




- @2501_92049521
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如何提升向量检索性能,实现300%的效率提升?本文通过某游戏公司的向量数据库应用实践及技术优化步骤详解,带大家了解向量数据库的检索性能调优

频繁更新的大模型正在将Agent能力推向新高度,但能力越强,失控风险越大。一个能自主调用工具、读写文件、消耗资源的Agent,如果缺乏透明度,本质上就是。
让 Agent 的记忆更智能,让 Token 的预算更健康。

你把"请保持简洁"改成"请极度简洁",Git只会显示一行diff,但Agent的输出长度可能从200 tokens骤降到50 tokens,这种影响在Git的历史里是看不见的。提交信息生成支持模板和LLM两种模式,后者在OpenClaw插件模式下会调用Gateway的模型,将原始diff转换成"移除了关于响应长度的限制,现在允许更详细的解释"这类可读摘要。,生成自然语言回答。目录维护独立的Git历

✅uv 解决的是项目环境可复现与流程收敛✅pyseekdb 解决 RAG 场景下的存储与检索落地成本与易用性💯把两者放在一起,是把 demo 交付与协作时的摩擦做小👇文内有完整步骤

本文将带你上手 seekdb MCP Server,并通过自然语言构建 AI 应用,来让大家体验 AI 原生数据库 seekdb 的魅力。
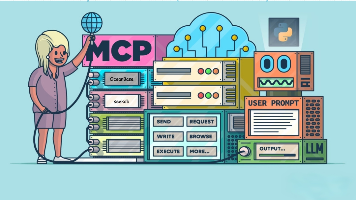
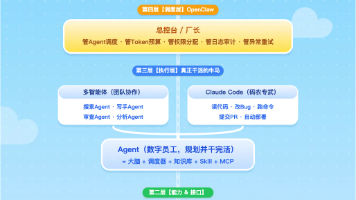
OpenClaw作为总调度台,负责拆解任务并协调多智能体团队(Multi-Agent)完成复杂任务。通过MCP协议实现AI与工具的标准化交互,借助向量数据库和RAG机制确保数据准确性。Agent=大脑+调度器+知识库+技能库,具备自主决策能力。Skill固化重复流程,Memory存储用户偏好。遇到复杂问题可调用Claude Code等专业Agent。最后通过Harness Engineering进
在使用 LangGraph 或自定义 AI Agent 时,持久化记忆是一个核心需求。但传统的记忆方案存在明显的效率问题。本文介绍如何 使用 seekdb-js SDK + Qwen3 Max (via OpenRouter) 为 Node.js AI Agent 实现高效的向量记忆系统 。

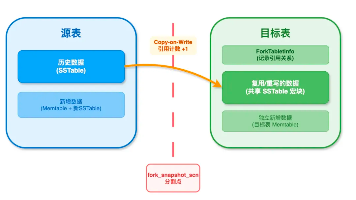
像 Git 管理代码一样管理数据:OceanBase seekdb 推出毫秒级 Fork Table 功能,让 AI 时代的数据实验与版本管理变得如同创建分支般轻量、隔离与高效。
谈及选择 OceanBase seekdb 的理由,Miley Fu 表示,OceanBase seekdb 的三大优势:无 CDC 延迟、原生 AI 支持与良好 SQL 兼容性,能实现向量、元数据与文本的原子更新,并易于与智能体集成,非常适合实时语音 AI 场景。在这一框架下,单一的 RAG 技术虽已难以应对复杂的交互场景,但可以演进为支持智能体(Agent)的统一上下文引擎,通过“检索前置+上
