MySQL 核心特性深挖:ACID、隔离级别、索引与视图的底层原理
引言
上一篇 MySQL 进阶文章涵盖了事务、隔离级别、索引和视图的基本概念。但很多同学反馈"太过于片面,根本没法学习"。本文将对这四个主题进行彻底深挖——从底层实现原理到具体操作细节,从面试考点到生产环境最佳实践,真正把这四个核心特性讲透。
本文假设你已经了解 MySQL 的基本 CRUD 操作,目标是从"会用"进阶到"理解原理"。
第一部分:ACID 深度拆解
一、原子性(Atomicity)的底层实现
1.1 原子性的真正含义
原子性不是说事务"一瞬间执行完",而是说事务是一个不可分割的工作单元。如果事务包含 10 条 SQL,那么要么 10 条全部生效,要么全部不生效——不存在"生效了 5 条"的中间状态。

1.2 Undo Log 工作流程
Undo Log 是 InnoDB 实现原子性的核心机制。每当事务修改数据时,InnoDB 会先将修改前的旧值写入 Undo Log。

1.3 Undo Log 的存储位置
Undo Log 存储在共享表空间(ibdata1)或独立 Undo 表空间(MySQL 8.0 默认)中。它是一个环形结构,旧记录会被新记录覆盖。
1.4 面试常见追问
Q:事务执行到一半断电了,恢复后数据是什么状态?
A:MySQL 重启时会进行崩溃恢复。检查 Redo Log 来恢复已提交事务的修改,检查 Undo Log 来回滚未提交事务的修改。最终数据会恢复到所有已提交事务完成、所有未提交事务回滚的状态。
Q:ROLLBACK 能不能只回滚部分操作?
A:可以使用保存点(SAVEPOINT):
BEGIN;
INSERT INTO t VALUES (1);
SAVEPOINT sp1;
INSERT INTO t VALUES (2);
SAVEPOINT sp2;
INSERT INTO t VALUES (3);
-- 回滚到 sp2,只撤销第3条 INSERT
ROLLBACK TO sp2;
COMMIT;
-- 最终结果:插入了 1 和 2,3 被撤销二、一致性(Consistency)的底层实现
2.1 一致性由谁保证
一致性不是由单一机制保证的,而是由数据库约束 + ACID 的其他三个特性共同保证:

2.2 约束违反示例
-- 创建带约束的表
CREATE TABLE student (
id INT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
age INT CHECK (age >= 0 AND age <= 150),
email VARCHAR(50) UNIQUE
);
-- 违反 NOT NULL → 失败
INSERT INTO student VALUES (1, NULL, 20, 'test@test.com');
-- 违反 CHECK → 失败
INSERT INTO student VALUES (1, '张三', 200, 'test@test.com');
-- 违反 UNIQUE → 失败
INSERT INTO student VALUES (2, '李四', 20, 'test@test.com');
-- 全部合法 → 成功
INSERT INTO student VALUES (1, '张三', 20, 'zhang@test.com');
INSERT INTO student VALUES (2, '李四', 22, 'li@test.com');2.3 外键约束详解
-- 创建班级表
CREATE TABLE class (
id INT PRIMARY KEY,
class_name VARCHAR(20)
);
-- 创建学生表(带外键)
CREATE TABLE student (
id INT PRIMARY KEY,
name VARCHAR(20),
class_id INT,
FOREIGN KEY (class_id) REFERENCES class(id)
ON DELETE SET NULL -- 班级删除时,学生 class_id 设为 NULL
ON UPDATE CASCADE -- 班级 id 更新时,学生 class_id 同步更新
);
-- 插入不存在的班级 → 外键约束失败
INSERT INTO student VALUES (1, '张三', 999);外键级联选项:
| 选项 | ON DELETE 行为 | ON UPDATE 行为 |
|---|---|---|
| CASCADE | 级联删除关联行 | 级联更新关联行 |
| SET NULL | 将外键设为 NULL | 将外键设为 NULL |
| RESTRICT | 拒绝删除(默认) | 拒绝更新 |
| NO ACTION | 同 RESTRICT | 同 RESTRICT |
三、隔离性(Isolation)的底层实现
隔离性通过 MVCC + 锁 共同实现。MVCC 在第二部分详述,这里重点讲锁机制。
3.1 InnoDB 锁分类
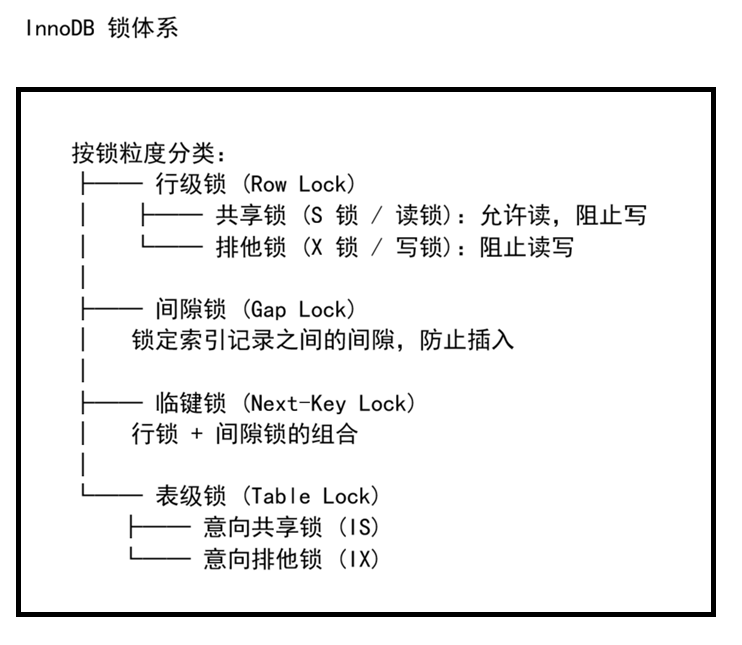
3.2 锁的兼容矩阵
| 请求 / 持有 | S 锁 | X 锁 | IS 锁 | IX 锁 |
|---|---|---|---|---|
| S 锁 | ✅ | ❌ | ✅ | ❌ |
| X 锁 | ❌ | ❌ | ❌ | ❌ |
| IS 锁 | ✅ | ❌ | ✅ | ✅ |
| IX 锁 | ❌ | ❌ | ✅ | ✅ |
3.3 手动加锁示例
-- 共享锁(读锁)
SELECT * FROM student WHERE id = 1 LOCK IN SHARE MODE;
-- 或
SELECT * FROM student WHERE id = 1 FOR SHARE; -- MySQL 8.0+
-- 排他锁(写锁)
SELECT * FROM student WHERE id = 1 FOR UPDATE;
-- 注意:必须在事务中使用
BEGIN;
SELECT * FROM student WHERE id = 1 FOR UPDATE;
-- 其他事务无法修改 id=1 的行
COMMIT;3.4 死锁演示

避免死锁的策略:
-
按相同的顺序访问资源(如都按 id 从小到大加锁)
-
减小事务粒度(尽快提交)
-
使用较低的隔离级别
四、持久性(Durability)的底层实现
4.1 Redo Log 详解

4.2 WAL 技术
MySQL 使用 WAL(Write-Ahead Logging,预写日志) 技术:
-
修改数据前,先写 Redo Log
-
Redo Log 持久化后,再慢慢修改数据文件
-
好处:Redo Log 是顺序写(快),数据文件是随机写(慢)

4.3 Redo Log 配置
-- 查看 Redo Log 配置
SHOW VARIABLES LIKE 'innodb_log_file_size';
SHOW VARIABLES LIKE 'innodb_log_files_in_group';-- Redo Log 总大小 = innodb_log_file_size × innodb_log_files_in_group
-- 默认:48MB × 2 = 96MB-- 刷新策略(控制持久性强度)
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
innodb_flush_log_at_trx_commit 参数:
| 值 | 行为 | 持久性 | 性能 |
|---|---|---|---|
| 0 | 每秒刷一次 Redo Log | 低 | 最高 |
| 1 | 每次提交都刷盘(默认) | 最高 | 中等 |
| 2 | 每次提交写 OS 缓存,每秒刷盘 | 中等 | 较高 |
第二部分:MVCC 与隔离级别深度解析
一、MVCC 完整原理
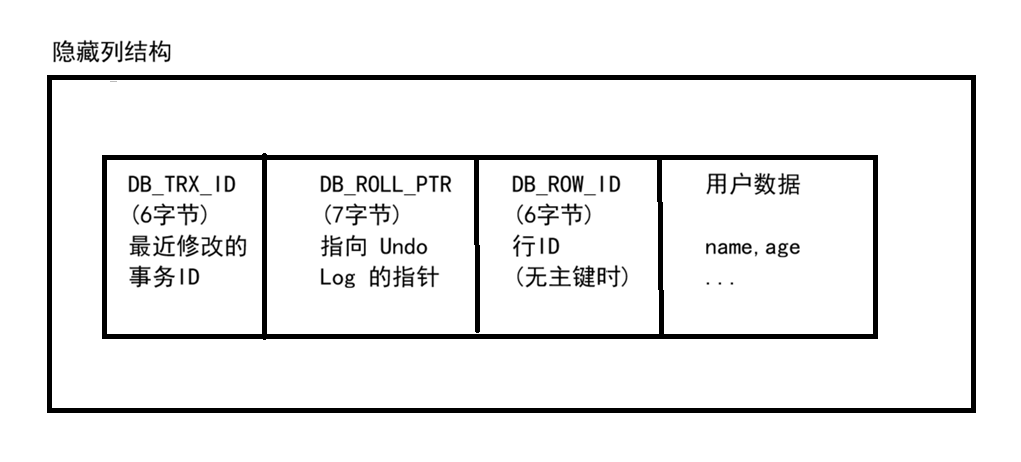
1.1 隐藏列
InnoDB 的每一行数据都有三个隐藏列:
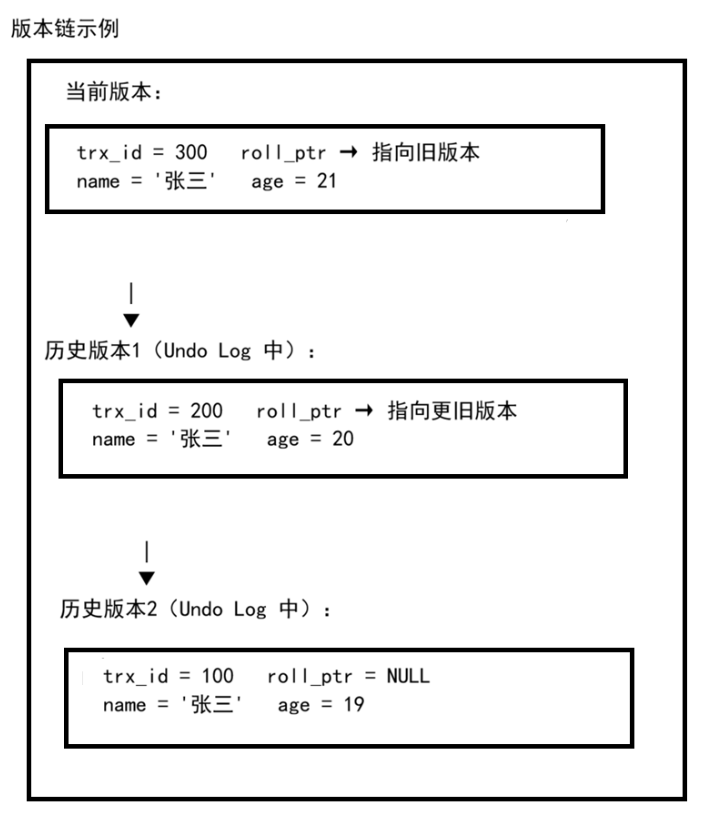
1.2 版本链
每次修改数据时,InnoDB 会创建新的数据版本,并通过 DB_ROLL_PTR 连接成版本链:
1.3 ReadView 判断可见性
ReadView 是事务进行快照读时产生的读视图,包含以下信息:

1.4 两种隔离级别的 ReadView 生成策略

二、隔离级别完整演示
2.1 准备环境
-- 使用两个终端窗口(会话A、会话B)
-- 会话A
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
USE testdb;
SELECT * FROM student;
-- 假设初始数据:
-- +----+--------+-----+
-- | id | name | age |
-- +----+--------+-----+
-- | 1 | 张三 | 20 |
-- | 2 | 李四 | 22 |
-- +----+--------+-----+2.2 REPEATABLE READ 完整演示

2.3 READ COMMITTED 完整演示

三、当前读 vs 快照读
-- 快照读(使用 MVCC,不加锁)
SELECT * FROM student WHERE id = 1;
-- 当前读(加锁,读取最新版本)
SELECT * FROM student WHERE id = 1 FOR UPDATE;
SELECT * FROM student WHERE id = 1 LOCK IN SHARE MODE;
-- DML 语句都是当前读
UPDATE student SET age = 21 WHERE id = 1; -- 先读取最新版本再加锁
DELETE FROM student WHERE id = 1; -- 先读取最新版本再加锁重要:REPEATABLE READ 下的 FOR UPDATE 会使用间隙锁来防止幻读,这就是 InnoDB 能解决幻读的关键。
第三部分:索引深度详解
一、B+树的完整结构
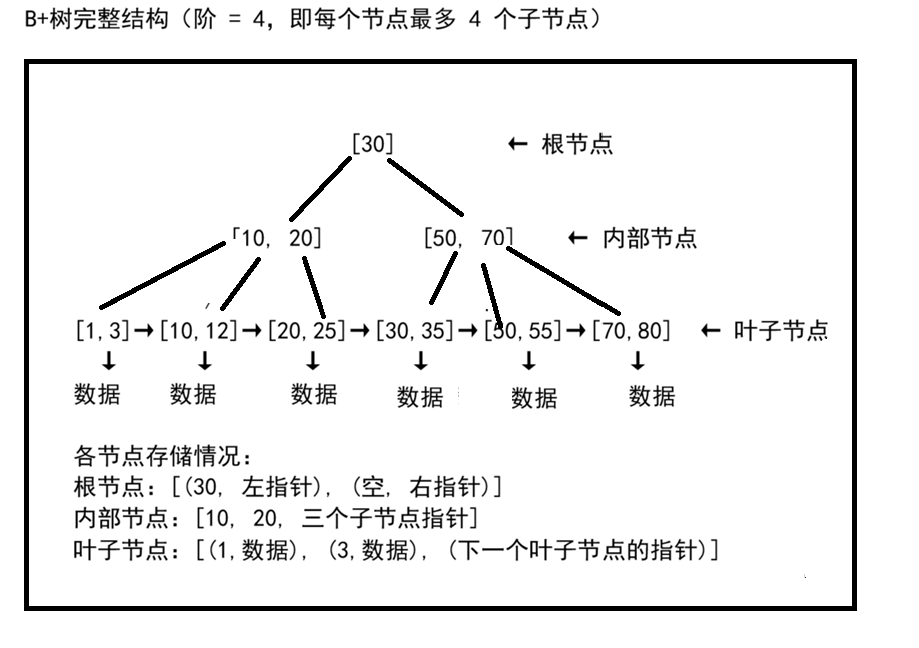
1.1 B+树节点存储计算

1.2 为什么不用 B 树或二叉树
| 数据结构 | 特点 | 不适合的原因 |
|---|---|---|
| 二叉树 | 每个节点一个键 | 高度太大,磁盘 I/O 多 |
| B 树 | 数据存在内部节点 | 内部节点数据多,指针少,树更高 |
| B+树 | 数据只存叶子节点 | ✅ 内部节点只存键,子树多,树更矮 |
| 哈希 | O(1) 等值查找 | ❌ 不支持范围查询 |
二、聚簇索引的物理存储
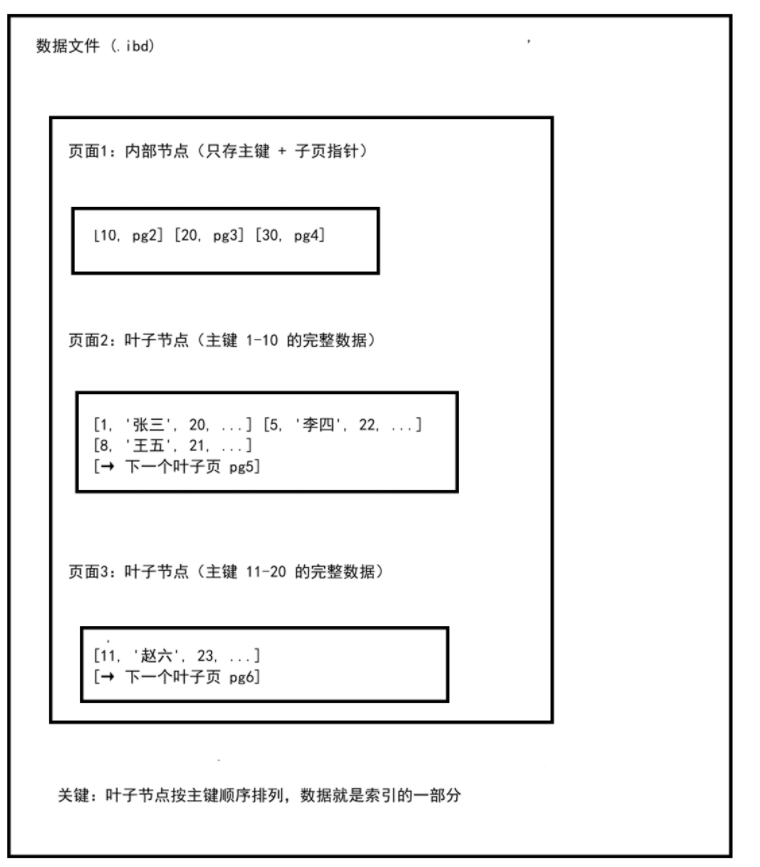
三、辅助索引与回表
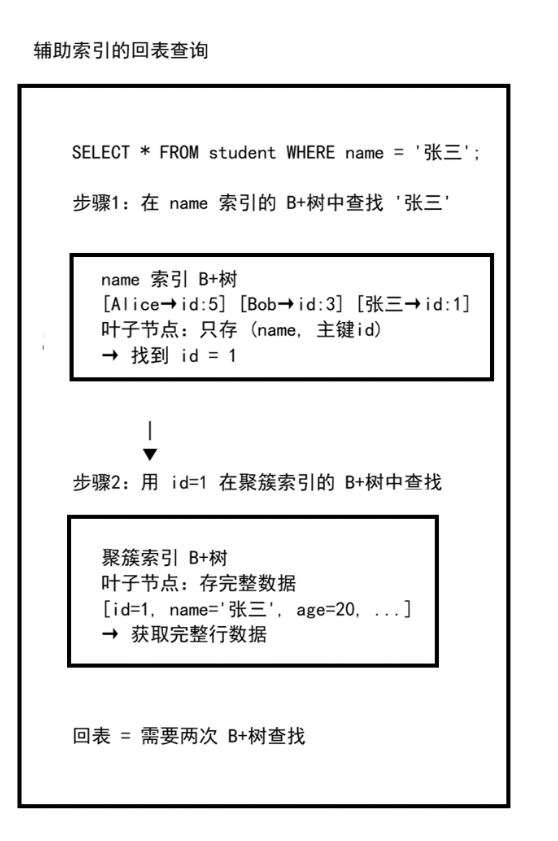
四、覆盖索引详解
-- 创建联合索引
CREATE INDEX idx_name_age ON student (name, age);
-- 覆盖索引查询(只访问索引树,不回表)
SELECT name, age FROM student WHERE name = '张三';
-- 验证是否使用覆盖索引
EXPLAIN SELECT name, age FROM student WHERE name = '张三';
-- Extra: Using index ← 表示覆盖索引,不需要回表五、索引优化实战
5.1 EXPLAIN 输出详解
EXPLAIN SELECT * FROM student WHERE name = '张三' AND age > 20;
 type 字段从优到劣:
type 字段从优到劣:
system > const > eq_ref > ref > range > index > ALL
system :表只有一行(系统表)
const :主键或唯一索引等值查询
eq_ref :关联查询时,使用主键或唯一索引关联
ref :普通索引等值查询
range :索引范围查询 (BETWEEN, >, <, IN)
index :全索引扫描
ALL :全表扫描(最差!)
5.2 常见索引失效情况
-- 1. 在索引列上使用函数
WHERE YEAR(create_time) = 2024; -- 失效
WHERE create_time >= '2024-01-01'; -- 有效
-- 2. 隐式类型转换
WHERE phone = 13800138000; -- phone 是 VARCHAR,失效
WHERE phone = '13800138000'; -- 有效
-- 3. 前导模糊查询
WHERE name LIKE '%张三'; -- 失效
WHERE name LIKE '张三%'; -- 有效
-- 4. OR 连接(部分情况)
WHERE id = 1 OR name = '张三'; -- name 索引可能失效
-- 改成:
WHERE id = 1
UNION ALL
SELECT * FROM t WHERE name = '张三' AND id != 1;
-- 5. 联合索引不满足最左前缀
INDEX idx_a_b_c (a, b, c);
WHERE b = 1 AND c = 2; -- 失效(跳过 a)
WHERE a = 1 AND c = 2; -- 部分有效(只用 a)第四部分:视图深度详解
一、视图的执行原理

二、视图的检查选项
-- WITH CHECK OPTION:防止通过视图插入/更新不符合视图条件的数据
CREATE VIEW v_adult AS
SELECT id, name, age FROM student WHERE age >= 18
WITH CHECK OPTION;
-- 可以(age=20 满足 age>=18)
INSERT INTO v_adult VALUES (10, '测试1', 20);
-- 报错(age=15 不满足 age>=18)
INSERT INTO v_adult VALUES (11, '测试2', 15);
-- ERROR 1369: CHECK OPTION failed三种检查选项:
| 选项 | 行为 |
|---|---|
| 无 CHECK OPTION | 不检查,可能插入后从视图中"消失" |
| WITH CHECK OPTION | 检查当前视图的条件 |
| WITH CASCADED CHECK OPTION | 递归检查所有基视图的条件 |
| WITH LOCAL CHECK OPTION | 只检查当前视图的条件 |
三、物化视图
MySQL 本身不直接支持物化视图,但可以用触发器 + 表来模拟:
-- 创建"物化视图"表
CREATE TABLE mv_student_stats (
class_id INT PRIMARY KEY,
student_count INT,
avg_age DECIMAL(5,2)
);
-- 创建触发器自动更新
DELIMITER $$
CREATE TRIGGER update_mv AFTER INSERT ON student
FOR EACH ROW
BEGIN
INSERT INTO mv_student_stats (class_id, student_count, avg_age)
VALUES (NEW.class_id, 1, NEW.age)
ON DUPLICATE KEY UPDATE
student_count = student_count + 1,
avg_age = (avg_age * (student_count - 1) + NEW.age) / student_count;
END$$
DELIMITER ;第五部分:面试题整合
ACID 相关
-
Q:MySQL 如何保证原子性?
A:通过 Undo Log。修改数据前先将旧值写入 Undo Log,ROLLBACK 时根据 Undo Log 恢复。 -
Q:MySQL 如何保证持久性?
A:通过 Redo Log(WAL 技术)。COMMIT 时先将修改写入 Redo Log 并持久化,即使崩溃也能恢复。 -
Q:Redo Log 和 Undo Log 的区别?
A:Redo Log 是物理日志,用于崩溃恢复;Undo Log 是逻辑日志,用于回滚和 MVCC。
隔离级别相关
-
Q:MySQL 默认隔离级别是什么?解决了什么问题?
A:REPEATABLE READ。解决了脏读和不可重复读,InnoDB 通过间隙锁还解决了幻读。 -
Q:MVCC 实现原理?
A:每行有 DB_TRX_ID 和 DB_ROLL_PTR 两个隐藏列,修改时形成版本链。ReadView 在查询时决定哪些版本可见。 -
Q:如何选择隔离级别?
A:一般用默认的 REPEATABLE READ;对一致性要求极高的金融系统用 SERIALIZABLE;追求性能的日志系统可用 READ COMMITTED。
索引相关
-
Q:为什么用 B+树而不是 B 树?
A:B+树数据只存叶子节点,内部节点可存更多键值,树更矮;叶子节点形成有序链表,支持高效范围查询。 -
Q:什么是回表?如何避免?
A:辅助索引找到主键后,再到聚簇索引找完整数据。使用覆盖索引可避免回表。 -
Q:联合索引的最左前缀原则是什么?
A:联合索引先按第一列排序,再按第二列,所以查询时必须从第一列开始匹配才能使用索引。
视图相关
-
Q:视图存储数据吗?
A:不存储。视图只是保存的 SELECT 语句,每次查询视图时重新执行。 -
Q:什么视图不可更新?
A:包含聚合函数、DISTINCT、GROUP BY、UNION、子查询、多表 JOIN 的视图。
总结
本文对 MySQL 的四个核心特性进行了深度拆解:
| 主题 | 核心原理 | 关键机制 |
|---|---|---|
| ACID | 事务四大特性 | Undo Log(原子性)+ Redo Log(持久性)+ MVCC/锁(隔离性) |
| 隔离级别 | 并发事务的可见性规则 | MVCC + ReadView + 间隙锁 |
| 索引 | 加速数据查找 | B+树 + 聚簇/辅助索引 + 覆盖索引 + 最左前缀 |
| 视图 | 虚拟表,简化查询 | 保存 SQL 语句 + CHECK OPTION |
每个特性都建议在终端中动手验证一遍,才能真正理解其原理。

纵情码海钱塘涌,杭州开发者创新动! 属于杭州的开发者社区!致力于为杭州地区的开发者提供学习、合作和成长的机会;同时也为企业交流招聘提供舞台!
更多推荐

 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)