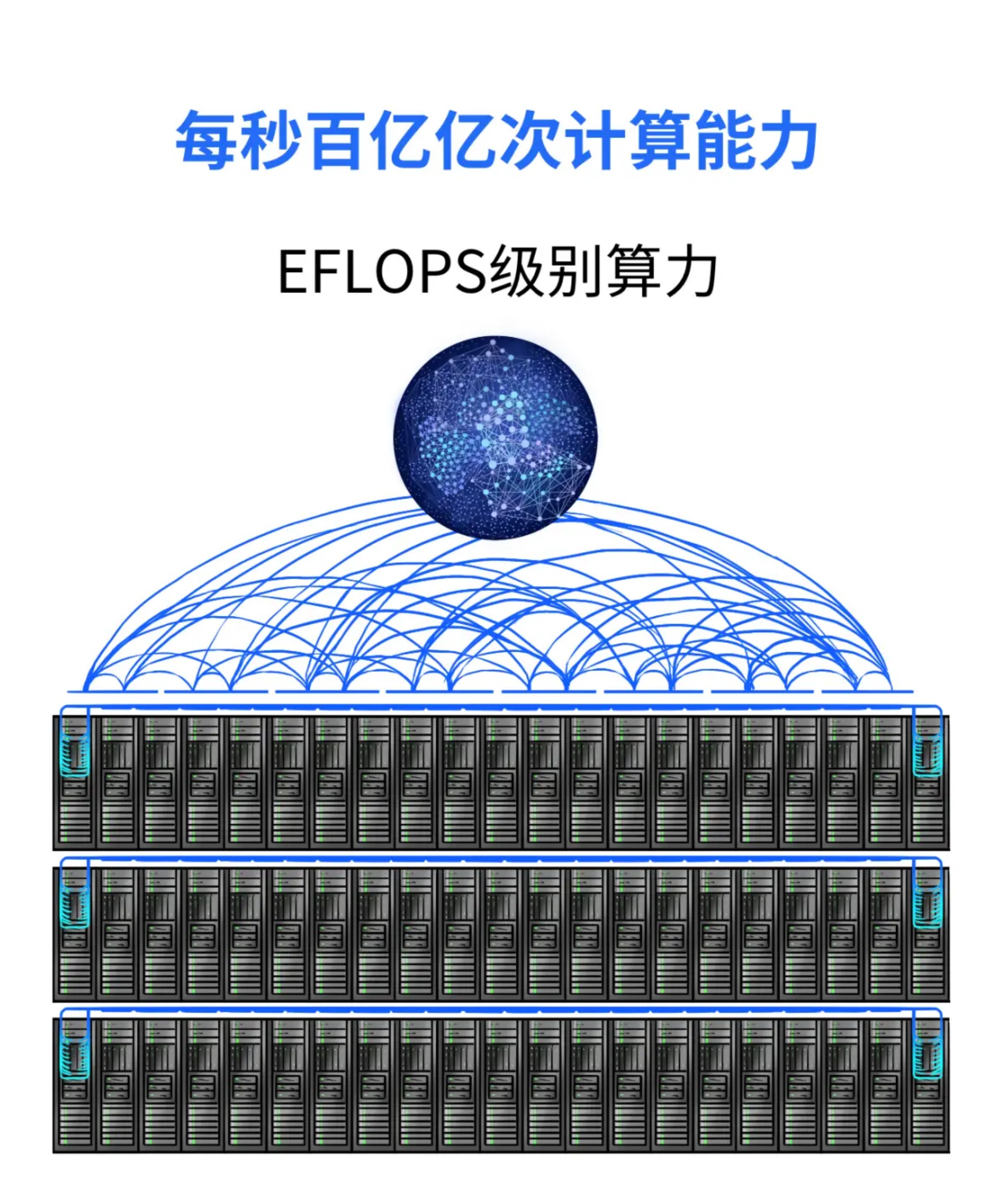
直白点说是性价比,不一定是最好的产品,但一定是最符合市场的才能被市场接受,并不是商家定义就一定是定义的样子。专业工程师团队和严格规范的服务器生产测试流程,对产品本身稳定性和适应性问题反复实验测试,提供解决方案,为您把关,保障了产品品质。英伟达RTX4090上市有一段时间了,奈何市场缺货,受大功率和槽位限制,以及产品本身稳定性和适应性问题都有待测试。每个产品上市前,虽然都会给各实验室做一些测试,出测

作为计算机的图形处理以及并行计算内核,GPU最基本的功能是图形显示和分担CPU的计算量,主要可以分为图形图像渲染计算 GPU和运算协作处理器 GPGPU(通用计算图形处理器),后者去掉或减弱GPU的图形显示能力,将其余部分全部投入通用计算,实现处理人工智能、专业计算等加速应用。上述负责人认为,国产GPU业应采取开放合作的心态,学会站在巨人的肩膀上,善于利用现有架构和生态,设计契合市场需求的优秀产品

2026年AI技术爆发:机遇与挑战并存 2026年,AI已深度融入各行业:从办公自动化到工业制造,从科研辅助到创意设计。AI智能体不仅能完成重复性工作,更展现出规划决策能力,企业AI应用渗透率预计达40%。但AI的局限同样明显:缺乏情感共鸣与创造力突破,仅能优化现有模式而无法开创全新领域。技术演进带来的不仅是效率提升,也面临能源消耗、伦理安全等新挑战。AI本质是人类的超级助手;,其发展将重塑而非取

例如,在探讨H100时所展现的设计,GPU直接与其搭载的HBM内存相连,无需再经过PCIe交换芯片,从而极大地提高了数据传输速度,理论上可实现显著的数量级性能提升。而在诸如PCIe、内存、NVLink及HBM等其他硬件组件中,带宽指标则通常使用每秒字节数(Byte/s)或每秒事务数(T/s)来衡量,并且这些测量值一般代表双向总的带宽容量,涵盖了上行和下行两个方向的数据流。因此,在比较评估不同组件之
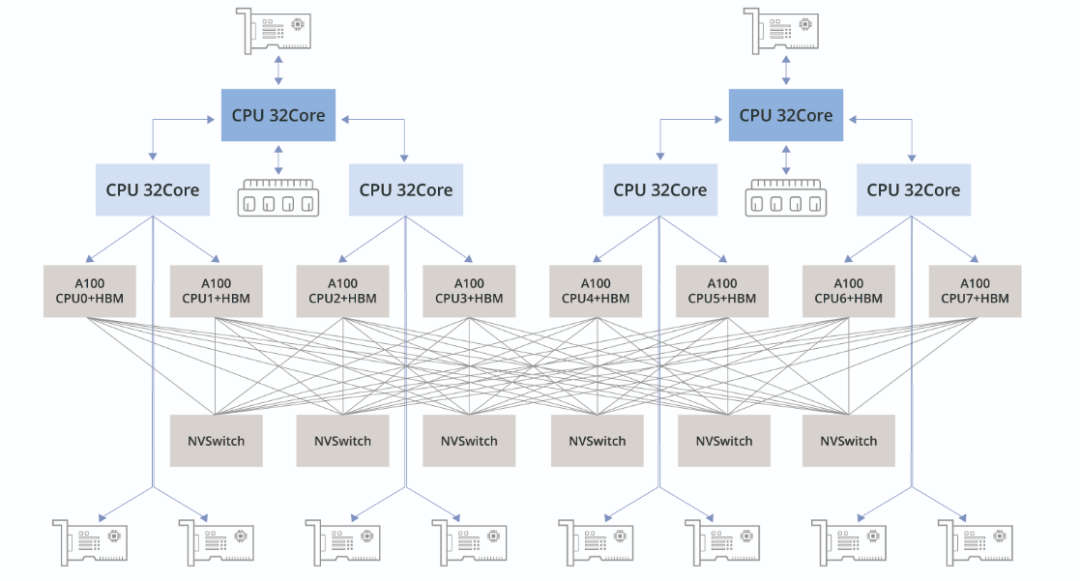
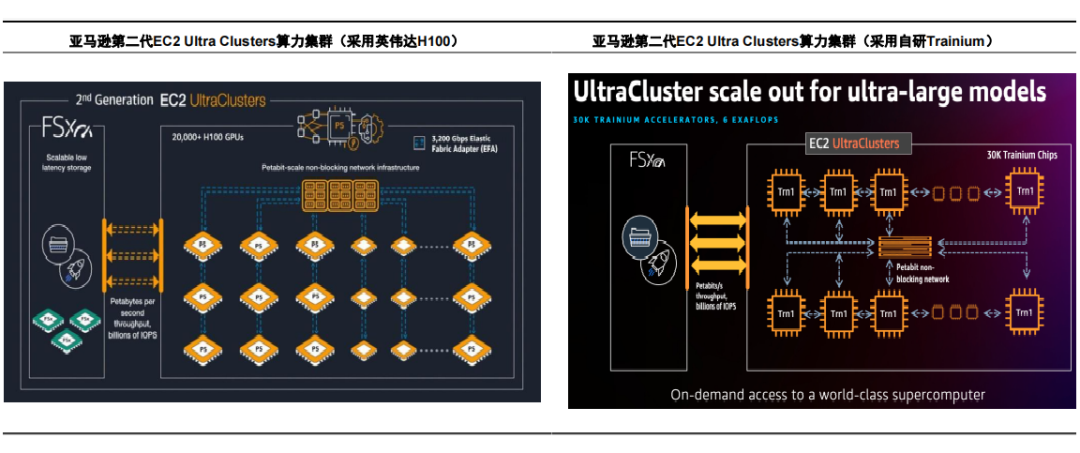
由于NVLink 4.0对应互联带宽双向聚合是900GB/s,单向为450GB/s,则256卡的集群中,接入层总上行带宽为115200GB/s,考虑胖树架构以及800G光模块传输速率(100GB/s),800G光模块总需求为2304块。RSC项目第二阶段,Meta总计部署2000台A100服务器,包含16000张A100 GPU,集群共包含2000台交换机、48000条链路,对应三层CLOS网络架
如果你可以为你的集群购买 RTX GPU:66% 的 8路RTX 4080 和 33% 的 8路RTX 4090(要确保能有效地冷却)。如果解决不了 RTX 4090 的冷却问题,那么可以购买 33% 的 RTX 6000 GPU 或 8路Tesla A100。任何专业绘图显卡(如Quadro 卡);进一步学习,卖掉你的 RTX 4070,并购买多路RTX 4090。根据下一步选择的领域(初创公司
