




- @2401_84813926
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
你是不是也遇到过这种情况:每天重复处理同样的工作——把表格数据复制到数据库、发邮件通知、在几个平台之间同步信息。以前觉得写个脚本就能解决,结果发现:脚本维护成本高、扩展性差、出问题了还得手动排查。更别提那些复杂场景,比如要在不同 API 之间跳转、处理异常状态、记录日志,脚本很快就写成了维护噩梦。我之前也踩过这个坑,试过用 Python 写自动化脚本,结果每次加一个新功能就得改一堆代码。换个平台接

交互式确认技术栈版本、ORM 框架、鉴权方式等关键配置,提供最佳实践推荐,无需纠结版本兼容问题,一键确定项目基础规范。

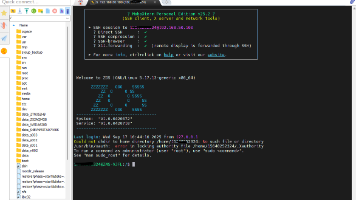
本文介绍了如何在极空间NAS设备上部署WebSSH服务,并通过cpolar实现内网穿透,实现随时随地通过浏览器访问SSH终端。
对于需要在多种设备和系统之间频繁切换的用户来说,这是最省心的选择。但需要注意的是,向日葵的部分高级功能(如高帧率、远程摄像头)在各平台的开放程度不一致,有些功能仅在Windows端可用。:Windows、macOS、Linux、iOS、Android和鸿蒙系统,所有平台的功能保持一致,不存在"某端功能阉割"的情况。我身边就有活生生的例子:一位运维同事的公司服务器全是Linux系统,他之前用的某款远

本文分享了如何利用飞算JavaAI快速搭建企业绩效管理平台的经验。作者针对传统Excel绩效考核流程中存在的版本混乱、数据孤岛等问题,通过AI智能引导在4小时内完成了覆盖目标制定、自评、上级评分、校准到调薪全流程的绩效管理系统开发。系统包含绩效工作台、OKR/KPI追踪、360评价、校准会议、薪资计算器等核心功能模块,实现了数据可视化与流程自动化。文章指出AI擅长工程脚手架搭建等基础工作,但业务规

对于需要在多种设备和系统之间频繁切换的用户来说,这是最省心的选择。但需要注意的是,向日葵的部分高级功能(如高帧率、远程摄像头)在各平台的开放程度不一致,有些功能仅在Windows端可用。:Windows、macOS、Linux、iOS、Android和鸿蒙系统,所有平台的功能保持一致,不存在"某端功能阉割"的情况。我身边就有活生生的例子:一位运维同事的公司服务器全是Linux系统,他之前用的某款远
Rust 是一门系统级编程语言,以其内存安全、并发性能和强大的类型系统而受到广泛关注。解构元组、结构体与枚举以及匹配守卫是 Rust 语言中非常有特色的特性,它们使得 Rust 代码在处理复杂数据结构和进行模式匹配时更加灵活和强大。

Rust 中的移动语义与复制语义-长详介绍

Rust 以其强大的内存安全性和高效的性能在系统编程领域崭露头角。异步编程在现代软件开发中变得越来越重要,Rust 提供了 async/await 这样的语法糖来简化异步代码的编写。而 Pin 和 Unpin 则是保障异步编程中内存安全的关键概念。理解它们对于编写正确、高效的 Rust 异步程序至关重要。

有人称这是“AI史上最贵的实习生失误”,也有人欢呼“这是送给开发者的圣诞礼物”。无论如何,2026年3月31日注定载入AI史册在AI Agent时代,代码即战略,细节定生死。而Anthropic,正为自己的傲慢与疏忽付出代价。真正的壁垒,究竟是代码,还是快速迭代与用户信任?🔥 转发提醒你的CTO:检查你们的npm包,别让下一个“裸奔”的是你!
