
Python从入门到实践练习题库及答案解析(二)
列表
发送offer

offer_list=["Allen","Tom"]
for i in offer_list:
print(f"{i}, you have passed our interview and will soon become a member of our company.")
offer_list[1]="Andy"
for i in offer_list:
print(f'{i}, welcome to join us!')
逐行/分块白话拆解 + 运行结果
offer_list=[“Allen”,“Tom”]:初始录用名单。
第一次循环:遍历名单,每个人收到第一条消息。
offer_list[1]=“Andy”:关键操作!将索引 1(第二个元素,即 “Tom”)替换为 “Andy”。此时列表变成 [“Allen”, “Andy”]。
第二次循环:遍历修改后的名单,每个人收到第二条消息。
增加派对名单

a = input().split()
a.append('Allen')
print(a)
精华知识点总结
• split() 默认按空格/制表符分割,返回字符串列表。
• append() 是在列表末尾追加一个元素(把 ‘Allen’ 当成一个整体塞进去)。
• 致命陷阱:append() 修改原列表,返回 None,千万别写成 a = a.append(‘Allen’)(否则 a 变成 None)。
增加派对名单(二)

a = input().split()
a.insert(0,"Allen")
print(a)
逐行/分块白话拆解
a = input().split():读取输入(如 “Tom Jerry”),分割成列表 [‘Tom’, ‘Jerry’]。
a.insert(0, “Allen”):在索引 0(即第一个位置)插入 ‘Allen’。原索引 0 及之后的元素全部集体后移一位。列表变为 [‘Allen’, ‘Tom’, ‘Jerry’]。
print(a):输出 [‘Allen’, ‘Tom’, ‘Jerry’]。
精华知识点总结
• insert(索引, 元素):在指定索引位置插入元素,原位置及后面的元素全部右移。
• insert(0, x) 专门用于在头部插入(即插队到第一名)。
• 与 append 的对比:append 尾部添加(快),insert(0) 头部插入(慢)。
• 如果索引超出列表长度(如 insert(99, “x”)),会自动追加到末尾,等价于 append,不会报错。
删除简历

a = input().split()
a.pop(0)
print(a)
-
一句话概括
读取一行空格分隔的字符串,分割成列表后,删除并丢弃列表中的第一个元素(索引 0),然后打印剩余列表。 -
逐行/分块白话拆解
a = input().split():输入 “A B C” → 得到列表 [‘A’, ‘B’, ‘C’]。
a.pop(0):删除索引为 0 的元素(即 ‘A’),并返回被删除的元素 ‘A’(但此处没有变量接收它,相当于直接丢弃)。列表原地变为 [‘B’, ‘C’]。
print(a):输出修改后的列表 [‘B’, ‘C’]。 -
精华知识点总结
• pop(0) 删除列表的第一个元素并返回它(可接可不接返回值)。
• 不传参数时 pop() 默认删除最后一个元素(这是最常用的姿势)。
• 与 insert(0) 相反:insert 是左移(腾出位置),pop(0) 是右移(填补空缺)。
• pop(0) 是有返回值的,这点和 del a[0](无返回值)完全不同。
删除好友

a = input().split()
b = input()
a.remove(b)
print(a)
逐行/分块白话拆解
a = input().split():输入 “A B C” → 列表 [‘A’, ‘B’, ‘C’]。
b = input():再输入一行,例如输入 “B” → 字符串 ‘B’(注意:这里没有 .split(),是原始的完整字符串)。
a.remove(b):在列表 a 中从左到右查找,找到第一个值等于 ‘B’ 的元素,并将其删除。列表变为 [‘A’, ‘C’]。
print(a):输出 [‘A’, ‘C’]。
精华知识点总结
• remove(值) 按值删除列表中第一个匹配项,不是按索引。
• 若列表中不存在该值,直接报 ValueError(程序崩溃)。
• 只删第一个匹配项,如果有多个相同值,后面的保留不动。
• 与 pop(0) 的区别:pop 按位置删并返回值;remove 按值删且无返回值。
淘汰排名最后的学生
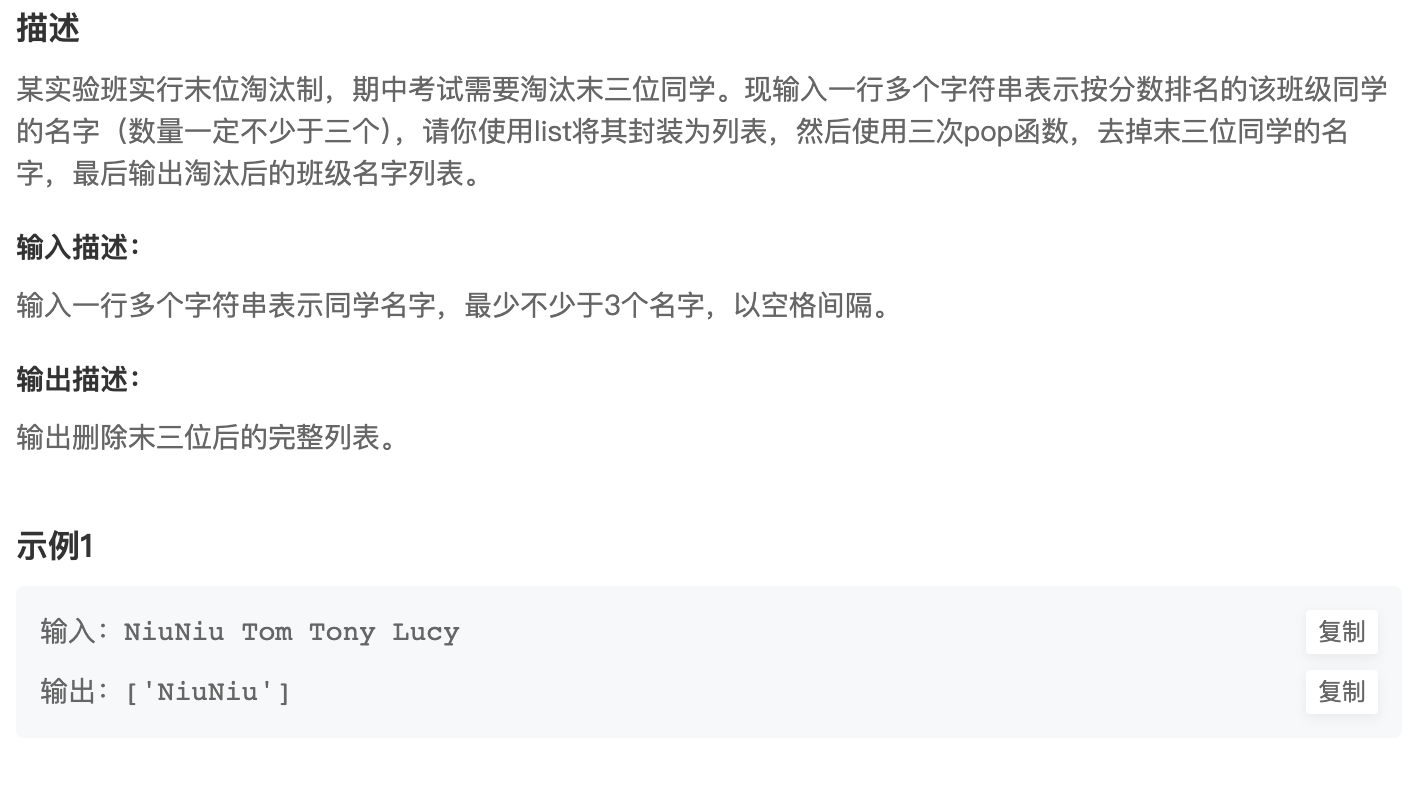
list = input().split()
for i in range(3):
list.pop()
print(list)
有序的列表

my_list = ["P","y","t","h","o","n"]
print(sorted(my_list))
print(my_list)
my_list.sort(reverse=True)
print(my_list)
1. 一句话人话概括
演示列表的两种排序方式:sorted() 不修改原列表并返回新列表;sort() 原地修改列表并返回 None。通过两次打印对比,清晰展示两者的差异。
2. 逐行/分块白话拆解 + 运行结果
my_list = ["P","y","t","h","o","n"]:定义一个字符串列表。print(sorted(my_list)):sorted()是内置函数,对列表进行升序排序,返回一个新列表。- 排序规则:按 ASCII 码/Unicode 码点,大写字母
"P"(ASCII 80)排在小写字母(ASCII 97+)之前。 - 输出:
['P', 'h', 'n', 'o', 't', 'y'](注意"P"被排到了最前面)。
print(my_list):原列表未被修改,仍为["P","y","t","h","o","n"]。my_list.sort(reverse=True):sort()是列表的方法,原地修改列表。reverse=True表示降序排列。- 执行后
my_list变为['y', 't', 'o', 'n', 'h', 'P'](因为"P"最小,排最后)。
print(my_list):输出修改后的列表['y', 't', 'o', 'n', 'h', 'P']。
完整输出结果:
['P', 'h', 'n', 'o', 't', 'y']
['P', 'y', 't', 'h', 'o', 'n']
['y', 't', 'o', 'n', 'h', 'P']
3. 精华知识点总结
• sorted(列表):不修改原列表,返回一个新的已排序列表。
• 列表.sort():直接修改原列表,返回 None,不生成新列表。
• reverse=True 是两者共有的参数,表示降序(从大到小)。
• 字符串排序默认按字母顺序(ASCII/Unicode 码点),大写字母排在小写字母前面(因为大写 ASCII 码更小)。
- 性能差异:
sort()原地修改,不复制数据,更省内存,适合大数据量排序。sorted()会创建新列表,多占一份内存,但如果需要保留原数据,必须用sorted()。
- 类型限制:列表内元素必须可比较。如果混入数字和字符串(如
[1, "a"]),两者都无法排序,会报TypeError。
反转列表

num = [3, 5, 9, 0, 1, 9, 0, 3]
num.reverse()
print(num)
• reverse() 是列表的方法,直接修改原列表,不返回新列表(返回 None)。
• 反转是 “前后对称交换”:索引 0 和索引 -1 互换,索引 1 和索引 -2 互换,依此类推。
• 如果列表为空或只有 1 个元素,调用 reverse() 不会报错,也不做任何改变。
• 与 sorted() 的对比:reverse() 是“倒过来”,sorted() 是“按大小排”。
朋友们的喜好

friends = []
name = ['Niumei', 'YOLO', 'Niu Ke Le', 'Mona']
food = ['pizza', 'fish', 'potato', 'beef']
number = [3, 6, 0, 3]
friends.append(name)
friends.append(food)
friends.append(number)
print(friends)
逐行/分块白话拆解 + 运行结果
friends = []:一个空瓶子。
name = [‘Niumei’, ‘YOLO’, ‘Niu Ke Le’, ‘Mona’]:第一个箱子,装着 4 个名字。
food = [‘pizza’, ‘fish’, ‘potato’, ‘beef’]:第二个箱子,装着 4 种食物。
number = [3, 6, 0, 3]:第三个箱子,装着 4 个数字。
friends.append(name):把第一个箱子整个塞进瓶子。现在瓶子里有 1 个东西(这个大箱子)。
friends.append(food):把第二个箱子整个塞进去,瓶子有 2 个东西。
friends.append(number):塞第三个,瓶子有 3 个东西。
print(friends):打印这个瓶子里的内容。
精华知识点总结
• append(列表) 是“整体追加”,不拆开里面的元素,列表长度只 +1。
• 最终 friends 的长度是 3(不是 12),每个元素都是一个子列表。
• 取第二个食物的写法:friends[1][2] → ‘potato’(先取第 2 个子列表,再取该列表的第 3 个元素)。
• 对比 extend:friends.extend(name) 会把 name 里的 4 个名字全部拆开,一个一个追加进 friends,长度会变成 4。
密码游戏
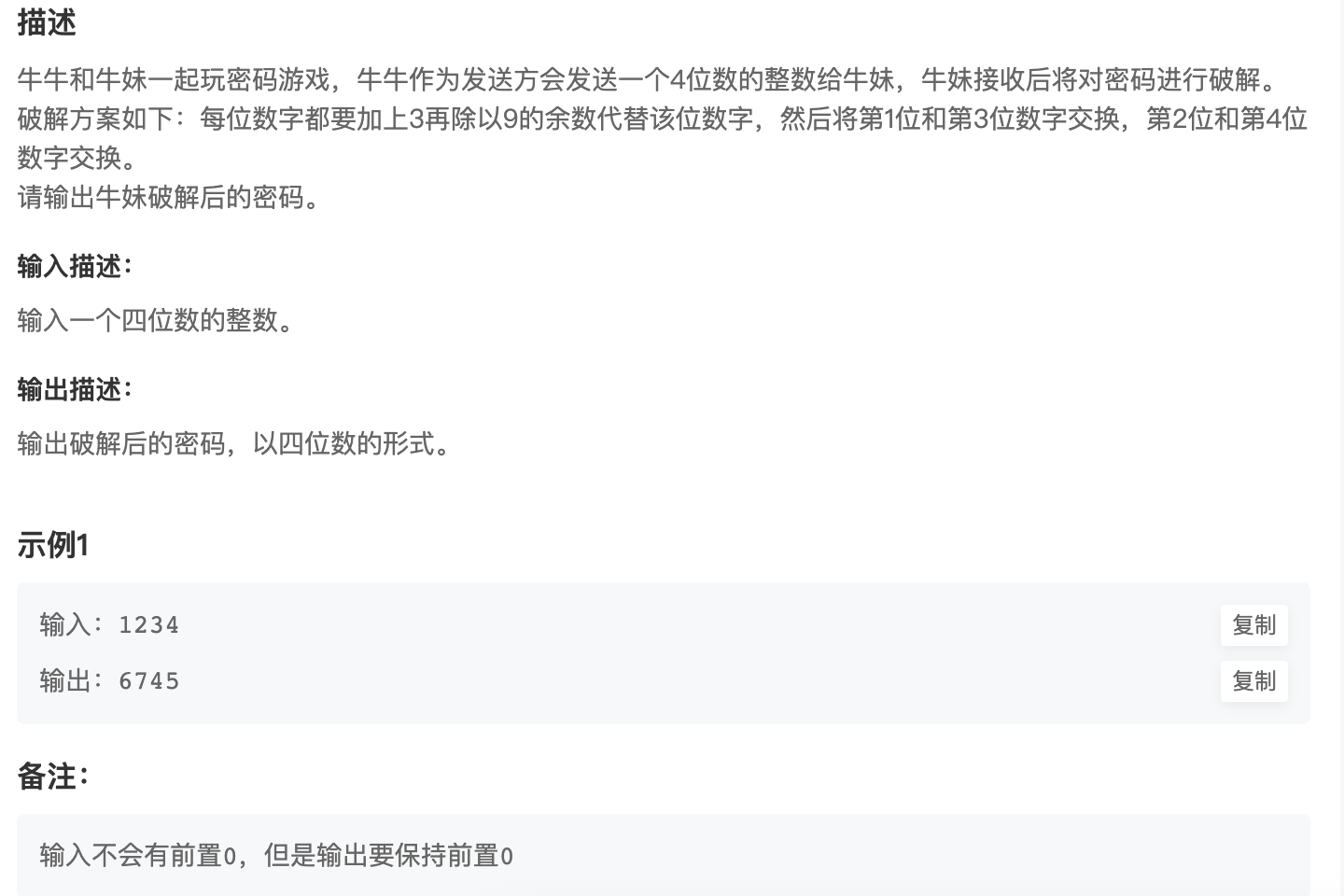
number = input()
result = ""
for i in number:
result = result + str((int(i) + 3) % 9)
# 循环结束后,再统一置换
result = result[2] + result[3] + result[0] + result[1]
print(result)
精华知识点总结
• 字符串拼接用 +,但频繁拼接效率低,大数据量推荐用 join。
• 循环内不要做依赖结果长度的操作(如索引访问),除非你确定长度足够。
• str((int(i)+3)%9) 实现了“每位加3,超过9则取个位”的变换(0-8循环)。
• 固定位置的“换位”操作应在所有字符拼接完成后再统一执行,不要放在循环内部。
用列表实现栈

stack = [1, 2, 3, 4, 5]
number =int(input())
stack.pop()
print(stack)
stack.pop()
print(stack)
stack.append(number)
print(stack)
精华知识点总结
• pop() 无参数时,默认删除并返回列表末尾的元素(模拟栈的出栈)。
• append(元素) 在列表末尾添加元素(模拟栈的入栈)。
• 列表的末尾操作(append 和 pop())时间复杂度都是 O(1),非常高效。
• 如果列表为空时调用 pop(),会直接报 IndexError。
用列表实现队列

queue = [1, 2, 3, 4, 5]
number = int(input())
queue.pop(0)
print(queue)
queue.pop(0)
print(queue)
queue.append(number)
print(queue)
• pop(0) 删除并返回列表第一个元素(模拟队列的“出队”)。
• append() 在列表末尾添加元素(模拟队列的“入队”)。
• 组合使用 pop(0) + append 就是队列(FIFO:先进先出)的经典操作。
• 与上一题对比:上一题 pop()(无参)是栈(LIFO:后进先出),本题 pop(0) 是队列(FIFO)。
量化成数字(让你震惊)
O(1) 操作(删尾部):处理 100 万个元素,耗时 0.000001 秒(极快)。
O(n) 操作(删头部):处理 100 万个元素,耗时 0.05 秒(看着不多,但在大厂高并发服务器上,这个操作重复 1000 次,就是 50 秒,直接把服务拖死)。
大厂面试潜台词:面试官问复杂度,就是在看你能不能预料到“当用户量暴增时,你的代码会不会崩”。只要你写出 pop(0) 或 insert(0, x),面试官立刻会问:“数据量大了怎么办?” 如果你答不出 deque(双端队列),这一题就挂了。
团队分组

group_list = ['Tom', 'Allen', 'Jane', 'William', 'Tony']
print(group_list[0:2])
print(group_list[1:4])
print(group_list[3:])
精华知识点总结
• 切片 [start:end] 遵循 “左闭右开” 规则:包含 start 索引,不包含 end 索引。
• 省略 start(如 [:2])表示从头开始;省略 end(如 [2:])表示取到末尾。
• 切片不会修改原列表,会返回一个新列表(原列表保持不变)。
• 索引可以写负数:[-2:] 表示取最后两个元素。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)