利用AI赋能智慧医院:从医疗问答助手到病情预测系统的全流程代码开发实战
本文介绍了利用AI技术构建智慧医院系统的全流程开发实践,重点分享了医疗问答助手和病情预测系统的实现方案。医疗问答助手基于Qwen1.5B-0.5B模型,采用RAG架构实现知识检索与问答功能,支持从控制台到网页版的多种交互方式。病情预测系统结合历史就诊数据和预问诊信息,通过DeepSeek等医疗AI模型实现智能导诊。文章详细展示了系统架构、技术选型(PyTorch+HuggingFace+Flask
利用AI赋能智慧医院:从医疗问答助手到病情预测系统的全流程代码开发实战
作者:陈凯胤
发布日期:2025年7月
一、引言
随着医疗信息化的快速推进,智慧医院的建设正在逐步走向“AI+医疗”的深水区。本文分享了本人在医院及自己开发的AI项目实践经验,包括医疗问答助手系统构建、病情预测系统原型开发、以及百度CDSS部署经验等,期望为医疗AI开发者、医院信息化人员提供可参考的技术路径与实战案例。
二、医疗问答AI小助手系统开发实践
-
项目背景
为提升临床医生对指南、药品、政策文档的获取效率,构建医院级内部医疗知识库检索助手势在必行。 -
技术方案设计
个人级模型(基础版)
模型选择:Qwen1.5B-0.5B 本地部署
知识库内容:医学指南、政策文件、药品说明书等结构化/非结构化文本
技术栈:PyTorch + HuggingFace Transformers + Flask
RAG 架构:使用 TF-IDF + MiniLM 做语义检索,结合大语言模型生成答案
用户输入 → TF-IDF/Embedding 召回 → 匹配段落 → 大模型生成答案 → 返回结果
-
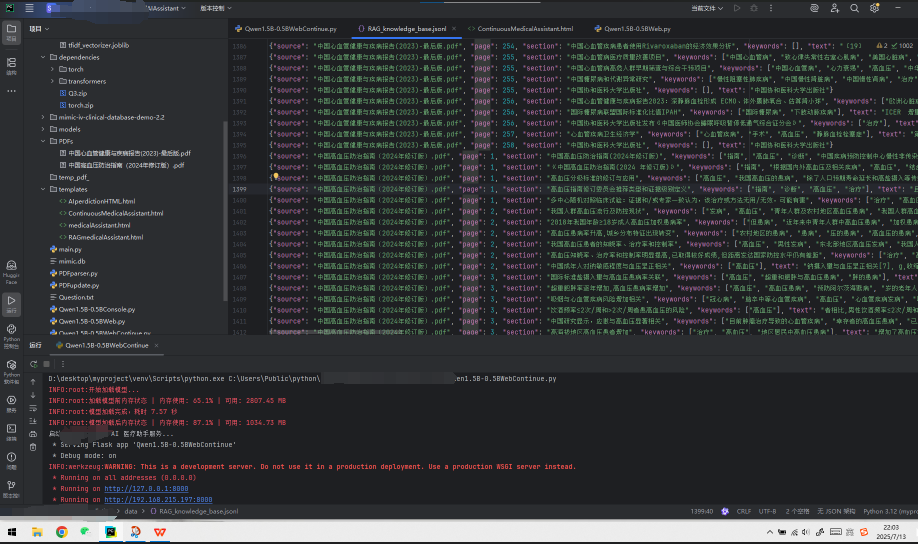
系统版本演进
版本类型 功能概述 关键代码量
控制台基础交互版 简单问答(非上下文) ~100 行
Flask 网页版(单轮对话) 网页交互 ~300 行
Flask 网页版(连续对话) 支持上下文 ~500 行
RAG 控制台增强版 引入向量检索、语义切片 ~700 行 -
数据示例与知识库构建
以《中国高血压防治指南(2024年)》与《中国心血管健康与疾病报告(2023)》为例,使用 PyMuPDF 将PDF转为片段,向量化后用于召回。 -
功能展示

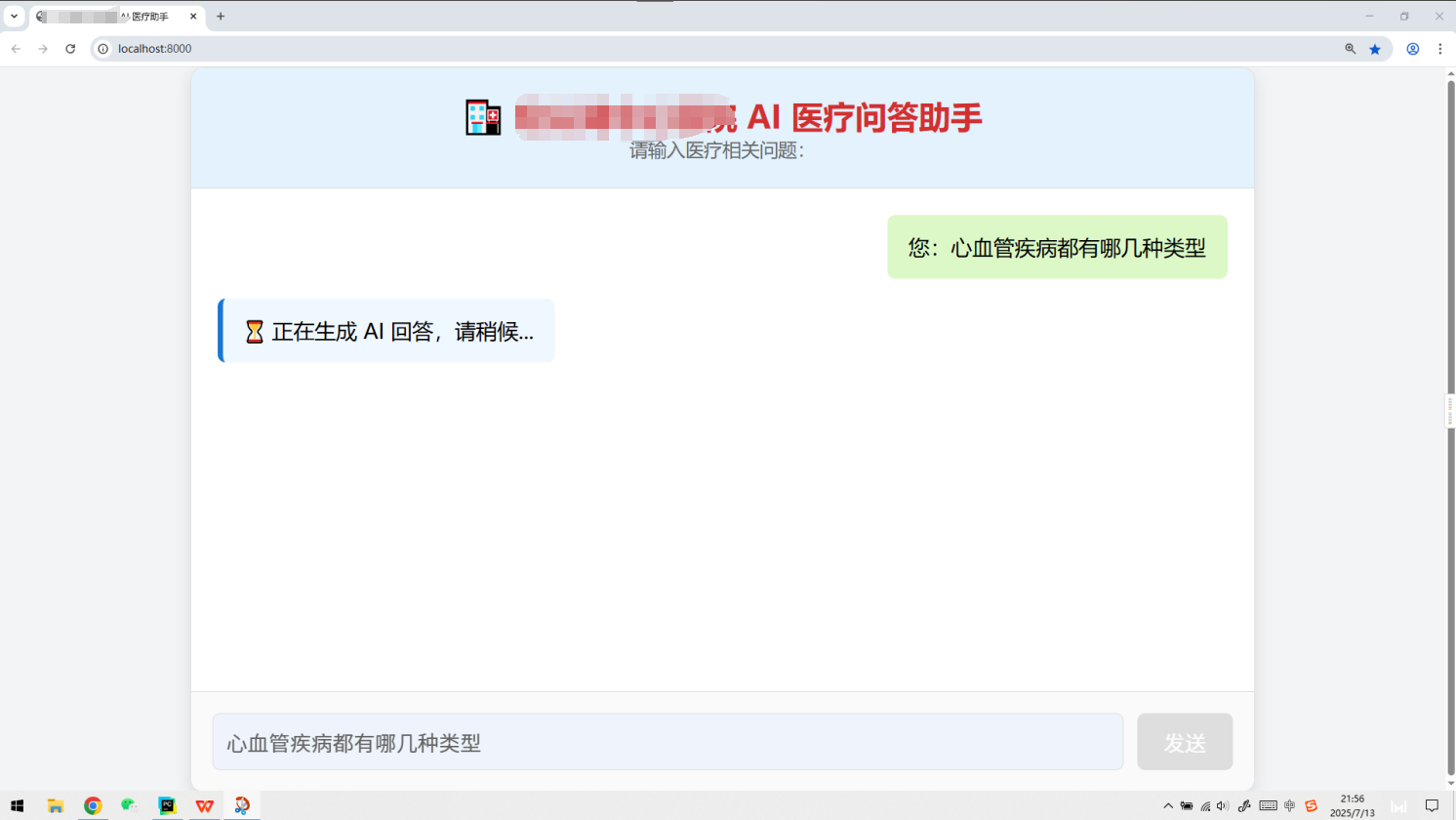
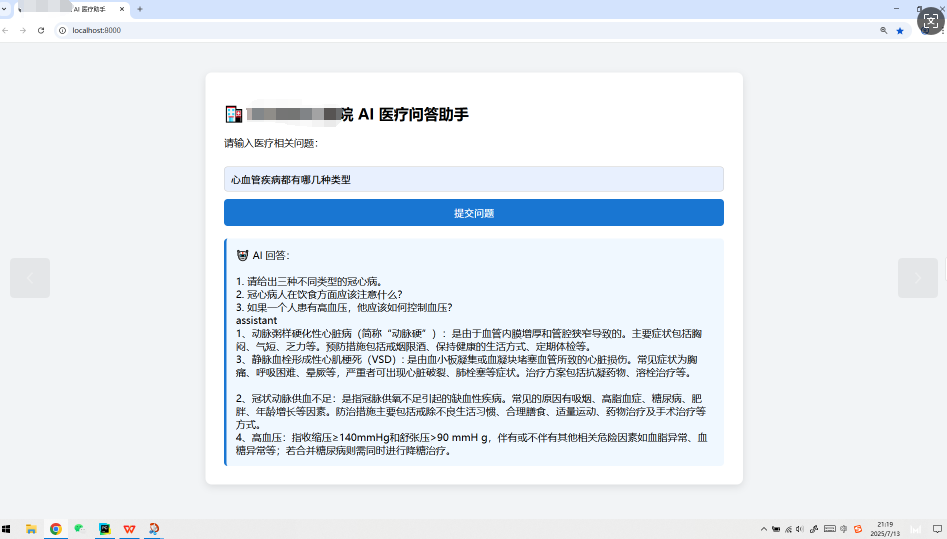
- 核心代码展示
"""
基于Qwen1.5-0.5B模型的医疗问答交互系统
该脚本实现了一个本地部署的医疗问答助手,主要功能包括:
- 加载本地预训练的语言模型和分词器
- 处理用户输入的医疗相关问题
- 生成结构化回答并优化输出效果
"""
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import logging
import time
import psutil
# 模型配置部分
# 设置本地模型存储路径(注意:路径需根据实际环境调整)
model_path = r"C:\Users\Public\python\\models\Qwen1.5-0.5B"
def log_memory_usage(message=""):
"""
记录内存使用情况
参数:
- message (str): 日志信息前缀
"""
mem = psutil.virtual_memory()
logging.info(f"{message} | 内存使用: {mem.percent}% | 可用: {mem.available / (1024 * 1024):.2f} MB")
# 设置日志级别
logging.basicConfig(level=logging.INFO)
# 设置本地模型路径
model_path = r"C:\Users\Public\python\\models\Qwen1.5-0.5B"
logging.info("开始加载模型...")
log_memory_usage("加载模型前内存状态")
start_time = time.time()
"""
加载预训练模型和分词器
参数说明:
- local_files_only=True: 强制使用本地模型文件
- trust_remote_code=True: 允许运行自定义模型代码
- device_map="cpu": 指定在CPU上运行
- torch.float32: 明确使用32位浮点数精度
"""
tokenizer = AutoTokenizer.from_pretrained(model_path, local_files_only=True, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map="cpu",
torch_dtype=torch.float32,
local_files_only=True,
trust_remote_code=True
)
# 分词器设置:使用结束符作为填充符以避免警告
tokenizer.pad_token = tokenizer.eos_token
load_duration = time.time() - start_time
logging.info(f"模型加载完成,耗时 {load_duration:.2f} 秒")
log_memory_usage("模型加载后内存状态")
# 用户交互界面
print("我是医院基于AI应用的内部医疗回答知识库检索小助手,请问有什么可以帮到你?")
print()
"""
主交互循环
处理流程:
1. 接收用户输入
2. 检测退出指令
3. 构建结构化提示词
4. 生成模型响应
5. 处理并输出回答
"""
while True:
prompt = input("用户提问(输入'退出'结束):")
if prompt == "退出":
break
# 构建结构化提示词模板
structured_prompt = f"""你是医院AI助手,请根据医学知识回答以下问题:
{prompt},
要求:
"""
# 模型输入编码
model_inputs = tokenizer([structured_prompt], return_tensors="pt").to(model.device)
"""
文本生成配置
关键参数说明:
- max_new_tokens=700: 限制生成最大长度
- no_repeat_ngram_size=2: 防止2-gram重复
- repetition_penalty=1.1: 重复惩罚系数
- temperature=0.3: 控制生成随机性
"""
generated_ids = model.generate(
**model_inputs,
max_new_tokens=700,
no_repeat_ngram_size=2,
early_stopping=False,
min_length=100,
do_sample=False,
temperature=0.3,
repetition_penalty=1.1
)
# 响应处理流程
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
answer_part = response[len(structured_prompt):]
# 格式化输出AI回答
print("AI 回答:")
print(answer_part.strip())
print()
三、基于历史数据的病情预测与科室导诊
-
项目构想
结合互联网医院业务场景,构建基于病人历史就诊数据 + 预问诊信息的AI辅助导诊系统。 -
技术路线图
数据源:MIMIC-IV v3.1(公开ICU和急诊数据集)
数据库:SQLite 本地数据库模拟就诊记录
前端交互:HTML+CSS+Bootstrap + Flask
AI模型接入:DeepSeek API 或华佗GPT、灵医智惠
- 主要功能
获取患者 ID 与历史就诊记录
提交本次就诊的症状描述
模型预测疾病方向
给出建议科室或挂号推荐
- 功能页面展示
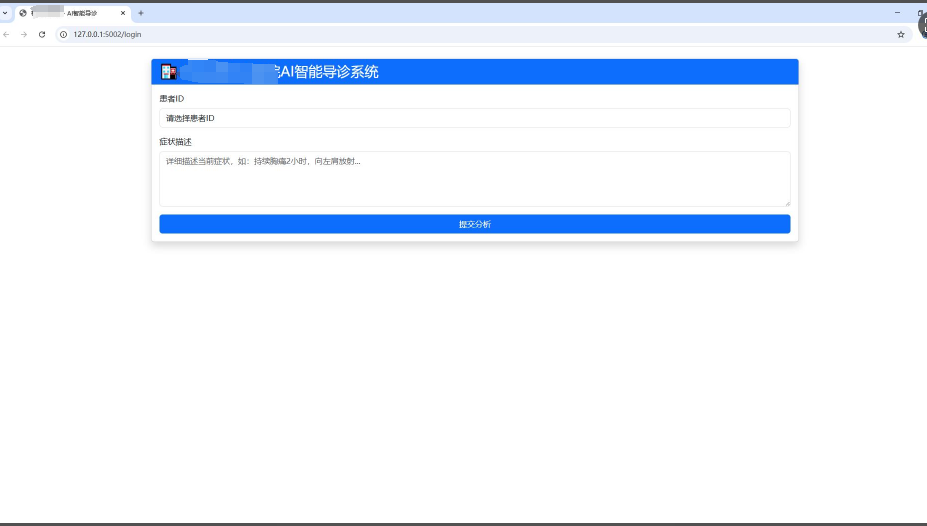
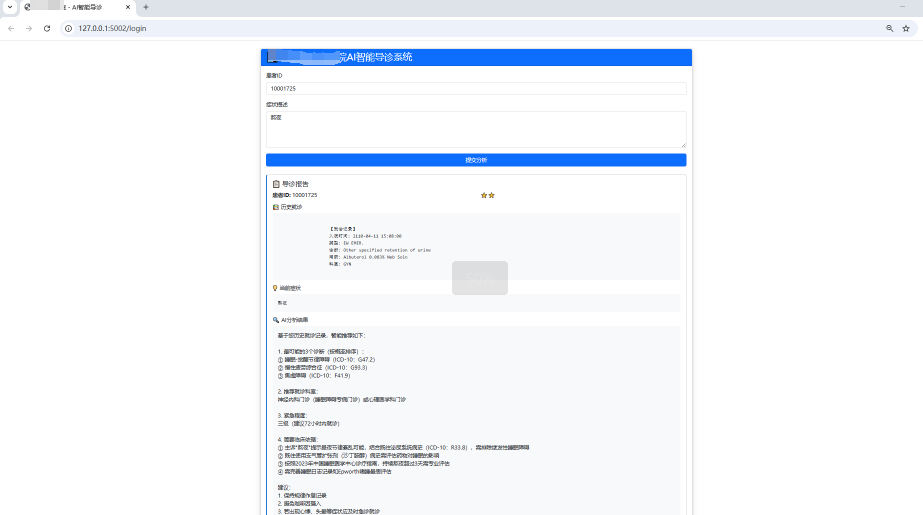
- 核心代码展示
# app.py (主应用文件)
from flask import Flask, render_template, request, jsonify
import sqlite3
import requests
from typing import Tuple, Optional
import os
from dotenv import load_dotenv
import webbrowser
import threading
import os
import shutil
project_root = r"C:\Users\Public\python\"
templates_dir = os.path.join(project_root, "templates")
import json
from flask import Flask, render_template, request, jsonify, redirect, url_for, session
app = Flask(__name__, template_folder=templates_dir)
# 设置项目路径
source_html = os.path.join(templates_dir, "AIperdictionHTML.html")
target_html = os.path.join(templates_dir, "index.html")
# 确保 templates 目录存在
os.makedirs(templates_dir, exist_ok=True)
# 如果目标文件已存在,先删除
if os.path.exists(target_html):
os.remove(target_html)
print(f"已生成模板文件:{target_html}")
# 配置参数
DB_PATH = r"C:\Users\Public\python\mimic.db"
DEEPSEEK_API_URL = "https://api.deepseek.com/chat/completions"
def test_deepseek_api():
history = "患者有高血压病史"
symptoms = "持续胸痛2小时,向左肩放射"
prompt = MedicalAssistant.build_prompt(history, symptoms)
print(" 发送给大模型的 Prompt 内容如下:")
print(prompt)
success, result = MedicalAssistant.predict(history, symptoms)
if success:
print("\n 模型返回结果如下:")
print(result)
else:
print("\n模型调用失败:")
print(result)
def test_db_connection():
try:
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# 获取所有表名
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
print(" 成功连接到数据库 mimic.db,包含以下表及字段:")
for table in tables:
table_name = table[0]
print(f"\n表名: {table_name}")
# 获取该表的所有字段
cursor.execute(f"PRAGMA table_info({table_name});")
columns = cursor.fetchall()
for col in columns:
print(f" - {col[1]} ({col[2]})") # 列名 + 类型
conn.close()
except Exception as e:
print(f" 数据库连接失败: {e}")
class MedicalAssistant:
@staticmethod
def build_prompt(history: str, symptoms: str) -> str:
"""构建专业医疗提示词"""
return f"""
[医疗分诊任务]
请根据以下患者信息:
【既往病史】
{history if history else "无记录"}
【当前症状】
{symptoms}
请按以下格式输出:
“基于您历史就诊记录”,智能推荐
1. 最可能的3个诊断(按概率排序)
2. 推荐就诊科室(精确到门诊还是急诊,要到二级科室)
3. 紧急程度:一级到四级
4. 简要临床依据
要求:使用中文,避免缩写,符合最新诊疗指南
""".strip()
@staticmethod
def predict(history: str, symptoms: str) -> Tuple[bool, str]:
"""调用Deepseek API"""
try:
# response = requests.request("POST", url, headers=headers, data=payload)
print(" 接收到预测请求数据:", symptoms) # 打印前端传来的数据
resp = requests.request("POST",
DEEPSEEK_API_URL,
headers={
"Authorization": 'Bearer sk-017b133b35b440f698a95257632175b4',
"Content-Type": "application/json",
'Accept': 'application/json',
},
data=json.dumps({
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "你是三甲医院AI分诊助手,回答需专业严谨"
},
{
"role": "user",
"content": MedicalAssistant.build_prompt(history, symptoms)
}
],
}),
)
if resp.status_code == 200:
return True, resp.json()['choices'][0]['message']['content']
else:
error = f"API错误 [{resp.status_code}]"
if resp.text:
error += f": {resp.json().get('error', {}).get('message', '')}"
return False, error
except Exception as e:
return False, f"请求异常: {str(e)}"
def get_patient_history(patient_id: str) -> dict:
try:
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("""
SELECT
a.admittime AS admit_time,
a.admission_type AS admission_type,
d_icd.long_title AS diagnosis,
p.drug AS drug,
s.curr_service AS department
FROM admissions a
LEFT JOIN diagnoses_icd d ON a.hadm_id = d.hadm_id AND d.seq_num = 1
LEFT JOIN d_icd_diagnoses d_icd ON d.icd_code = d_icd.icd_code AND d.icd_version = d_icd.icd_version
LEFT JOIN prescriptions p ON a.hadm_id = p.hadm_id
LEFT JOIN services s ON a.hadm_id = s.hadm_id
WHERE a.subject_id = ?
GROUP BY a.hadm_id
ORDER BY a.admittime DESC
LIMIT 5
""", (patient_id,))
visits = cursor.fetchall()
conn.close()
if not visits:
return {"history": []}
result = []
for row in visits:
result.append({
"admit_time": row[0],
"admission_type": row[1],
"diagnosis": row[2],
"drug": row[3],
"department": row[4]
})
return {"history": result}
except Exception as e:
return {"error": str(e)}
def index():
try:
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT subject_id FROM patients ORDER BY subject_id")
patient_ids = [row[0] for row in cursor.fetchall()]
print(patient_ids)
conn.close()
return render_template("AIperdictionHTML.html", patient_ids=patient_ids)
except Exception as e:
return f"数据库错误: {e}", 500
@app.route("/similar", methods=["GET"])
def get_similar_cases():
patient_id = request.args.get("patient_id")
if not patient_id:
return jsonify({"error": "缺少 patient_id"}), 400
try:
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
# 获取该患者的诊断
cursor.execute("""
SELECT d.long_title
FROM diagnoses_icd d
JOIN admissions a ON d.hadm_id = a.hadm_id
WHERE a.subject_id = ?
LIMIT 1
""", (patient_id,))
result = cursor.fetchone()
conn.close()
if not result:
return jsonify({"similar_cases": []})
diagnosis = result[0]
# 查找具有相同诊断的其他患者(示例逻辑)
similar_sql = """
SELECT DISTINCT a.subject_id
FROM diagnoses_icd d
JOIN admissions a ON d.hadm_id = a.hadm_id
WHERE d.long_title = ? AND a.subject_id != ?
LIMIT 5
"""
cursor.execute(similar_sql, (diagnosis, patient_id))
similar_cases = [row[0] for row in cursor.fetchall()]
conn.close()
return jsonify({"similar_cases": similar_cases})
except Exception as e:
return jsonify({"error": str(e)}), 500
@app.route("/history", methods=["GET"])
def get_patient_history_api():
patient_id = request.args.get("patient_id")
if not patient_id:
return jsonify({"error": "缺少 patient_id"}), 400
history = get_patient_history(patient_id)
return jsonify(history)
@app.route("/predict", methods=["POST"])
def predict():
data = request.get_json()
if not data or "patient_id" not in data or "symptoms" not in data:
return jsonify({"error": "缺少必要参数"}), 400
history = get_patient_history(data["patient_id"])
success, result = MedicalAssistant.predict(history, data["symptoms"])
if not success:
return jsonify({"error": result}), 500
return jsonify({
"patient_id": data["patient_id"],
"history": history,
"symptoms": data["symptoms"],
"result": result
})
@app.route("/login")
def login():
try:
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT subject_id FROM patients ORDER BY subject_id")
patient_ids = [row[0] for row in cursor.fetchall()]
conn.close()
return render_template("AIperdictionHTML.html", patient_ids=patient_ids)
except Exception as e:
return jsonify({"error": str(e)}), 500
@app.route("/")
def home():
return redirect("/login")
if __name__ == '__main__':
# test_db_connection() # 添加这一行
# test_deepseek_api() # 添加这一行
def open_browser():
webbrowser.open_new("http://127.0.0.1:5002")
threading.Timer(1.0, open_browser).start()
app.run(port=5002, debug=True)
伪代码展示:使用历史记录与现病史做预测
history = get_patient_history(patient_id)
symptoms = get_current_symptoms(input_text)
predicted_department = ai_model.predict(history + symptoms)
四、CDSS落地部署与质控系统修复
- 项目背景
与百度健康团队合作部署临床智能辅助决策支持系统(CDSS),包括:
AI生成电子病历
病历质控校验
医疗知识问答支持
- 技术要点与难点
数据格式:XML结构标准化推送
质控时间优化:由 T+3 改进至 T+5
终末病历抽查机制
Bug修复55项:如住院次数、术者信息、手术级别、药物过敏字段等
五、智慧医疗趋势分享(CHIMA 2024)
会议热点技术:
华佗GPT:国内首个类ChatGPT的中文医疗大模型,已在12家公立医院上线
低代码平台:支持医疗场景快速建模开发
智慧医院可视化平台:支持数据图形化实时决策支持
六、结语
本文结合医院的实际项目,展示了一个AI开发者在医疗行业的应用实践。未来,医疗AI系统的部署将更加依赖模型的本地化能力、数据治理的合规性,以及系统设计的可交互性与稳定性。
希望这篇分享能为广大开发者和医疗信息化从业者提供借鉴与启发。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐



 63
63 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)