




- @2501_92464201
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
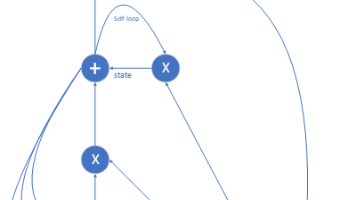
本文从 LLaMA 的核心设计出发,拆解并实现了一个轻量级的 LLaMA-like 模型,覆盖了 RMSNorm、SwiGLU、RoPE、因果自注意力等关键组件。大模型看似复杂,但本质是 “简单组件的有序组合”—— 掌握这些核心设计,就能理解大模型的底层逻辑,为后续的模型训练、优化和部署打下基础。训练模型:用小数据集(如 WikiText)训练模型,观察 Loss 的下降趋势;扩展参数:将调至 4
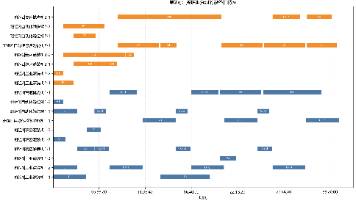
这次项目最终形成了一条比较完整的建模工程链路:从附件数据解析开始,构造工序和设备数据结构;再用事件驱动解码器处理设备分配、跨车间运输和同步完工;最后通过启发式搜索、自动校验和可视化输出形成可复盘结果。真实结果上,第 1 问得到 A 车间最短时长;第 2 问单班组完成五车间的当前最好可行解为;第 3 问双班组协同后降至,比第 2 问缩短47126 s,约27.56%。对我来说,这道题最值得保留的不是
官方文档:NumPy/Pandas/Matplotlib 官网(中文翻译版)练习数据集:Kaggle 入门数据集、阿里云天池工具:Jupyter Notebook(全程实战),不可逆权重分配:Pandas 占 60% 精力,重点练数据清洗、分组聚合学习节奏:4 周,每天 1-2 小时,边敲代码边学恭喜你!学完这篇文章,你已经掌握了数据分析三剑客的入门核心技能,能独立完成数据读取、清洗、统计、可视化
这段代码没有把所有东西塞进一个函数,而是按照“打标签 -> 算电量 -> 算钱”的逻辑拆分成了三个独立函数。它接收一串历史负荷数据,通过内部的矩阵运算,输出未来指定步长(默认2小时)的预测数据。这一句直接解决了图表中文显示为方块的痛点,是写 Python 数据分析脚本的标配起手式。是一个非常实用的高阶技巧。弹窗)放在最后一步,确保了控制台的计算结果能第一时间打印出来,提升了用户体验。如果只画预测点
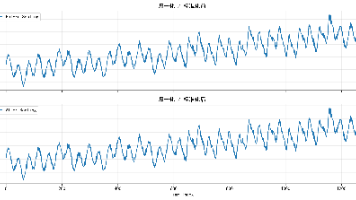
做时间序列预测这些年,我越来越清楚一件事:很多模型单独看都很强,但真到项目里,真正拉开差距的,往往不是“某一个模块有多新”,而是整条链路有没有闭环。数据怎么来,缺失值怎么补,非平稳信号怎么拆,特征怎么组织,模型怎么融合,训练怎么稳,结果怎么解释,图怎么画,这些事情如果没有一口气串起来,最后往往只会停留在“搭了个网络”的层面。这次我想做的,不是一个只有论文味道的模型名词堆叠,而是一个真正能从原始序列
参数边界设定: [神经元数量, Dropout率, 学习率, 迭代次数]# 注意:实际应用中可按需调整范围'units': [10, 100], # 整数'dropout': [0.1, 0.5], # 浮点数'lr': [0.001, 0.05], # 浮点数'epochs': [10, 50] # 整数# 2. 构建与评估 LSTM 模型 (适应度计算核心)# 训练模型 (为了GA搜索速度,这
很多人开始用 Claude Code 之后,会很快喜欢上它的工作方式:不是简单地问答,而是直接进项目目录、读代码、改文件、协助调试。如果我想保留 Claude Code 这套命令行工作流,但底层模型不想只用默认方案,能不能接入 DeepSeek V4?这不是 Claude Code 的“默认官方模型切换功能”,而是通过 Anthropic 兼容 API 的方式,把 Claude Code 的请求路
本文通过 Tkinter 搭建了一个轻量级的 DeepSeek 多功能 GUI 工作站,既讲解了 API 的配置与调用,也实现了多场景的 AI 交互。该项目易于扩展,可根据自己的需求添加更多功能,是学习 AI API 调用和 GUI 开发的绝佳实践案例。手把手搭建 DeepSeek 多功能 AI 工作站:基于 Python Tkinter 的 GUI 实现在 AI 工具日益普及的今天,DeepSe
本文从 LLaMA 的核心设计出发,拆解并实现了一个轻量级的 LLaMA-like 模型,覆盖了 RMSNorm、SwiGLU、RoPE、因果自注意力等关键组件。大模型看似复杂,但本质是 “简单组件的有序组合”—— 掌握这些核心设计,就能理解大模型的底层逻辑,为后续的模型训练、优化和部署打下基础。训练模型:用小数据集(如 WikiText)训练模型,观察 Loss 的下降趋势;扩展参数:将调至 4
题目给出的油耗、电耗函数都是 U 型:太慢时,低速拥堵工况不省能太快时,空气阻力和高负荷也不省能真正省能的是某个中间速度区间项目还进一步做了载荷修正。设载重率为 λ,则:也就是说,燃油车满载比空载高 40%,新能源车高 35%。总成本:98378.44综合目标:99184.13总碳排放:10893.51 kg总延误:119.72 min准时率:97.98%使用车辆数:143未使用车辆数:42成本项
