




- @2301_77509762
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
政务服务很适合接入 Agent:群众问材料、问流程、问窗口,系统可以调用知识库快速回答。但如果答案只以文字形式出现,放到大厅现场就会变得很生硬。很多群众不愿读长段说明,也很难在排队、嘈杂、赶时间的环境里完成多轮输入。传统云端数字人尝试补上形象,但依托视频流预渲染,整体交互延迟偏高。群众中途插话、临时变更咨询问题时,系统往往无法即时打断;硬件、带宽和部署成本也让基层网点很难批量铺开。在这个项目里,我
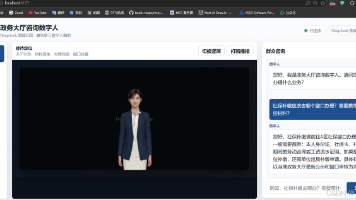
政务服务很适合接入 Agent:群众问材料、问流程、问窗口,系统可以调用知识库快速回答。但如果答案只以文字形式出现,放到大厅现场就会变得很生硬。很多群众不愿读长段说明,也很难在排队、嘈杂、赶时间的环境里完成多轮输入。传统云端数字人尝试补上形象,但依托视频流预渲染,整体交互延迟偏高。群众中途插话、临时变更咨询问题时,系统往往无法即时打断;硬件、带宽和部署成本也让基层网点很难批量铺开。在这个项目里,我
2026年2月13日,百灵大模型正式发布并开源了首个混合线性架构的万亿参数思考模型Ring-2.5-1T。这款模型不仅在IMO 2025数学竞赛中斩获金牌水平,在CMO 2025中更是取得105分的优异成绩,远超金牌线78分。作为一名技术爱好者,我第一时间体验了搭载Ring-2.5-1T的Ling Studio平台,这篇文章将手把手带你领略它的强大能力。访问 https://ling.tbox.c
本文介绍了一款基于ESP32-S3主控和CSNP1GCR01-AOW存储芯片的智能小型夜灯方案。该夜灯采用高效LED光源和智能感应技术,支持远程控制、自动调光等功能。存储方案选用微型化设计的SD NAND芯片,具有1Gbit容量、6*8mm超小封装,内置四大管理算法保障数据安全。实测显示其读取速度超20MB/s,写入速度4.6MB/s,满足灯光模式存储需求。整体方案兼顾性能与体积,实现了稳定可靠、

CANN(Compute Architecture for Neural Networks)作为华为面向人工智能场景打造的端云一致异构计算架构,已成为国产化AI基础设施的关键软件支撑。其核心优势在于通过统一编程接口、高效算子库和智能调度系统,实现了从底层硬件到上层应用的全栈协同优化,为开发者提供了简单易用却又性能强大的AI开发环境。

CANN(Compute Architecture for Neural Networks)是华为面向人工智能场景打造的端云一致异构计算架构,其核心价值在于通过统一编程接口、高效算子库和智能调度系统,为AI基础设施提供关键的软件支撑。CANN以极致性能优化为核心,旨在释放硬件潜能、简化AI开发流程。对于一些特殊的计算需求,CANN提供了自定义算子开发能力,允许开发者根据自己的需求开发专用的高性能算
import tbe# 定义3D卷积算子计算逻辑# 1. 获取输入和权重的形状信息# 2. 检查输入参数合法性if groups!= 1:# 3. 计算输出形状# 考虑padding和stride计算输出维度# 4. 实现优化的3D卷积计算# 使用TVM的计算表达式描述3D卷积# 针对昇腾AI处理器的特性进行优化# 4.1 输入数据填充else:# 4.2 执行3D卷积计算# 使用滑动窗口和矩阵乘
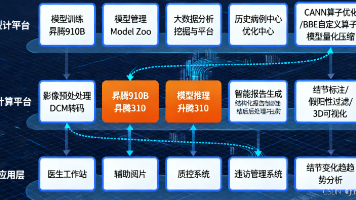
本文介绍了基于vLLM-ascend框架在昇腾NPU上快速部署DeepSeek-V2-Lite模型的全流程。vLLM-ascend作为专为昇腾NPU优化的高性能推理框架,支持MoE架构模型的0Day部署,显著降低混合专家模型的部署门槛。文章详细展示了从GitCode Notebook环境配置、vLLM-ascend安装到模型下载和推理部署的核心步骤,并验证了昇腾NPU在7B参数模型上的高效推理能力

本文介绍了基于vLLM-ascend框架在昇腾NPU上快速部署DeepSeek-V2-Lite模型的全流程。vLLM-ascend作为专为昇腾NPU优化的高性能推理框架,支持MoE架构模型的0Day部署,显著降低混合专家模型的部署门槛。文章详细展示了从GitCode Notebook环境配置、vLLM-ascend安装到模型下载和推理部署的核心步骤,并验证了昇腾NPU在7B参数模型上的高效推理能力
