- @ADICDFHL
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
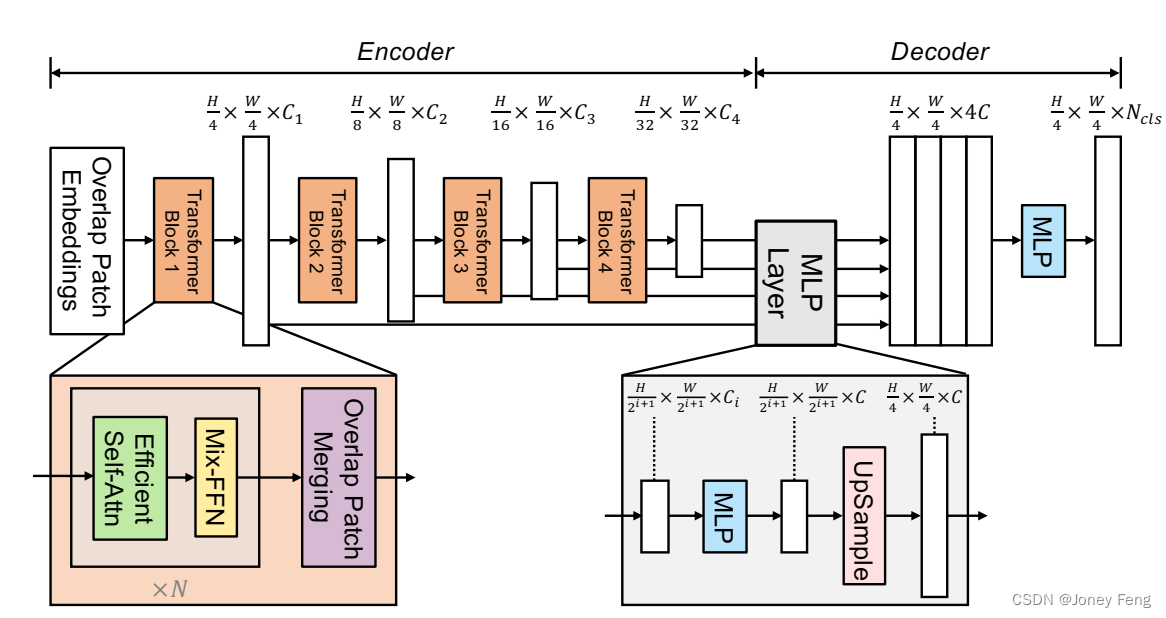
我们提出了SegFormer,这是一个简单、高效且强大的语义分割框架,它将Transformer与轻量级多层感知机(MLP)解码器结合在一起。SegFormer具有两个吸引人的特点:1)SegFormer包含一个新颖的层次结构的Transformer编码器,它输出多尺度特征。它不需要位置编码,从而避免了位置编码的插值问题,当测试分辨率与训练不同时,导致性能下降。2)SegFormer避免了复杂的解
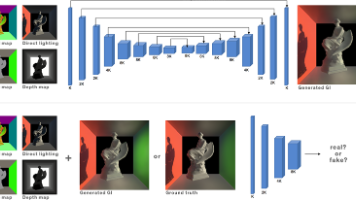
我们提出了深度照明,一种新颖的机器学习技术,利用条件生成对抗网络(Conditional Generative Adversarial Network)在实时应用中逼近全局光照(GI)。我们的主要关注点是以交互速率生成具有离线渲染质量的间接光照和软阴影。受近期使用深度生成卷积网络解决图像到图像转换问题的进展启发,我们引入了一种该网络的变体,它学习从G缓冲(深度图、法线图、漫反射图)和直接光照到任意
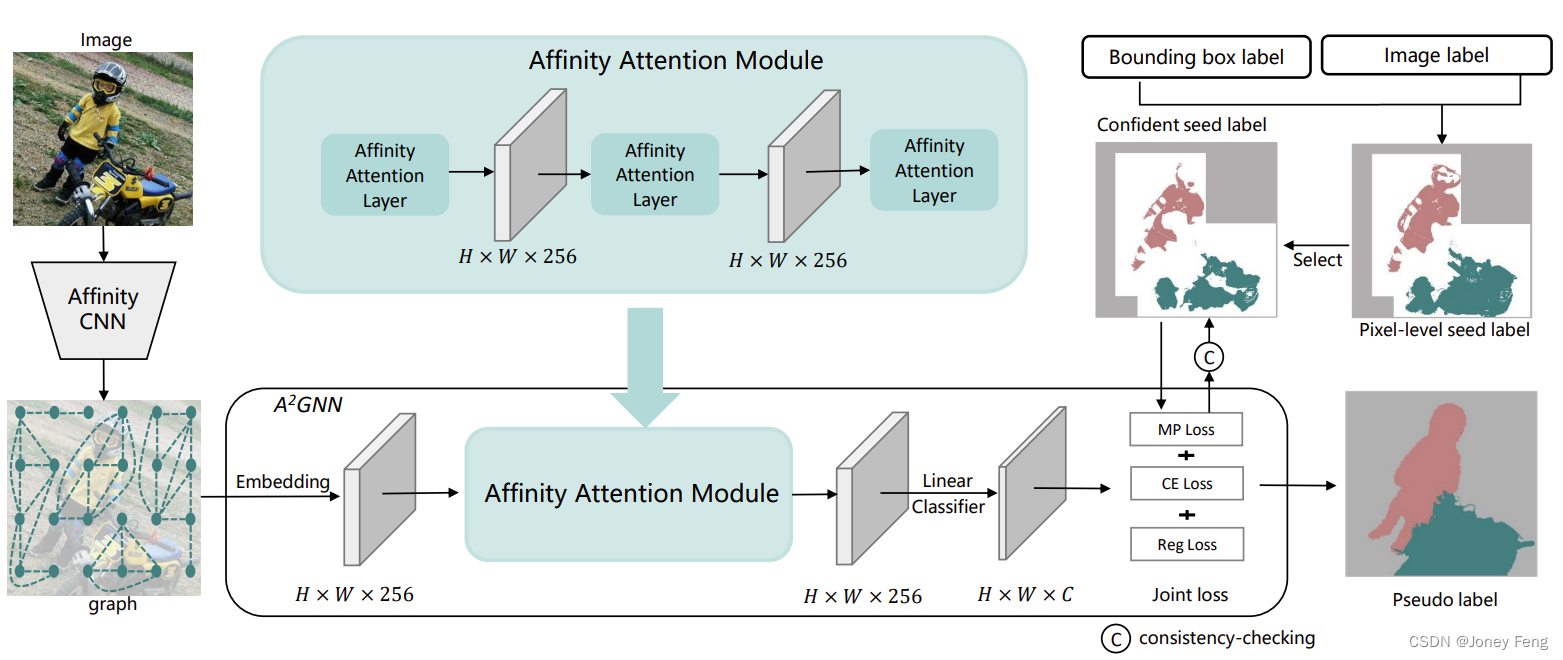
弱监督语义分割因其较低的人工标注成本而受到广泛关注。本文旨在解决基于边界框标注的语义分割问题,即使用边界框注释作为监督来训练准确的语义分割模型。为此,我们提出了亲和力注意力图神经网络(A2GNN)。按照先前的做法,我们首先生成伪语义感知的种子,然后基于我们新提出的亲和力卷积神经网络(CNN)将其形成语义图。然后,构建的图被输入到我们的A2GNN中,其中一个亲和力注意力层被设计用来从软图边缘获取短距
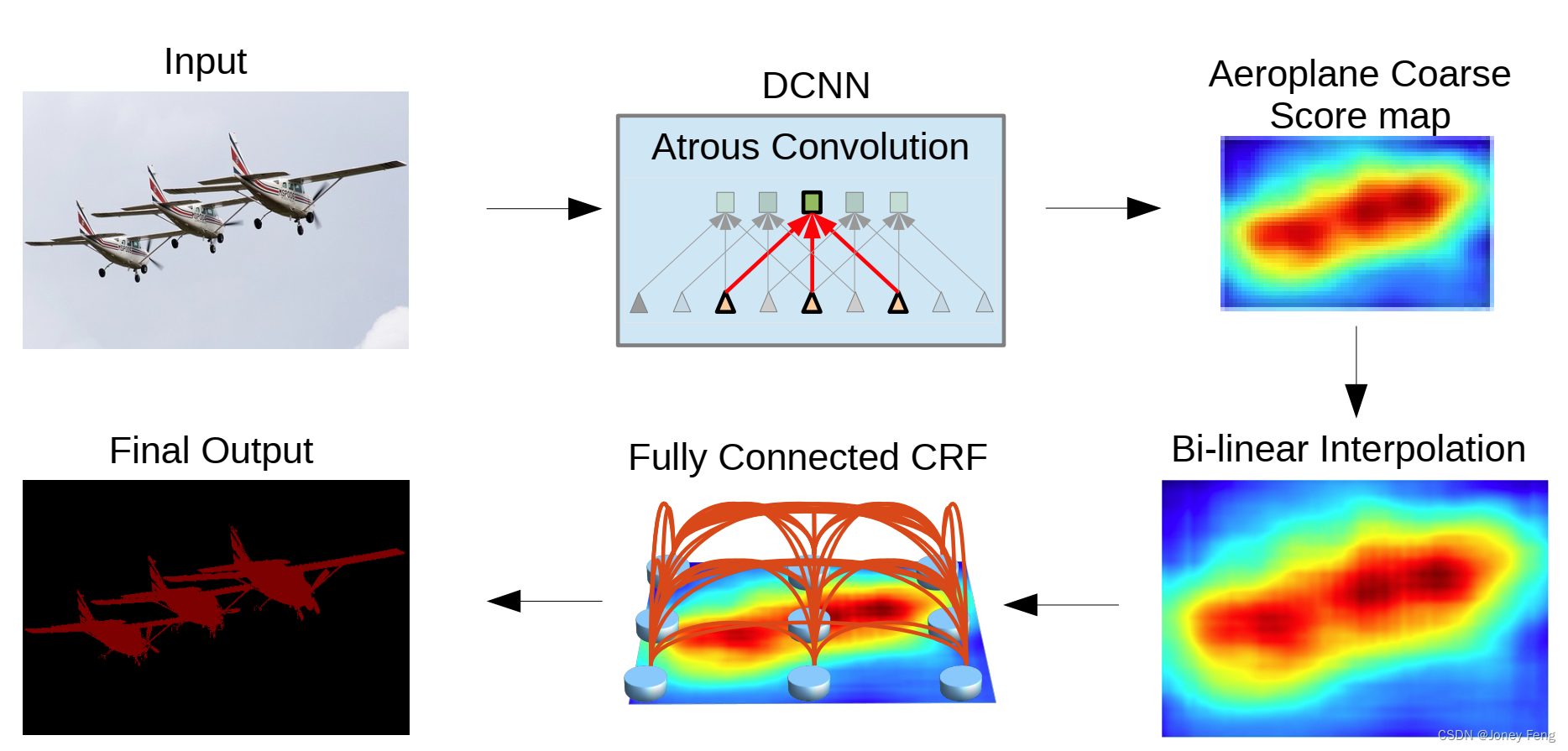
0.摘要在这项工作中,我们使用深度学习来解决语义图像分割任务,并做出了三个实验证明具有实际价值的主要贡献。首先,我们强调通过上采样滤波器进行卷积,或者称为“空洞卷积”,在密集预测任务中是一种强大的工具。空洞卷积允许我们在深度卷积神经网络中明确控制特征响应计算的分辨率。它还可以在不增加参数或计算量的情况下有效地扩大滤波器的视野以包含更大的上下文。其次,我们提出了空洞空间金字塔池化(ASPP),以稳健
在本文中,我们仔细研究了深度CNN中的感受野,并建立了关于有效感受野大小的一些令人惊讶的结果。特别是,我们已经证明了感受野内的影响分布渐近地呈高斯分布,而有效感受野只占据了理论感受野的一部分。实证结果与我们建立的理论相吻合。我们相信这只是对有效感受野研究的一个开端,它提供了一种理解深度CNN的新角度。未来,我们希望进一步研究实践中影响有效感受野的因素,以及如何更好地对其进行控制。

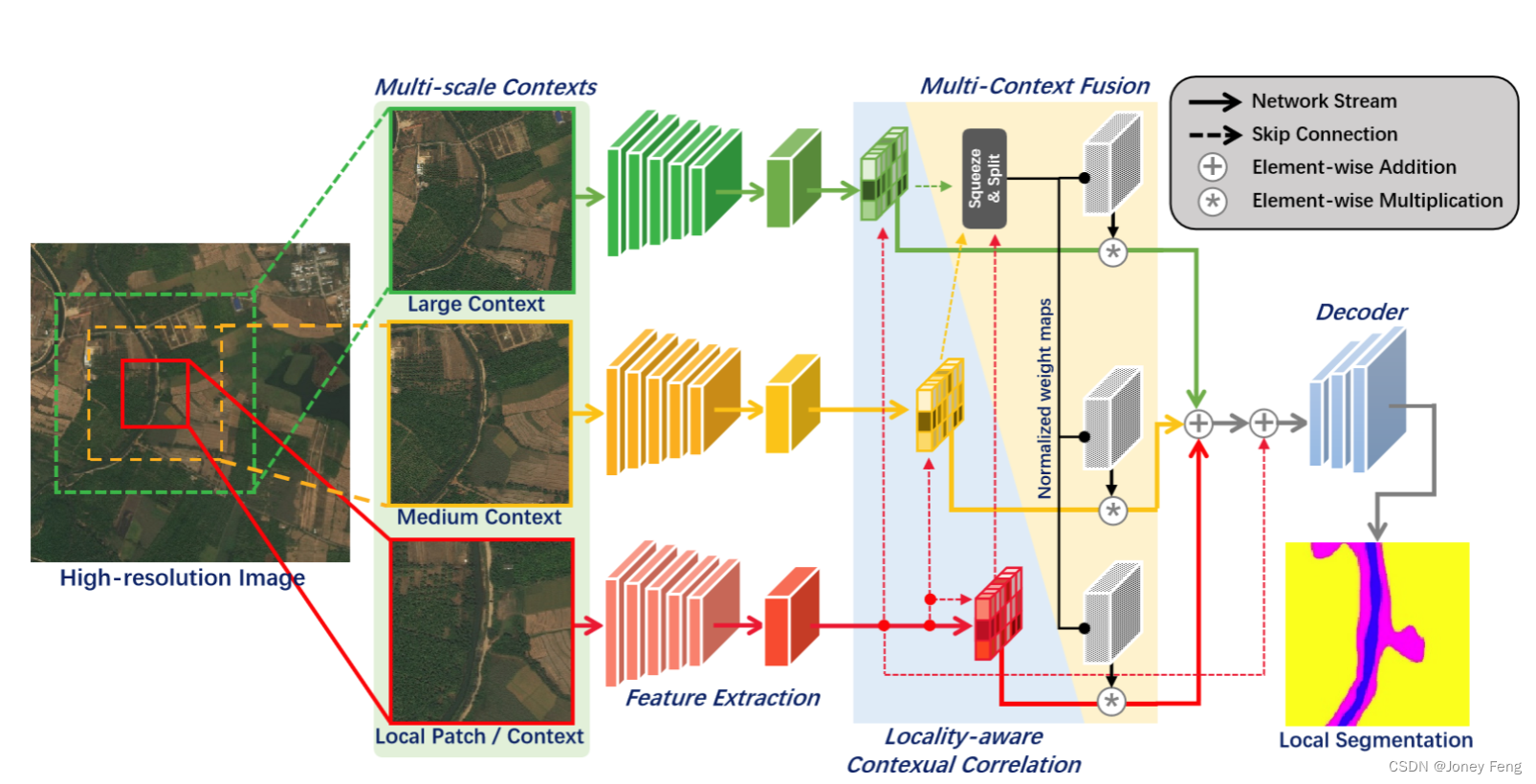
我们引入了一种基于局部感知上下文相关性的分割模型来处理局部图像补丁。此外,我们还提出了一种上下文语义细化网络,能够在创建最终高分辨率掩码的过程中减少边界伪影并优化掩码轮廓。
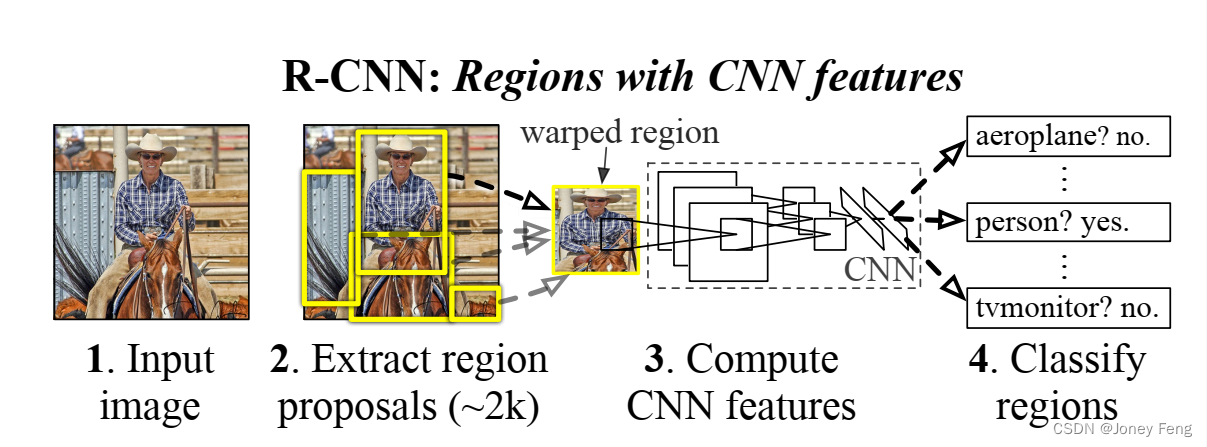
特征很重要。过去十年在各种视觉识别任务上取得的进展主要基于SIFT [29]和HOG [7]的使用。但是如果我们看一下在经典的视觉识别任务PASCAL VOC目标检测 [15]上的表现,普遍认为在2010年至2012年期间进展缓慢,只通过构建集成系统和使用成功方法的轻微变体获得了小幅增益。SIFT和HOG是基于块状方向直方图的表示方法,我们可以将其粗略地与灵长类动物视觉通路中的V1区的复杂细胞相关
0.摘要在这项工作中,我们使用深度学习来解决语义图像分割任务,并做出了三个实验证明具有实际价值的主要贡献。首先,我们强调通过上采样滤波器进行卷积,或者称为“空洞卷积”,在密集预测任务中是一种强大的工具。空洞卷积允许我们在深度卷积神经网络中明确控制特征响应计算的分辨率。它还可以在不增加参数或计算量的情况下有效地扩大滤波器的视野以包含更大的上下文。其次,我们提出了空洞空间金字塔池化(ASPP),以稳健
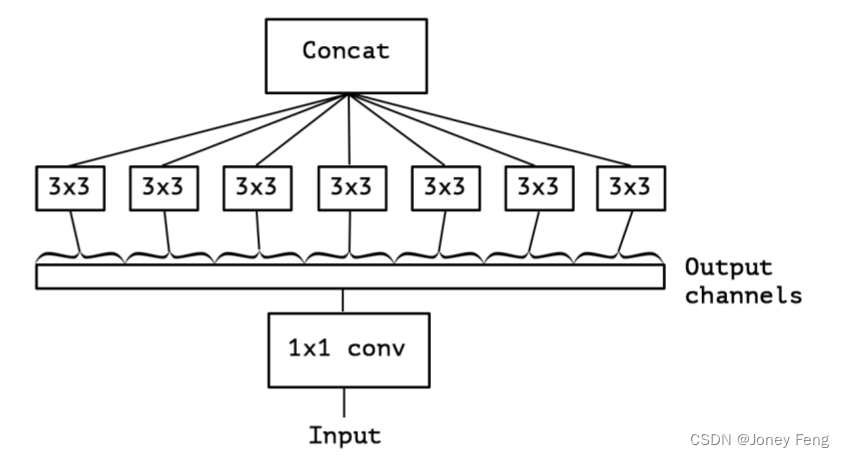
我们将卷积神经网络中的Inception模块解释为常规卷积和深度可分离卷积操作之间的中间步骤。在这个视角下,深度可分离卷积可以被理解为具有最大数量塔的Inception模块。这个观察引导我们提出了一个新颖的深度卷积神经网络架构,灵感来自Inception,其中Inception模块被深度可分离卷积所替代。
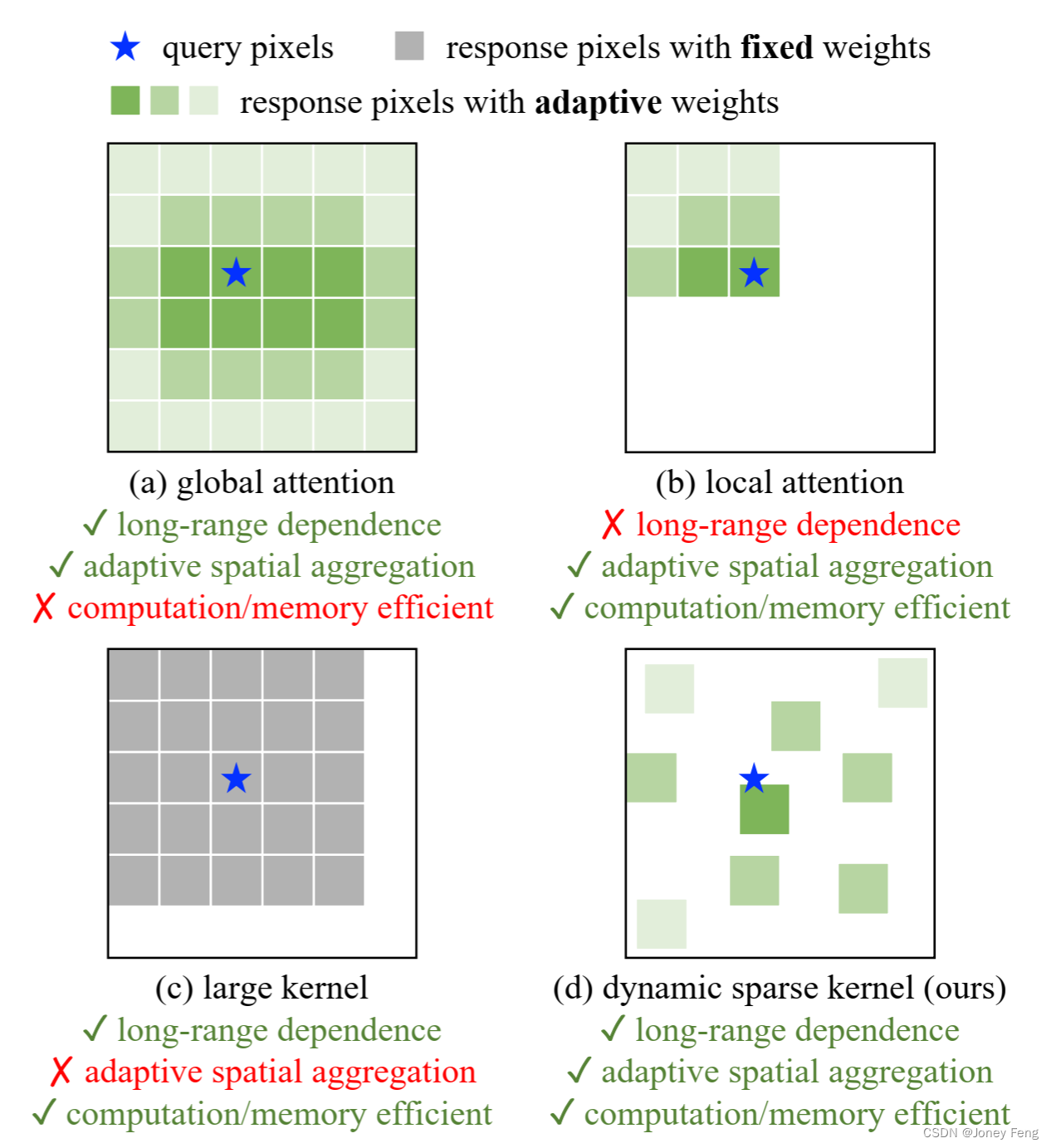
相较于近年来大规模视觉Transformer(ViT)取得的巨大进展,基于卷积神经网络(CNN)的大规模模型仍处于早期阶段。本文提出了一种新的基于CNN的大规模基础模型,称为InternImage,它可以像ViTs那样从增加参数和训练数据中获益。与近期专注于大型密集卷积核的CNN不同,InternImage将可变形卷积作为核心运算符,因此我们的模型不仅具有下游任务(如检测和分割)所需的大有效感受野