




- @Ahri_J
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
没有在 Wiki 中找到关于孤儿 socket 的定义,在 StackOverflow 中找到了一个比较通俗易懂的解释:下面一段是 DeepSeek 给出的解释:总的来说就是当程序调用 close() 函数关闭 socket 后,socket 就和应用程序无关了,但此时 TCP 终止流程还没有走完,所以内核里还有这些 socket 的数据,这些 socket 就是所谓的孤儿 socket。下面我们

数据的接收和处理流程分析完了,本篇我们来看下数据的发送流程。【挖坑待填。。。
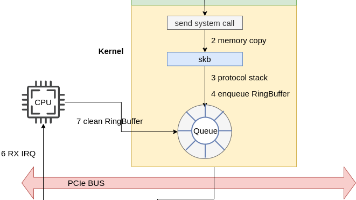
数据的接收和处理流程分析完了,本篇我们来看下数据的发送流程。【挖坑待填。。。
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一 ID 做标识。此时一个能够生成全局唯一ID 的系统是非常必要的。本文主要介绍一些常见的分布式唯一 ID 生成方案。

在分布式系统中,强一致性往往和高可用、高吞吐是矛盾的。比如传统的关系型数据库,其保证了强一致性,但往往牺牲了可用性和吞吐量。而像 NoSQL 数据库,虽然其吞吐量、和扩展性很高,但往往只支持最终一致性,无法保证强一致性。由此提出了链式复制协议,旨在保证高吞吐、高可用的同时,支持数据的强一致性。

文章目录一. 报名 & 预约1. 报名2. 预约二. 考试简介 & 备考建议1. 考纲介绍2. 考官检查事项1. 开启摄像头 & 电脑桌面分享2. 检查办公桌面 & 房间环境3.考试界面简介4. 考试建议【1】准备好 VPN【2】快速浏览题目【3】注意题目要求的上下文【4】启用 kubectl 自动提示【5】提前整理好文档收藏三. 考试题目简记四. 备考资料推荐一.

最近项目遇到个需求,需要将后端的服务器出口统一成一个 IP,服务器在 AWS 上,这个可以用 AWS 的 NAT Gateway 实现,调研实施的过程中发现如果对 AWS 相关概念的话不熟悉还是会绕点路的,简单整理下 NAT Gateway 的使用,希望对需要的小伙伴有帮助。一. 相关概念简介1. NAT GatewayNAT Gateway(网络地址转换网关) 主要用来对一组私有子网内的服...
ELK 是 ElasticSearch、 LogStash、 Kibana 三个开源工具的简称,现在还包括 Beats,其分工如下:LogStash/Beats: 负责数据的收集与处理ElasticSearch: 一个开源的分布式搜索引擎,负责数据的存储、检索和分析Kibana: 提供了可视化的界面。负责数据的可视化操作基于 ELK Stack 可以构建日志分析平台、数据分析搜索平...
文章目录1. mTLS2. 认证2.1 ServiceAccount2.2 用户生成私钥与 CSR创建 Certificate Signing Request批准 Certificate Signing Request3. Kubeconfig4. 授权4.1 RBAC4.1.1 Roles & ClusterRoles4.1.2 RoleBinding & ClusterRole
最近学习用 Scrapy 框架写爬虫,将学习过程中用到的解析技术,Scrapy 的各个模块使用与进阶到分布式爬虫学到的知识点、遇到的问题以及解决方法记录于此,以作总结与备忘,也希望对需要的同学有所帮助。本篇主要讲解 pipeline 保存数据模块的使用,包括将数据存储为 Json 文件,存储到 MySQL 数据库以及图片的下载