




- @2201_75499313
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
使用ollama create命令创建自定义模型。

参考: https://help.aliyun.com/zh/egs/user-guide/install-a-gpu-driver-on-a-gpu-accelerated-compute-optimized-linux-instance。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。1)3090显卡的即可(如果本地有GPU机器,请用自己的),选择了

而o1在每个问题上使用一个样本平均解决了74%(11.1/15)的问题,使用64个样本的共识解决了83%(12.5/15)的问题,并使用学习到的评分函数对1000个样本进行重新排序后解决了93%(13.9/15)的问题。在其他一些机器学习基准测试中,o1也超过了最先进的模型。OpenAI 从GPT3开始转向闭源,很多技术细节都没有公布,OpenAI o1这次也不例外,网上很多人反馈想通过使用o1一

从避免AI幻觉的小窍门,到设计出色提示语的秘籍,每一页都凝聚着干货知识,让用户能够直接上手操作,快速掌握DeepSeek的精髓。这份文档不仅为用户提供了关于DeepSeek的全面知识,还体现了中国科技在人工智能领域的快速发展。《DeepSeek:从入门到精通》以通俗易懂的方式,全面介绍了DeepSeek的使用方法,为用户提供了极具价值的指导。这份文档内容丰富,篇幅长达104页,涵盖了众多实用技巧。

稀疏 MoE 层:取代传统 Transformer 的前馈网络(FFN)层。MoE 层由多个“专家”(如 8 个)组成,每个专家是一个独立的神经网络,通常是 FFN,也可以是更复杂的结构,甚至是嵌套的 MoE 形成层级式结构。门控网络或路由:决定哪些 Token 由哪个专家处理。例如,“More”可能被分配给第二个专家,而“Parameters”可能被分配给第一个。有时,一个 Token 甚至可以
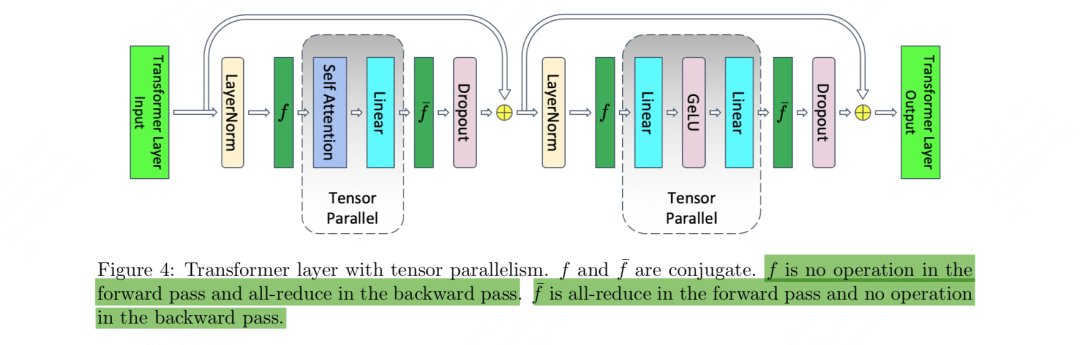
不做任何并行处理时,单卡上attn+mlp层的激活值大小假设有t块卡,纯tp处理时,单卡上attn+mlp层的激活值大小,这里唯一没有被t除的10表示attn和mlp中和layernorm输入、输出以及最后一个dropout mask相关的部分。这一部分也是sp关注的优化点。假设有t块卡,做tp+sp处理时,单卡上attn+mlp层的激活值大小为。
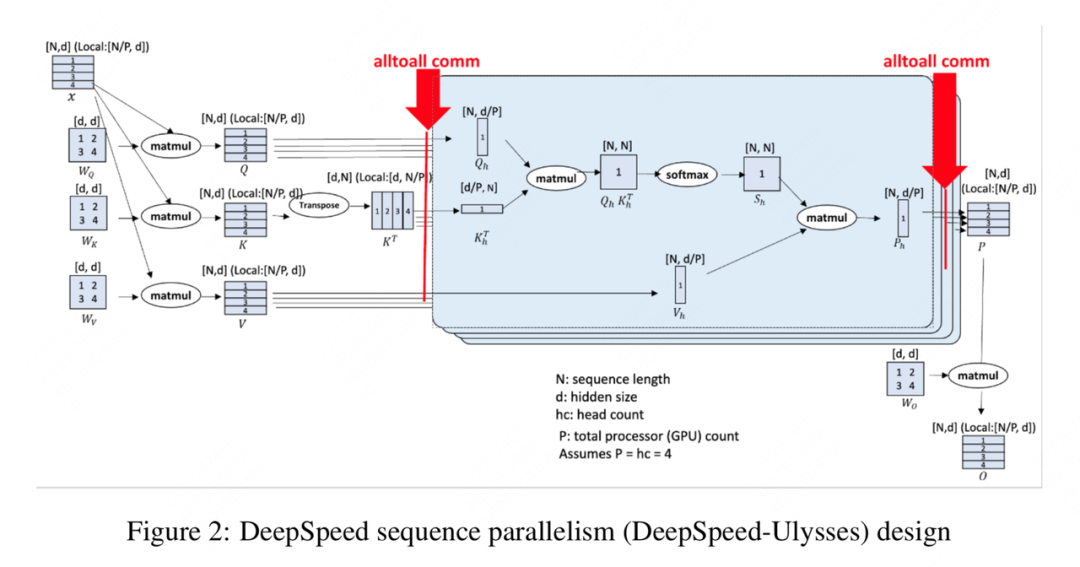
最近已有不少大厂都在秋招宣讲,也有一些已在 Offer 发放阶段了。节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。大家好,在序列并行系列中,我们已经介绍过了Megatron SP,今天这篇文章我们来看DeepSpeed Ulysses。在正文开始前,。所以虽然
不做任何并行处理时,单卡上attn+mlp层的激活值大小假设有t块卡,纯tp处理时,单卡上attn+mlp层的激活值大小,这里唯一没有被t除的10表示attn和mlp中和layernorm输入、输出以及最后一个dropout mask相关的部分。这一部分也是sp关注的优化点。假设有t块卡,做tp+sp处理时,单卡上attn+mlp层的激活值大小为。
而o1在每个问题上使用一个样本平均解决了74%(11.1/15)的问题,使用64个样本的共识解决了83%(12.5/15)的问题,并使用学习到的评分函数对1000个样本进行重新排序后解决了93%(13.9/15)的问题。在其他一些机器学习基准测试中,o1也超过了最先进的模型。OpenAI 从GPT3开始转向闭源,很多技术细节都没有公布,OpenAI o1这次也不例外,网上很多人反馈想通过使用o1一
最近春招和实习已开启了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。本文从零实现,基于Ollama、FastGPT、Deepseek在本地环境中打造属于自己的专业知识库,与大家分享~
