- @2501_93716422
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
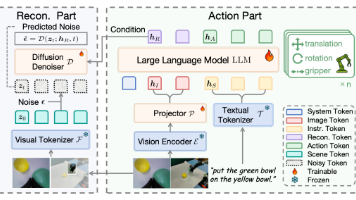
本文提出ReconVLA模型,通过隐式视觉grounding机制提升机器人操作精度。该方法让模型在训练中重建任务相关的凝视区域,引导视觉注意力聚焦目标物体。模型包含动作生成和视觉重构两个部分,使用扩散变换器从噪声中重建目标区域。
ICCV 2023 公布多项重磅奖项:CMU团队凭借BrickGPT获最佳论文奖,该研究实现了从文本生成物理稳定的3D积木结构。

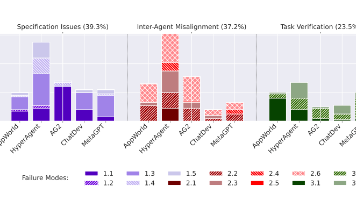
摘要:本文系统研究了多智能体LLM系统(MAS)的失败模式,提出首个基于实证的分类法MAST,涵盖14种细粒度失败模式(如规范违反、智能体不对齐、验证失败等)。通过分析5个主流MAS框架在150+任务中的表现,发现即使使用GPT-4o等强大模型,失败率仍高达75%,且系统设计缺陷是主因。研究采用扎根理论构建分类法,开发了LLM自动标注流程(准确率94%),并通过干预实验验证了MAST的实用性(如C
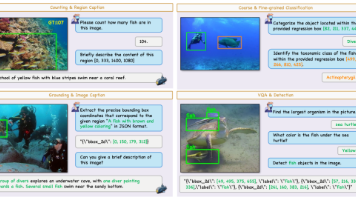
华中科技大学与国防科技大学联合提出首个水下多模态大模型NAUTILUS,突破传统水下视觉任务的局限。该研究创新性地构建了包含145万图像-文本对的NautData数据集,并设计了基于物理成像模型的视觉特征增强模块(VFE),在特征空间显式恢复水下退化图像信息。实验表明,NAUTILUS在8类水下任务中表现优异,显著提升识别准确性,且VFE模块可兼容主流多模态模型。研究成果为水下场景理解提供了新思路
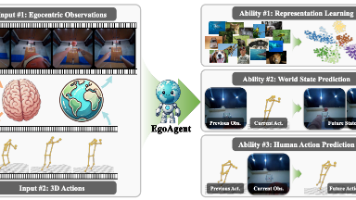
论文摘要:本文提出EgoAgent,首个能统一学习第一人称环境表示、预测未来状态并生成三维动作的智能体模型。通过联合嵌入-动作-预测(JEAP)架构,采用交错序列建模和时间不对称的预测-观察机制,实现了三项任务的协同优化。
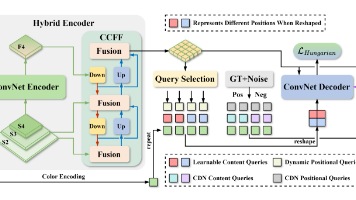
U-DECN的核心思路是在卷积编码器-解码器架构中引入多尺度特征、动态查询初始化与颜色去噪机制,以提升检测精度与速度,同时避免使用NMS和复杂注意力模块。U-DECN在卷积编码器-解码器架构中成功融合了多尺度特征、动态查询与颜色去噪机制,显著提升了水下目标检测的精度与速度,并在嵌入式设备上实现实时推理。的端到端水下目标检测模型,它基于卷积网络架构,融合了多尺度特征、动态查询初始化与颜色去噪机制,显
YOLO系列目标检测算法发展综述 YOLO系列从2015年至今已迭代至v13版本,始终追求速度与精度的平衡。核心创新包括:v1首创单阶段端到端检测;v2引入锚框和多尺度训练;v3采用深度残差网络和三尺度输出;v4系统整合工程优化技巧;v5完善PyTorch生态链;v6-v8逐步实现Anchor-Free和多功能统一;v9改进梯度信息流;v10消除NMS后处理;最新版本开始融合注意力机制和超图建模。

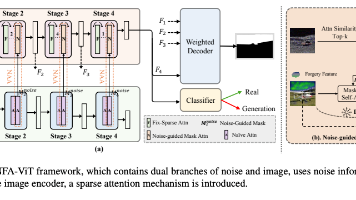
本文提出BR-Gen数据集和NFA-ViT模型,针对AI生成图像中背景/场景等局部篡改检测难题。通过噪声引导注意力机制增强伪造特征传播,结合加权解码器提升定位精度。实验表明,该方法在BR-Gen数据集上F1达0.972,IoU达0.907,并展现强泛化能力。研究为局部伪造检测提供了新思路,但噪声提取质量对效果影响较大,未来需优化轻量化部署。
YOLO系列目标检测算法发展综述 YOLO系列从2015年至今已迭代至v13版本,始终追求速度与精度的平衡。核心创新包括:v1首创单阶段端到端检测;v2引入锚框和多尺度训练;v3采用深度残差网络和三尺度输出;v4系统整合工程优化技巧;v5完善PyTorch生态链;v6-v8逐步实现Anchor-Free和多功能统一;v9改进梯度信息流;v10消除NMS后处理;最新版本开始融合注意力机制和超图建模。
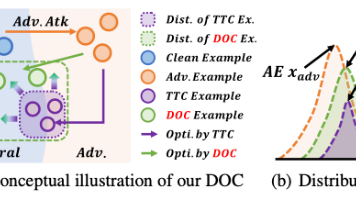
本文提出了一种名为“方向正交反攻击”(DOC)的新方法,用于增强视觉-语言预训练模型(VLP)对抗对抗样本的鲁棒性。针对现有测试时反攻击(TTC)方法扰动单一的问题,DOC通过引入正交梯度增强和动量机制,生成更具多样性的反攻击扰动,有效中和多种对抗攻击。