




- @2301_80100415
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
第一,分层架构是系统复杂度的解药。驱动、感知、决策、建图各层通过ROS 2的通信机制解耦,每一层都可以独立调试和替换。没有这种分层设计,面对数百行代码和多节点协同,调试将是一场噩梦。第二,工程化的核心是“容错”而非“完美”。看门狗超时停止、语音播报多级降级、障碍物检测的动态/静态分类——这些都不是最“炫酷”的技术,但它们保证了系统在真实环境中不会因为一个节点的异常而整体崩溃。第三,传感器融合要做“
摘要:人形机器人开发的核心痛点是开放场景下的感知失准和执行失效问题。具身智能技术通过融合感知、模拟和执行的一体化机制,实现了机器人从预编程到自主进化的转变。该技术强调大脑、身体与环境的交互,采用多模态感知、强化学习和增量学习等方法,使机器人具备场景适应和持续进化能力。当前,特斯拉Optimus、优必选Walker等产品已实现初步落地,但开放场景的鲁棒性和成本问题仍是主要挑战。未来发展方向包括虚实融
如果说前两张图展示了AST的“术”与“用”,那么下面这张全景图谱则揭示了支撑这一切的“道”与“器”。左侧:传统模型(GMM-HMM、CNN、RNN)各自在噪声、混响、多源叠加、算力受限四大挑战前败下阵来。中部:AST凭借全局感受野、并行计算、SOTA性能,正面碾压传统方案。右侧:音频经梅尔谱图→分块嵌入→位置编码→Transformer编码器→分类输出,形成一个可迭代的推理流水线。下方闭环:数据反
《基于OpenAI Codex的运维自动化脚本批量生成实践》 摘要:运维与DevOps工程师日常需要大量编写Shell/Python脚本,传统开发方式存在效率低、易出错等问题。OpenAI Codex通过自然语言描述直接生成代码的能力,为运维自动化提供了新思路。本文介绍了Codex在运维脚本批量生成中的具体应用方法,包括单脚本生成、批量模式、CI/CD集成等实践方案,重点阐述了优化生成质量的Pro
WiFi传感新突破:RuView实现无接触人体监测 RuView是一款基于WiFi信号的开源空间传感平台,无需摄像头或穿戴设备,仅通过普通路由器信号即可穿透墙壁,实现人体位置追踪、呼吸心跳监测等功能。其核心原理是分析WiFi信号因人体活动产生的散射变化,通过AI算法还原动作与生命体征。 优势包括: 隐私安全:不采集图像,数据本地处理; 低成本:ESP32开发板仅需几十元; 强适应性:全黑、穿墙、烟
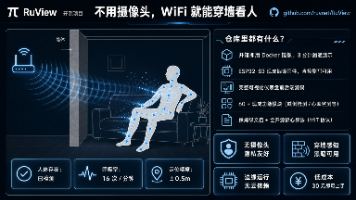
WiFi传感新突破:RuView实现无接触人体监测 RuView是一款基于WiFi信号的开源空间传感平台,无需摄像头或穿戴设备,仅通过普通路由器信号即可穿透墙壁,实现人体位置追踪、呼吸心跳监测等功能。其核心原理是分析WiFi信号因人体活动产生的散射变化,通过AI算法还原动作与生命体征。 优势包括: 隐私安全:不采集图像,数据本地处理; 低成本:ESP32开发板仅需几十元; 强适应性:全黑、穿墙、烟
本文探讨了从仿真训练到实机部署的关键挑战与解决方案,重点介绍了ONNX作为标准化交付载体的核心作用。文章指出,Sim2Sim是Sim2Real的必要准入门槛,能提前解决80%的实机问题。通过分析工业级落地经验,作者详细阐述了完整交付清单(包括ONNX模型、配置文件等)和渐进式实机测试流程(从模型校验到全场景验证)。特别强调了对齐输入输出规范、避免常见踩坑点(如维度不匹配、数据类型错误等)的重要性,
Sim2Real 的成功 =高保真仿真×合理的域随机化×可靠的模型导出与部署链路×安全包装。它是一个需要多次迭代的工程实践,但一旦走通,将极大缩短机器人算法的迭代周期。“迁移到 real”不是把模型拷贝过去,而是把仿真里的“观测→动作”闭环,用真机的传感器、计算芯片和执行器精确复现,同时兜住所有现实物理边界。
与传统签名匹配不同,ExploitAgent采用“上下文理解+Payload动态生成”的双驱动模式——LLM分析注入点的语义上下文(参数名称、业务含义、前后端错误响应模式),自适应生成绕过Payload,大幅提升对定制化防护机制的突破能力。系统深度支持与Burp Suite、Nuclei、Metasploit、xray等主流工具的集成——既可作为上层调度引擎调用这些工具的能力,也可将其发现的结果作
摘要:NVIDIA Isaac Lab是一个基于GPU加速的开源机器人仿真与研究框架,旨在解决传统仿真工具在精度和效率上的瓶颈问题。该框架整合了高精度物理仿真、传感器模拟和强化学习生态,支持多种机器人模型和复杂场景的快速仿真。通过GPU批处理技术,Isaac Lab能实现数千个并行环境的同步运算,显著提升算法训练效率。其模块化设计和跨平台支持降低了研究门槛,同时双许可证模式兼顾学术与工业需求。该框